V2EX 热门帖子
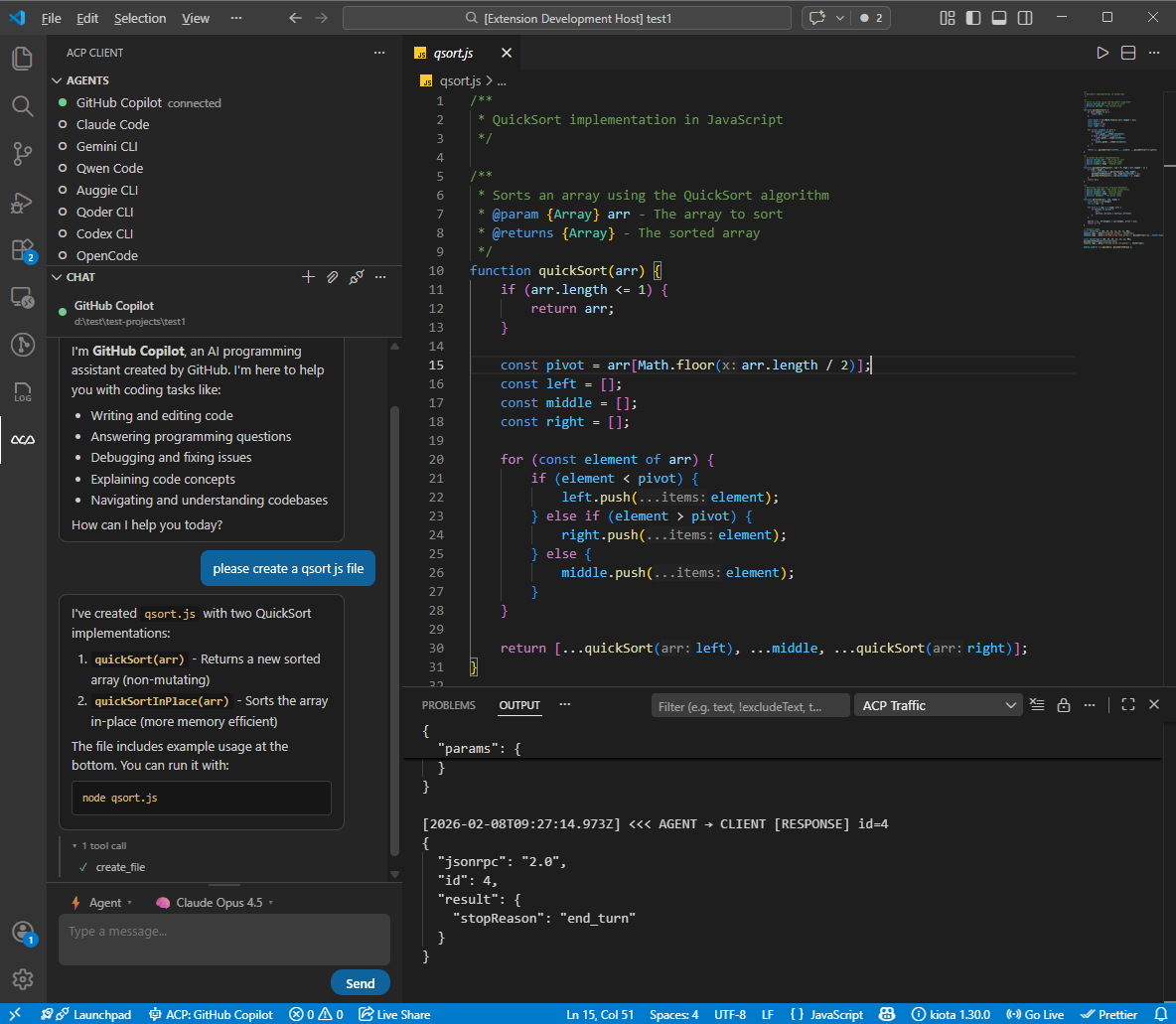
1. VS Code ACP Client 扩展:连上 Claude, Gemini, Codex, OpenCode, Qwen Code 等 AI Agent
前段时间,我用 Tauri 写了个跨平台的 ACP UI ,支持 Windows ,macOS (ARM/Intel) 和 Linux (x64/ARM64):
https://github.com/formulahendry/acp-ui
根据 ACP 的协议,推荐 ACP Client 最好要实现 Terminals 和 File System 的 API 。
我就在想,Terminals 和 File System 肯定是 VS Code 的强项啊!而且 VS Code 也 expose 了相关的 extension API 。特别是 Terminals API ,目前 ACP UI 还没支持,如果能站在巨人的肩膀上,那就很香啦~
于是,这周末,我又写了 VS Code 的 ACP Client extension:
https://marketplace.visualstudio.com/items?itemName=formulahendry.acp-client
基本的核心功能都有:
- Multi-Agent Support
- Single-Agent Focus
- Interactive Chat
- Mode & Model Picker
- File System Integration
- Terminal Execution
- Permission Management
- Protocol Traffic Logging
默认支持连接 GitHub Copilot 、Claude Code 、Gemini CLI 、Qwen Code 、OpenCode 、Codex CLI 、Qoder CLI 和 Auggie CLI 。当然也可以另外配置。
代码也完全开源:
https://github.com/formulahendry/vscode-acp
欢迎围观交流~
作者: formulahendry | 发布时间: 2026-02-09 00:13
2. 第五次重装 hermes, 有些经验希望给准备用的人参考一下.
4 月初的时候我搞了个小龙虾, 结果这家伙经常死机, 用起来很累.
后来 hermes 出来的时候,我开始试用, 感觉比龙虾好用好多, 最起码看起来算个能干活的, 中间几次版本迭代更新,以及试用各种本地模型, 来回折腾重装了很多次, 最终决定还是长期使用它, 有了这个定论之后, 开始大规模的下载大模型到本地电脑一个专门的文件夹, 然后复制到 omlx 的 models 文件下并随时启用测试.
另外还安装感觉目前最好用的 webui: https://github.com/EKKOLearnAI/hermes-web-ui/blob/main/README_zh.md
以及这几天刚出来的自我进化 skill: https://github.com/NousResearch/hermes-agent-self-evolution
同时参考了这个:https://github.com/0xNyk/awesome-hermes-agent 以及 x 上几个博主, 跟进下最新进展以便随时跟进.
目前 32G 内存 air, 我试过最大可以勉强跑 qwen3.6-35B 的 4bit 量化版本,还有 Gemma4-26B,输出速度很慢但我经常在睡觉前扔给它一个任务, 睡醒了基本上都可以执行完毕, 虽然不随心应手, 但勉强能用.
为了不让 Mac 崩溃, 我还让 Hermas 设置了一个自动监控任务, 一旦内存占用超过危险的可能导致系统崩溃并重启的 92%,立刻降低推理和演算速度, 确保系统不崩溃, 这个任务设置后,效果非常明显.
我用了一个风扇对着 Macbook air 吹, 降温效果明显, 在上述自动内存监控任务启动后, 高温的机会也少了好多.
感觉瓶颈最终还是硬件, 在 M5 Mini Mac 没上市前, 还是先保持跟进吧.
作者: Hermitist | 发布时间: 2026-04-28 21:01
3. Xiaomi MiMo Token 激励计划
邀请你参加 Xiaomi MiMo Orbit 百万亿 Token 创造者激励计划,100T Credits 面向全球用户限时发放中… https://100t.xiaomimimo.com/
创造者百万亿 Token 激励计划
Xiaomi MiMo 将面向全球 AI 用户进行免费 Token 发放,我们将在 30 天内发放总计 100 万亿( 100T ) Token 权益,赠完即止。
活动时间:北京时间 2026 年 4 月 28 日 00:00 至 5 月 28 日 00:00
参与地址:100t.xiaomimimo.com
作者: leave8080 | 发布时间: 2026-04-28 01:44
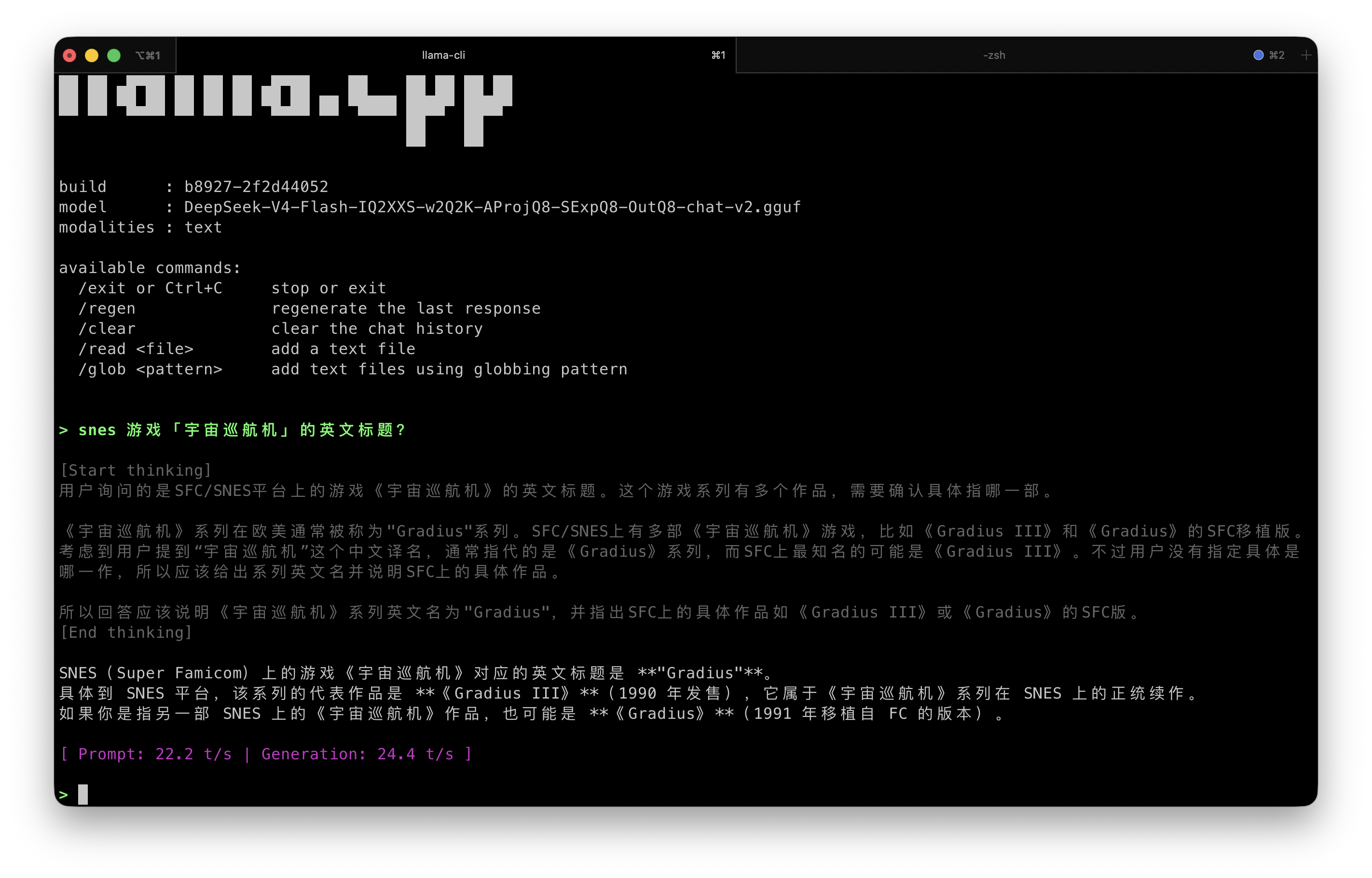
4. 用 antirez 的 llama.cpp fork 把 DeepSeek v4 Flash 在本地跑起来了
作者: Livid | 发布时间: 2026-04-27 17:53
5. 既然现在 ai coding 都改成按量计费了,用 opencode+apikey 是否更省钱?
如题,有没有大佬研究过。
cursor / windsurf / copilot 都是按量计费了,价格上还有优势吗?
用 opencode 至少省去了一个 agent 工具的费用,理论上是不是更便宜点
作者: guichen | 发布时间: 2026-04-28 12:26
6. 兄弟们平常都用什么浏览器?
Chrome 这几天突然变得好卡,不知道咋回事
作者: Lantang | 发布时间: 2026-04-28 01:44
7. 能一起给本地部署的开源模型做个适配的 coding agent 吗?我憋了口气
我做了一个专门为本地开源模型优化的 Coding Agent ,希望更多华人开发者一起来搞
本贴发布的目的不是推产品,不是炫技,而是想扬眉吐气——和华人开发者一起,和开源模型本地部署开发者一起,做一件我们自己的事。
一、我遇到了什么问题
去年开始用本地模型做编程辅助。原因很简单:公司代码不能传到海外服务器,Claude Code 和 Cursor 走不通。
但更大的问题是:中国开发者根本没有一个好用的本地 coding agent 平台。
CC 需要翻墙,还要订阅。Cursor 同样。Codex 刚出来也是海外服务。Hermes 这类开源工具不支持 Windows 原生运行,要装 WSL2 ,劝退了大多数国内开发者。最后大家的选择是:要么翻墙凑合用,要么忍着不用。
这是一个真实存在的空缺,没有人填。
本地跑 qwen3:8b ,然后发现问题一个接一个:
🔴 无限循环,像卡带一样
这是本地小模型最让人抓狂的问题。遇到它不会处理的场景,它不会说”我不知道”,而是开始重复——同一句话说三遍,同一个错误的修改建议循环出现,同一段代码反复生成。整个任务卡死,只能手动强制退出。这不是偶发现象,是小模型在推理能力不足时的典型崩溃模式。
🔴 修 bug 反复踩同一个坑
让它修一个函数,第一次失败,第二次用完全一样的方式再试,第三次依然。三次机会全浪费在同一个错误上,什么都没推进。
🔴 模型能力本身就弱于 API 模型
这是无法回避的现实。8B 、14B 的参数量,推理能力和 Claude Opus 、GPT-4 差距明显。让一个 8B 模型扛下一个复杂任务的全部推理,成功率很低,这不是哪个工具的问题,是模型本身的边界。
🔴 找不到要改的文件
项目大了之后,模型根本不知道要改哪个文件。让它找 bug ,它要么猜错,要么说”我需要看更多代码”,然后把整个项目塞进 context ,然后 context 又爆了。
🔴 对话几轮就开始遗忘
8B 模型 context 窗口只有 8K ,对话多了就满了,模型开始给出驴唇不对马嘴的回答。
这些问题叠在一起,用本地模型做开发辅助的体验极差。
所以我想自己做一个产品来跑。有人就会说:为什么不直接用 ollama + cc ?还友情指导我命令。
哎。
大厂的产品只会为它的商业模式服务。ollama 放弃了参数微调来换取稳定,lm 让开发者纠结什么是最优,CC/Codex/Cursor 都是卖 token ,没有人会真的认真想本地部署缺什么,需要优化什么,记忆怎么优化,上下文怎么压缩,小参数怎么辅助。
但我人微言轻,所以我做了个 MVP 想抛砖引玉。我们可以一起把要优化的都优化了,打造我们自己的产品。
有人也说,我能力不够。
那我的思路是:不够就做整合,够了就做突破。
所以我做了 KWCode ,不是为了商业化,MIT 任何人都能拿走,只希望哪个感兴趣的大神,愿意和我或者和所有开发者一起把它实现并开源,给所有被本地部署膈应的宝子们。
二、我用了哪些思路
思路一:MoE 架构——让 LLM 只做它擅长的那一步
这是 KWCode 最核心的设计决策,也是解决上面所有问题的根本思路。
传统 coding agent 的架构是:一个 LLM 扛全部 ——理解需求、定位代码、生成修改、验证结果,全让同一个模型做。强模型能扛,小模型扛不住,然后就开始循环、幻觉、乱说。
KWCode 用的是 MoE ( Mixture of Experts )架构 :把任务切碎,每个专家只做一件事,LLM 只负责 Gate 分类和内容生成,其他步骤能不调 LLM 就不调。
用户输入 └─► Gate ( LLM 做一次分类,判断任务类型) └─► Locator ( BM25 + 调用图,不调 LLM ,毫秒级定位文件和函数) └─► Generator ( LLM 只写需要修改的那几行代码) └─► Verifier (自动跑语法检查 + pytest ,不调 LLM ) └─► SearchAugmentor (两次失败后自动搜索)LLM 在这条流水线里的任务被压到了最小:Gate 做一次分类,Generator 生成几行代码。定位文件、验证结果这两件最耗推理能力的事,完全不让 LLM 做。
参考:Agentless 论文( ICSE 2025 )——确定性流水线在 SWE-bench 上同时达到最高通过率和最低成本,优于让 LLM 自主决策的复杂 agent 。原因很简单:每一步 scope 极小,小模型在小 scope 里表现稳定。
思路二:用调用图定位代码,不靠 LLM 猜
代码定位是小模型最容易失败的步骤,把它从 LLM 手里拿走,换成确定性算法。
CodeCompass ( arXiv:2602.20048 ,2026 年)做了 258 次实验,发现了一个关键结论:
真实项目里,很多 bug 的根因文件名和错误描述毫无关联,只能通过调用链追踪才能找到。对这类”隐藏依赖”任务,BM25 关键词搜索准确率只有 **76.2%**,而图遍历达到 **99.4%**,差了 23 个百分点。
KWCode 的两阶段检索:
- BM25 关键词召回 (毫秒级,不调 LLM ):从代码库所有函数/类中,快速召回 top-20 候选
- AST 调用图展开 (毫秒级,不调 LLM ):对每个候选函数,沿调用图向上向下各展开 2 跳,发现隐藏依赖
整个过程不调 LLM ,SQLite 持久化调用图,重启不重建。
技术栈:
tree-sitter+rank-bm25+SQLite。不需要 Neo4j ,不需要 embedding 模型,不需要额外 Docker 。
思路三:打破循环——失败时强制换策略
针对”反复踩同一个坑”和”无限循环”这两个问题:
反无限循环 :MAX_RETRIES 硬编码为 3 ,没有任何路径能绕过。同时检测连续两次生成完全相同的 patch ,直接跳过不重试,告诉用户”模型卡住了,建议缩小任务范围”。
反重复失败 :三次重试强制用三种不同的问题表述:
第几次 策略 第一次 正常描述需求 第二次 从错误信息出发:”直接修复这个报错,不要解释” 第三次 最小化修改:”只改这一个函数,其他代码一行不动” 第一次失败后先做 Reflection :让 LLM 一句话分析上次失败的原因,然后把这个分析注入下次的 prompt 。不是让模型自由发挥,是强制它先诊断再修。
思路四:专家飞轮,越用越懂你的项目
参考:EE-MCP ( NeurIPS 2025 )——从任务执行轨迹自动提取经验,验证可显著提升后续同类任务成功率。
KWCode 预置了 15 个专家( BugFix 、TestGen 、SpringBoot 、FastAPI 等),每个专家有独立的 system prompt 。
同类任务成功 5 次之后,飞轮自动分析轨迹,生成新专家,经过三道验证门 后投产:
- 回测门 :新专家成功率必须 ≥ 原流水线
- AB 测试门 :10 次真实对比,提升超过 10% 才投产
- 生命周期 :new → mature → declining → archived ,自动淘汰变差的专家
专家可以导出成
.kwx文件,kwcode expert install URL一行安装别人分享的专家。
思路五:模型能力自适应
CC 不需要考虑这个,因为它只用一个模型。KWCode 需要。
自动检测当前模型的参数量,然后应用不同策略:
模型规模 自动策略 < 10B ( qwen3:8b ) 强制计划确认 · 任务范围限 2 个文件 · 第 1 次失败触发搜索 10-30B ( qwen3:14b ) 可选计划 · 4 个文件范围 · 第 2 次失败触发搜索 30B ( qwen3:72b ) | 宽松策略 · 8 个文件 · 自动处理复杂任务
切换模型,策略自动切换。
三、现在做了什么
核心功能跑通了。282/282 单元测试通过,E2E 验收通过率 87%( 26/30 ,4 个失败是模型能力边界,不是框架问题)。
代码能力
- BM25 + AST 调用图两阶段定位,G3 隐藏依赖准确率 99.4%(论文验证)
- 三阶段重试 + Reflection ,不重复同样的错
- 专家飞轮三道门(轨迹 → 模式 → AB 测试 → 投产)
- 15 个预置专家(通用 + SpringBoot / MyBatis / FastAPI / UniApp 等)
- Office 文档生成( Excel / PPT / Word ,有样式不是白底)
工程能力
- KWCODE.md 项目规则文件,按任务类型分段注入,永远不忘
/plan计划模式 + 风险评估( High/Medium/Low ,基于历史失败记录)- Checkpoint 文件快照,失败一键还原
- 非代码文件读取( PDF / Word / Markdown ,BM25 段落匹配注入)
- 搜索增强( SearXNG 自部署 + DDG fallback ,四级内容提取)
体验
- Windows cmd/PowerShell 原生支持,不需要 WSL2
- 首次引导( API 配置 + 连通性验证)
- 执行过程只显示 spinner ,完成后输出用户可读的结果摘要
- 支持任何 OpenAI 兼容 API (本地 Ollama / DeepSeek / 硅基流动等)
四、还差什么
说实话,有些地方还挺粗糙的:
- AST 调用图目前只完整支持 Python ,其他语言调用图准确率还没有充分验证
- 专家飞轮的 Gate 2 回测逻辑偏简单,还不够严格
- Windows 上的各种边界情况( AMD 显卡、部分 Ollama 版本兼容性、中文路径)没有充分测试
- 钉钉/飞书 webhook 没做,手机发消息触发 agent 这个场景设计了但没实现
- 没有 IDE 插件,目前只有 CLI
- Prompt Optimizer (用 Opus API 自动迭代优化专家 prompt )只做了框架,没有跑起来
五、为什么想让更多人一起做
我一个人做这个工具有明显的上限,不是技术上的上限,是视野上的上限。
我自己主要用 Python 和 FastAPI ,所以这方面想得细。但我不知道每天写 Spring Boot 的人最痛的点在哪,不知道搞 Rust 的人在本地模型上遇到什么问题,不知道做小程序的人需要什么。
更重要的是,这件事不应该只是一个人的工具,应该是中国开发者社区的工具。
CC 是 Anthropic 的,Cursor 是美国公司的,Hermes 是外国社区做的。我们用的工具,我们的使用习惯、技术栈偏好、本地化需求,从来都是别人顺手加进去的功能,不是第一优先级。
我想做的是反过来——把中国开发者的需求放在第一位,把本地开源模型的适配放在第一位,然后把这个工具做到能和大厂产品掰手腕。
这件事一个人做不到,但开源社区可以。
Linux 打败了 Unix ,不是因为某一个天才,而是全球开发者共同维护了几十年。VSCode 能超过那么多商业 IDE ,也是因为背后有庞大的插件和贡献生态。
KWCode 不需要你有多高的水平,只需要你在用本地模型做开发,然后把你遇到的问题、你的解法、你的改进贡献进来。多一个人,就多一个使用场景被照顾到,多一个坑被填掉。
Fork 这个项目,改进你最痛的那个点,提 PR ,我们互相借力,一起把它做好。
闭源大厂有钱有人有算力,我们有什么?我们有真实的使用场景,有对本地部署的真实需求,有不依赖海外服务的动力。这已经足够了。
六、怎么参与
项目地址 :github.com/val1813/kwcode
# Fork 项目,克隆到本地 git clone https://github.com/your-fork/kwcode.git cd kwcode # 安装开发版 pip install -e ".[dev]" # 运行测试确认环境正常 python -m pytest kaiwu/tests/ -v # 找一个你最想改的地方,开始动手 git checkout -b fix/your-improvement改什么都可以:
- 你每天用 Go 写代码,觉得 Go 的 AST 调用图支持不够好,就去改它
- 你在用 Qwen3 发现某个场景总是触发无限循环,就去修它
- 你有更好的 context 压缩算法,就替换掉现有的
- 你发现 README 写错了,改一个字也算
Issues 里列了已知问题和规划中的功能,可以从那里找方向。Discussions 里可以聊技术思路,聊某个方向值不值得做。
没有什么贡献太小。
七、最后说一句
我不知道 KWCode 能不能真的超越 CC 或者 Hermes 。
但我知道,如果中国开发者一直用别人做的工具,一直把自己的需求当作”次要功能”等别人来实现,这件事永远不会有答案。
有些东西,只有自己做才知道能不能做到。
项目是 MIT 开源的,你贡献的代码永远是你的。如果 KWCode 最后做成了,这件事是所有参与的人一起做成的。
项目地址 :github.com/val1813/kwcode
天工开物 · KWCode · 中国开发者自己的本地 Coding Agent
作者: KaiWuBOSS | 发布时间: 2026-04-28 13:24
8. Google 搜索指定 site 参数失效
用的 chrome 浏览器,使用无痕窗口或者未登录 google 账号进行搜索一切正常
但是登录了 google 账号搜索参数指定 site 是无效的,比如
site:[v2ex.com](http://v2ex.com) google会出现一堆 V2EX 无关的内容,有大佬知道这是怎么回事吗
作者: honmaple | 发布时间: 2026-04-28 17:29
9. 公司买 api 一般是官 key 还是中转?
老板体验了 claude 后拍板要把 claude 嵌入全公司工作流,让我去解决采购渠道问题,要求数据不得经过非正规公司传送,大概意思估计是买大厂 vps 自建 api 代理可以,但不能买贩子的中转站。但是先不说走什么代理的问题,国内几乎都找不到官 key 的货源啊,都是 5 刀 20 刀这种个人用的,总不能让老板去小黄鱼买吧。
问了几家能做对公的,都是中转,拍胸脯保证他们客户都是大厂,绝对稳定高质量,但那个价格感觉就像假的。
老板要求 3 天内必须给结果,老板不懂电脑,跟他没法解释
作者: my2492 | 发布时间: 2026-04-28 07:22
10. 现在网上都在说 Agent 自动开发,我还是在对话模式,是不是落后了?
最近这段时间看了很多关于 AI 开发的文章、博客、视频, 尤其是各种 Agent 工作流 的分享。
比如:
AI 自己拆任务 AI 自己写代码 AI 自动做 code review AI 自动提交 PR AI 管理整个项目流程
甚至有些文章给人的感觉是:
人只需要把需求说清楚,剩下的事情 AI 自己就能完成。
说实话,看多了之后,我开始有点焦虑了。
先说一下我的背景:
我是一个前端开发工程师, 使用 AI 辅助开发大概有 一年半左右 了。
平时主要工具是:
Claude GPT Cursor Windsurf
基本每天都在用,也算是比较重度用户。
但我目前真实的工作方式,其实还是:
人主导开发 + AI 辅助 主要是对话模式
比如:
写代码的时候遇到问题就问 AI 让 AI 帮我优化一段逻辑 让 AI 帮我 review 一段代码 或者生成一些基础结构
整体感觉:
AI 很强,但更像一个:
非常聪明的助手,而不是一个真正能接管项目的“开发者”。
我现在的困惑主要有几个:
1 )现在真的有人在用 Agent 自己写代码吗?
不是 demo , 而是:
在真实项目里长期使用
比如:
前端项目 后端服务 中大型系统
而不是一个简单的脚手架项目。
2 )现在的开发流程,真的变成这样了吗?
比如:
人只负责写需求 Agent 自动拆任务 Agent 自动写代码 Agent 自动测试 Agent 自动提交 人只负责最后确认
如果真有人这样用,我非常想了解:
这个工作流到底是怎么搭建的?
3 )前端和后端的差别是不是很大?
我有一种感觉是:
很多文章里的 Agent 工作流, 可能更偏:
后端 AI 工程 Python / Node 服务 工具链开发
而前端这边:
UI 交互 状态管理 兼容性 复杂业务逻辑
可能还比较难做到完全自动化。
但这只是我的猜测,不确定是不是事实。
4 )大家现在真实的 AI 工作流到底是什么样的?
比如:
你们现在更接近哪种模式:
A ) 人写代码 + AI 辅助
B ) 人设计结构 + AI 写大部分代码
C ) Agent 负责模块开发,人负责 review
D ) Agent 基本可以接管项目
我不是质疑 AI 的能力。
只是看了太多“AI 自动开发”的文章之后, 开始有点不确定:
现在行业真实的状态,到底是什么样的?
是:
大家已经进入 Agent 自动开发阶段了, 还是说大多数人其实还是:
对话模式 + 人主导开发
只是没有人专门写这种“普通但真实”的文章。
如果有在实际项目里长期使用 Agent 的同学, 非常希望能分享一下:
你们用的工具 工作流大概是什么样 哪些事情真的能自动化 哪些事情还是必须人工做
小弟真心求教。
作者: shibow | 发布时间: 2026-04-28 03:13
11. AI 编程,大伙顺手的方案有哪些?如何合理白嫖?
感觉写代码有些部分有点枯燥,近两天计划尝式下 codex,cursor.
codex(windows desktop app),免费版,一周 256K(好像不是 256,不过差不多),今天试了写个简单的项目,来回修改,不过前后端是跑起来了,加加功能,200 多 K 没了.
cursor,免费版,感觉它就是不让你一次性写好,每次完成一部份,试了下,完成了二三次对话,后端没试,前端能跑能显示(第一版代码大多是个框架),后面玩 codex 去了,明天还是要继续用完额度,与 codex 对比下,随便一次对话,额度 30~40%左右没了.
这个比起一个个敲还是有效率,有些小项目麻雀虽小,五脏俱全,有些项目有些部分,大多是重复工作,没啥技术含量,也得一个个敲,累.这个好用,打算长期使用了.
前辈们在用 AI 编程时,哪些方案比较顺手,好用. 在付费这方面,有什么省钱的攻略吗.
🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍🐱🏍
作者: dnjat | 发布时间: 2026-04-28 14:01
12. 机场的私有客户端, win 系统 defender 疯狂报病毒,拒下载安装,是有毒吗?
用了好几个机场,以前都是 clash 这些订阅链接,最近全部失效了,必须下载机场私有客户端
下载这些私有机场客户,win10 win11 系统 defender 安全中心疯狂爆毒,拒绝下载和安装。
虽然不涉密,但是电脑上还是有不是密钥之类的因素文件啊。这些私有 机场.exe 文件不知道真的有没有毒啊?慌的一批
老铁们,有什么测试可以检验这些 机场.exe 是不是安全的方法?
作者: jacketma | 发布时间: 2026-04-28 02:35
13. 怎么使用 ai 提升开发效率
各位大佬都是怎么把 ai 用到开发中的,自己倒是安装了 opencode ,买的 deepseek 的 api ,但是对现有的项目维护不太友好。如果用 jetbrains 家的 IDE ,要安装什么扩展
作者: zookao | 发布时间: 2026-04-28 08:15
14. 国内 dns 出问题了, icu 域名解析错乱了
刚发现自己的 icu 域名访问不到了,查了下 dns ,国外的正常,国内的全是错的。
作者: yihy8023 | 发布时间: 2026-04-28 06:18
15. 有没有靠谱的 GPT Pro 代充站
作者: collvey | 发布时间: 2026-04-28 11:06
16. 请教下大家,做了一个 ai 应用,想上架 app store 需要深度合成备案么?
我去网上搜好像说需要什么深度合成算法备案,不知道是否真的需要提交,有懂的 v 友么
作者: 0x01Dev | 发布时间: 2026-04-28 09:27
17. codex 周额度刷新了,提前了 21 小时,小赚
看了下所有渠道都收到
额度刷新告警了Codex 5h + 1w 下次刷新 05/05 13:29 · 提前 21h 47m 06s · 恢复 67% → 0%





作者: mains | 发布时间: 2026-04-28 05:43
18. 请问下开多个账户订阅 opencode go 套餐有没有风险?不会封号把?
一个号套餐的额度养 hermes 根本不够,我就开了 3 个号订阅,然后统一接到我的聚合站上轮询使用,开了 3 个号,感觉没有阿里腾讯 200 的 coding plan 套餐耐用,但是胜在模型更新勤快
问一下这样会不会封号?
作者: lynn1su | 发布时间: 2026-04-28 10:05
19. 目前本地知识库最好的方案是什么?
目前本地知识库最好的方案是什么
作者: k5ye533 | 发布时间: 2026-04-28 09:31
20. 买 mac 还是转 Linux 系统
CPU
- Intel Core i7-8550U @ 1.80GHz (睿频 4.0GHz )
- 4 核 8 线程, 8MB L3 缓存
内存
- 16GB DDR4 (已用 4.4GB ,可用 11GB )
- 7.7GB Swap
显卡
- 集显: Intel UHD Graphics 620
- 独显: NVIDIA GeForce MX110 (GM108M)
硬盘┌──────┬──────────────────────────────────────┬───────┬────────────────────┐
│ 设备 │ 型号 │ 容量 │ 挂载点 │
├──────┼──────────────────────────────────────┼───────┼────────────────────┤
│ sda │ 海力士 HFS128G39TNF-N3A0A (NVMe SSD) │ 120GB │ /boot/efi, /, swap │
├──────┼──────────────────────────────────────┼───────┼────────────────────┤ │ sdb │ 希捷 ST1000LM048-2E7172 (HDD) │ 1TB │ /home/data, /home │
└──────┴──────────────────────────────────────┴───────┴────────────────────┘
上面是我笔记本的配置.目前是感觉太卡了,19 年买的笔记本(小米),也没清灰.是换 mac 还是像现在一样用 linux
作者: fightingCode948 | 发布时间: 2026-04-27 13:40
21. 有没有类似 ChatGPT 这种 Agent 能力的 API
ChatGPT 这个 Agent 两个方面的能力感觉非常厉害 一个是联网搜索核对/总结信息,甚至是它自动的,觉得必要时自动搜索 第二个是对于一些逻辑性较清晰/能通过计算得到答案的任务需求,或者通过编程更容易得到答案的任务,它不是靠模型自己在那瞎想推理,而是会自己写 Python 代码自己跑,然后总结 Python 程序运行的结果来告诉你答案。
很可惜 OpenAI 似乎没有直接把 ChatGPT 的能力作为 API 开放出来,如果要实现类 ChatGPT 的功能得手搓 Agent 了,有没有什么 ChatGPT 类似能力的 API 替代品呢
作者: liyafe1997 | 发布时间: 2026-04-27 21:56
22. HTML in Canvas,下一代 Web 图形开发范式?
Demo
解决了哪些问题
Web 开发者在处理 Canvas 内容时长期面临一个尴尬的现实:Canvas 擅长像素级操作,但对 HTML 的布局能力一无所知。这导致了几个核心问题:
可访问性的缺失 - 当你用 Canvas 绘制复杂的文本或 UI 时,屏幕阅读器可能无能为力。传统的 fallback 内容往往与实际渲染内容不同步,开发者需要手动维护两套内容。
国际化噩梦 - Canvas 没有内置的文本排版引擎。从右到左( RTL )的文本、垂直书写模式、多语言混排、表情符号,这些在 HTML 中现成的功能在 Canvas 里都需要从零实现。
性能与质量的权衡 - 许多应用选择用 Canvas 渲染 UI 以获得高性能,但不得不牺牲文本渲染的质量和交互性。或者用 DOM 渲染获得完美体验,但付出性能代价。
无法组合现代 Web 技术 - 你想在 WebGL 场景中显示精美的 HTML UI ?想在 3D 立方体上贴上动态的 HTML 内容?抱歉,现有的组合方式要么性能低下,要么实现极其复杂。
媒体导出困难 - 想将网页中的某个 HTML 区域导出为图片或视频?没有标准 API ,开发者只能依赖各种 hack 或第三方库。
这个提案通过三个核心原语——
layoutsubtree属性、drawElementImage方法和paint事件——让 HTML 元素可以无缝地渲染到 2D 或 3D Canvas 中,同时保留其完整的语义和交互能力。使用场景
1. 图表与数据可视化
想象一下,你的图表库需要在 Canvas 中绘制精美的图例、坐标轴和注释。现在你可以直接用 HTML 编写这些元素,利用完整的 CSS 样式和排版能力,然后将其绘制到 Canvas 中。
2. 游戏与创意工具的 UI
游戏开发者经常需要在 Canvas 中构建复杂的界面——装备面板、技能树、聊天窗口。用 HTML 构建这些 UI 既快速又美观,还能获得原生的表单控件和输入体验。
3. 3D 场景中的 2D 内容
WebGL 和 WebGPU 应用需要将文本、图标等 2D 元素贴到 3D 表面上。以前这需要将文本渲染为纹理,现在可以直接使用 HTML 元素,支持实时更新和动画。
4. 国际化富文本编辑器
需要支持多语言、复杂文本布局的编辑器可以结合 Canvas 的高性能和 HTML 的排版能力。
5. 高性能媒体导出
当你需要将网页内容导出为图片或视频时,
captureElementImageAPI 可以捕获 HTML 元素的渲染快照,在 Worker 线程中进行处理,避免阻塞主线程。6. WebGPU 高级效果
最激动人心的是与 WebGPU 的结合。基于光线步进( ray-marching )的果冻滑块示例展示了如何将 HTML 文本集成到复杂的着色器效果中,这是传统方法无法实现的。
工作原理
HTML-in-Canvas 的核心思想是:让浏览器同时处理 HTML 布局和 Canvas 渲染,并保持两者同步 。
1.
layoutsubtree属性<canvas layoutsubtree> <div id="content">这是要绘制的 HTML 内容</div> </canvas>这个属性告诉浏览器:Canvas 的直接子元素应该参与正常的 DOM 布局流程,包括盒模型、层叠上下文、点击测试等。这些元素在视觉上是”隐藏”的(不在页面渲染树中),但它们的布局信息会被保留。
2.
drawElementImage方法const ctx = canvas.getContext('2d'); const transform = ctx.drawElementImage(element, x, y, width, height);这个方法将元素绘制到 Canvas 中,并返回一个变换矩阵。关键点:
- 元素的 CSS 样式(包括复杂文本布局、渐变、阴影等)会被完整保留
- 绘制时应用 Canvas 当前变换矩阵( CTM )
- 内容会被裁剪到元素的边框盒
- 返回的变换矩阵可以用于同步 DOM 位置,确保点击测试和无障碍功能正常工作
3.
paint事件与requestPaintcanvas.onpaint = (event) => { // 重新绘制变化的内容 ctx.reset(); ctx.drawElementImage(element, 0, 0); }; canvas.requestPaint(); // 手动触发绘制当 Canvas 子元素的渲染发生变化时,
paint事件会自动触发。对于需要每帧更新的场景(如动画),可以调用requestPaint()强制触发绘制。4. DOM 到 Canvas 变换同步
这是最精妙的部分。为了让点击测试、Intersection Observer 和无障碍功能正常工作,元素在 DOM 中的位置需要与在 Canvas 中绘制的位置保持一致。
drawElementImage返回的变换矩阵可以直接应用到element.style.transform:const transform = ctx.drawElementImage(element, x, y); element.style.transform = transform.toString();这个变换考虑了:
- Canvas 的当前变换矩阵( CTM )
- 绘制位置和尺寸
- CSS 像素到 Canvas Grid 像素的缩放
- 元素的 transform-origin
5. WebGL/WebGPU 集成
对于 3D 上下文,提供专门的方法:
// WebGL gl.texElementImage2D(target, level, internalFormat, format, type, element); // WebGPU // 通过 copyElementImageToTexture 将元素复制到纹理在 webGL.html 中,HTML 内容被直接渲染到纹理,然后映射到旋转的立方体上。
6. OffscreenCanvas 支持
为了利用 Worker 线程的性能优势,可以使用
captureElementImage:// 主线程 const elementImage = canvas.captureElementImage(element); worker.postMessage({ elementImage }, [elementImage]); // Worker 线程 const transform = offscreenCtx.drawElementImage(elementImage, x, y);README.md 中的示例展示了完整的 Worker 模式。
源码解读
核心 API 设计
在 README.md 中可以看到完整的 IDL 定义:
partial interface HTMLCanvasElement { [CEReactions, Reflect] attribute boolean layoutSubtree; attribute EventHandler onpaint; void requestPaint(); ElementImage captureElementImage(Element element); DOMMatrix getElementTransform((Element or ElementImage) element, DOMMatrix drawTransform); }; interface mixin CanvasDrawElementImage { DOMMatrix drawElementImage((Element or ElementImage) element, ...); }; CanvasRenderingContext2D includes CanvasDrawElementImage;这个设计遵循了几个重要原则:
- 渐进增强 - 通过属性而不是全新的元素来扩展功能,保持向后兼容
- 上下文无关 -
drawElementImage是混入( mixin ),可以在 2D 、WebGL 、WebGPU 上下文中使用- 事件驱动 - 使用
onpaint事件而非轮询,性能更好示例实现细节
文本输入示例 (text-input.html)展示了标准模式:
canvas.onpaint = (event) => { ctx.reset(); // 清除并重置变换 const transform = ctx.drawElementImage(draw_element, x, y); draw_element.style.transform = transform.toString(); // 同步位置 };饼图示例 (pie-chart.html)展示了如何与 Canvas 绘图结合:
// 1. 用 Canvas API 绘制扇区 const path = new Path2D(); path.arc(0, 0, radius, angle, angle + slice); ctx.fill(path); // 2. 用 drawElementImage 绘制标签 const transform = ctx.drawElementImage(label, x, y); label.style.transform = transform; // 3. 用 Canvas API 绘制焦点环 if (document.activeElement === label) ctx.drawFocusIfNeeded(path, document.activeElement);还存在哪些问题
尽管这个提案已经相当成熟(已在 Chromium 中实现并通过 flag 启用),但仍有一些挑战和未解决的问题:
1. 浏览器支持有限
目前只有 Chromium 支持,且需要手动启用
chrome://flags/#canvas-draw-flag。Firefox 、Safari 尚未表态。没有跨浏览器的一致实现,开发者很难在生产环境使用。2. 性能考量未完全明确
虽然理论上 Worker 模式应该更快,但实际的性能基准测试还不足。以下问题需要答案:
- 复杂 DOM 树的
captureElementImage有多昂贵?- 在高帧率动画中频繁同步变换是否会导致抖动?
- 与传统的文本绘制 API 相比,性能如何?
3. 隐私与安全边界
HTML-in-Canvas 可能被用于”截屏”攻击,恶意网站可以捕获用户输入或敏感内容。提案提到了”隐私保护绘制”(相关文档),但具体的安全模型还在讨论中。
4. 复合层管理
Canvas 中的 HTML 元素如果包含复杂的 CSS 效果(如 backdrop-filter 、混合模式),如何正确处理复合?这需要浏览器引擎的深度集成。
5. 可访问性工具的适配
虽然语义元素会被保留,但屏幕阅读器等辅助技术需要理解”这个元素同时在 DOM 中和 Canvas 中”的状态。需要 ARIA 规范的相应更新。
6. 开发者体验的优化
目前的 API 需要开发者手动管理变换同步。虽然这是为了保证最大灵活性,但对于简单的用例可能过于复杂。未来可能需要更简化的 API ,如自动同步模式。
7. 测试与调试
如何在开发者工具中调试 Canvas 中的 HTML 元素?现有的 DOM Inspector 需要扩展,或者需要新的调试面板。
8. 与现有技术的协调
如何与现有的 HTML Canvas API (如
measureText)、SVG<foreignObject>、以及 CSS Houdini 等技术共存?需要明确的使用场景划分。
总结
HTML-in-Canvas 是一个有望改变 Web 图形开发范式的提案。它巧妙地解决了长期存在的”Canvas vs DOM”对立问题,让开发者可以”既要又要”——既享受 Canvas 的渲染控制力和性能,又保留 HTML 的语义、可访问性和排版能力。
核心价值在于组合性 :这不是让 Canvas 重新实现 HTML ,也不是让 HTML 变得像 Canvas ,而是让两者无缝协作。这种设计哲学与 Web 的开放性本质一脉相承。
随着浏览器厂商的更多支持、性能基准测试的完善、以及开发者社区的反馈,这个技术有潜力成为现代 Web 应用的基础设施之一。对于游戏引擎、图表库、创意编码工具等领域,这是一个值得密切关注的方向。
视频版本: [ HTML in Canvas — 下一代 Web 图形开发范式?-哔哩哔哩] https://b23.tv/Js1KDKp
作者: occupy555 | 发布时间: 2026-04-28 06:57
23. 大家用 DeepSeek 都调用的哪里?官方还是其他平台?为什么我调官方感觉很慢?
直接调用 DeepSeek 官方明显比火山慢不少
大家一般都用哪里的服务?如果不是官方,主要是出于速度、稳定性还是价格考虑?
作者: fkdtz | 发布时间: 2026-04-28 09:01
24. 5.1 香港旅游,众安银行开户 额外返现 300hkd 截止 5.27 日
邀请代码:HCEAD7
电报:@fgvbt123




作者: fgvbtttt | 发布时间: 2026-04-28 14:10
25. Copilot 年度计划凉了:不再更新功能,我已申请退款
6 月 1 日 GitHub Copilot 年度计划变更
GitHub 正在逐步取消 Copilot 年度订阅。当前用户不受立即影响,但后续会有结构性变化:
核心变化
年度计划取消(逐步)
- 已订阅用户:当前周期内不变
- 到期后:自动降级为 Copilot Free
计费模式调整
- 现有 **Pro / Pro+**:继续采用「高级请求( usage-based )」计费
- 趋势:全面转向按使用量付费
模型策略变化
- 模型乘数 ↑(成本上涨)
- 标准层模型(当前 0x )→ 移除
功能冻结
- 年度计划不再新增任何模型或功能
一句话重点
年度计划 = 只维持现状,不再进化,最终引导迁移到按量付费体系
影响解读(技术向)
旧订阅 ≈ “锁版本”
新能力(模型 / 推理能力)→ 只在 usage-based 体系提供
成本结构:
固定订阅 → 可预测成本 usage-based → 与调用量强绑定(高频用户成本上升)
建议
- 高频用户:评估请求量 → 预估 usage 成本
- 低频用户:直接用 Free 或按需付费
- 团队用户:考虑是否迁移到统一 usage 管理(避免不可控费用)

作者: zishang520 | 发布时间: 2026-04-28 02:25
26. 企业版 kiro 不给我用 claude 了
公司采购的企业版 kiro ,部分员工没有 claude 模型可用(比如我)
有咩老哥知道这是啥情况?

作者: nc4697 | 发布时间: 2026-04-28 01:29
27. chrome 风格的新终端 crTerm v146 macOS 正式版
终于把代码全部 merge 到 macOS
测试下来跟 Linux 版本一样的体验
正式版下载 https://github.com/wuruxu/crterm/releases
有问题提交到 https://github.com/wuruxu/crterm/issues

作者: wuruxu | 发布时间: 2026-04-28 13:32
28. 如何使用 web 框架调用 codex cli/claude code cli
部门同事对 ai 使用不太感冒,想在一台电脑上安装 codex cli/claudecode cli 使用写好的 skills 类似调用 api 一样写入一个前置的 system prompt. 来处理大家的需求,最好还能提供进度显示。请问有没有类似的实现方法?
作者: senooo | 发布时间: 2026-04-28 03:24
29. 字节这 Code Plan 诈骗吧
每 5 小时:最多约 1,200 次请求
就问了 2 两个问题额度就耗光了,第 2 个问题刚好卡中间浪费时间。总共估计 100 次请求左右,它这是怎么计算的,10 倍吗!
卖不起就别卖,标的很高骗人进去,挂羊头卖狗肉
作者: tt83 | 发布时间: 2026-04-27 07:22
30. 发现一个邪修快速清理 Git 项目里面空文件夹的方法🤡 不知道有没有什么其他标准做法.
因为项目里面来回切分支, 有些分支是有特殊资源或者 sdk 的, 切完分支之后, 会遗留一些空文件夹在本地.
之前觉得没啥, 但是现在用 AI 开发, AI 每次读到空文件夹的时候, 都会啰嗦几遍发现 xxx 文件夹, 但是是空的, 看样子 xxx, 让我来 XXX, 然后就走偏了.
因为空文件夹默认是不被记录到 git 里面的, 所以我现在的做法是, 把项目里的内容全删掉, 然后再 discard, 一个干干净净的目录就出来了😂
不知道佬们有没有什么更专业的处理方法? 欢迎讨论, 求轻喷.
作者: JoeJoeJoe | 发布时间: 2026-04-28 01:50
31. 开发、测试、运维各用各的 AI,怎么避免把同一件事来回说好几遍?减少重复 token 消耗。
想问一下有没有实际在用的、不太重的方法或团队协作的 Coding Agent 方案,比如:
开发产出一种“给下游 AI 看”的简短上下文
或者一种跨角色共享的小文件(不是长篇设计文档)
或者聊天工具里某种引用机制
不指望一个工具解决所有问题,就想知道有没有人踩过这个坑、用了什么土办法或者半自动方案。
谢谢🙏
作者: v2er119 | 发布时间: 2026-04-28 01:34
32. Codex 额度又重置了 ?
真是大善人,一个月不到重置了好几次。
作者: HarryQu | 发布时间: 2026-04-28 07:10
33. JS/Node 已经是新时代的 Java 了吧
一种毒瘤。 确实能跨平台。 下载的包动不动几百 M ,内存吃掉几百 M 。 一个本该「小而美」的 CLI 程序,开上三四个,也要 2G 的内存。 16G 的 Macbook 也扛不住啊。内存又这么贵,不给人留活路了。
作者: xiaotianhu | 发布时间: 2026-04-28 06:45
34. AI 用起来,感觉像拼多多砍一刀
永远给你说,这一版的代码是最好的。喂给它结果,它发现结果不对,又给一版让你测试,每次改代码感觉自己像个工具人,自己从研发变成了帮它测试。
作者: kaivbv | 发布时间: 2026-04-28 03:19
35. 各位大佬们,你们 win 系统安装了什么杀毒软件?
是微软自带的还是第三方的?免费的还是付费的?
作者: jumkey | 发布时间: 2026-04-27 01:28
36. 用 WoA, Python 和 nodejs 还是得老老实实装 x64 版(即使有原生 ARM64)
虽然 Python 和 nodejs 都有原生 for Windows ARM64 支持,但是还有相当一部分的第三方包没有 win32-arm64 这个组合。
也许一直用着 ARM64 版的都没问题,直到某一天突然碰壁,某个包没有
于是你就要浪费人生中 N 分钟卸载 ARM64 版 python/node ,重装 x64 版,重配环境…
还不如一开始就装 x64 版
其实转译性能也很不错,至少体感上感觉不出来
作者: liyafe1997 | 发布时间: 2026-04-28 09:10
37. 求安利! Chrome 验证码自动识别
有没有插件,可以自动输入简单的字符图片验证码
欢迎大家交流!
作者: knowckx | 发布时间: 2026-04-28 06:04
38. 使用 Claude code 安装了 andrej-karpathy-skills, superpowers 还需要禁用吗
还是结合起来使用,大佬们分享一下
作者: miusmile | 发布时间: 2026-04-28 03:41
39. chrome 风格的新终端 crTerm v146 Linux 正式版
主要功能:
1. 原生支持 chrome 主题和扩展,新增 crterm extension api
2. 原生支持侧边栏
3. 内置的图片预览
4. 终端配置管理
5. 浏览器风格的多 tab 页操作体验



作者: wuruxu | 发布时间: 2026-04-28 09:39
40. claude.ai 多账号限额查询脚本
仓库
https://gitee.com/lyxxxh/claude_usage
Claude.ai 多账号限额查询
config.example.json改名config.json- 修改
config.json- 代理修成你电脑的,并填写
session_key和org_id
- 获取方式:见下面的截屏
python [claude_web_usage.py](http://claude_web_usage.py)建议做成一个全局命令,方便调用。
我的:claude_run.bat:
python "C:\Users\Administrator\code\claude_usage\[claude_web_usage.py](http://claude_web_usage.py)"session_key
sessionKey 过期不晓得,我 4 个账户的 sessionKey 过期都是:
2026-05-26T03:17:16.296Z,估计活跃自动续期。打开:https://claude.ai/settings/usage
org_id



作者: lyxxxh2 | 发布时间: 2026-04-28 04:32
41. 现在还有什么 gpt 账号 plus 的渠道吗?号商别再内斗了
之前 7 块钱一个月的 plus 是真的香
有的话偷偷说
别再发帖直接掀桌子了
作者: PeterTanJJ | 发布时间: 2026-04-27 04:09
42. qwen3.6 27b 本地编码测试
搞了一上午,本地 a100 40g ,输出也慢 40t/s
大概的提示词劳力士风格,罗马数字,月相日历,高贵典雅
月相那块搞了好多轮
结论:
小参数的模型智力不差,Trae IDE agent 连接本地模型,coding 完全可用
作者: zsj1029 | 发布时间: 2026-04-27 06:36
43. 求 Windows UWP 软件大佬实现一个 terminal 功能
个人觉得 Windows 自带的 terminal 工具很好用,手感很好渲染也不错,可惜不支持侧边栏显示 tabs/workspace ,现在 claude code/codex 用得多,经常要开很多个 tabs ,导致 tabs 超出了横向显示空间,如果能支持垂直标签页外加工作区,那将是非常好用的一个功能,可惜我不擅长 Windows 软件开发,Visual Studio 开发对于 Agent 来说不友好,求大佬帮忙实现这个功能,我给你 stars !
https://github.com/microsoft/terminal


作者: zisen | 发布时间: 2026-04-27 13:06
44. 最近配了一台新的台式电脑,我想在外面笔记本上可以远程回去直接玩游戏,求方案
求各位大佬指点一下,来个方案,不要远程软件,例如:向日葵,todesk 等
作者: babymonster | 发布时间: 2026-04-27 08:51
45. opencode go 的 DeepSeek 是官方直连吗
今天看了下 DeepSeekV4 的次数涨了不少,估算了下 token 好像吃上折上折了? 预估了一下 token 量,算上缓存的话 一个 go 套餐里,DeepSeek V4 Flash 已经约等于 10,923,420,500 token 了。
作者: ayasealter570 | 发布时间: 2026-04-27 12:47
46. 全球本地部署开发者们一起,打造一个真正属于开源社区的 Coding Agent 了
同志们,是时候打造一把真正属于开源社区的 Coding Agent 了!
现状:我们被大厂“喂屎”,还要自己擦屁股
我写过 kaiwu(一个本地模型部署器),结果发现——用 Local LLM 做开发的朋友,多得超出想象 。
大家不断提需求:上下文压缩、Think 模式开关、联网搜索、工具调用……
可这些根本不是 Ollama 或 LM Studio 的事 !
它们只负责把模型跑起来,至于“怎么让模型变聪明”——那是 Cursor 、Codex 、Hermes 的事。但大厂们在干嘛?
- Cursor 围着自家模型转
- Codex 靠卖 token 赚钱
- Hermes 虽开源,却不支持 Windows 原生(逼你装 WSL2 ,劝退一半人)
它们不会花精力优化本地小模型。
因为本地跑得爽,谁还买它们的 API ?更别提那堵墙了——
国内网络时断时续,任务跑到一半断连,体验像吃苍蝇。
想用 Claude ?得找中转、买注水账号、被收割、还被鄙视。但墙能拦住资本,拦不住人民。
国际共产主义精神,就体现在一行行开源代码里。
痛点:我们每天都被这六把刀捅
1. 上下文太短,压缩就“失忆”
- Opus 的 1M 窗口用过就回不去了,永远不用 compact 。
- 小模型在 8G/16G 显存上只能跑十几 K ,稍微大点的任务直接炸。
- Hermes 压缩几次就变傻子——忘了自己两轮前说过什么。
2. 网络像一堵墙,墙内外都是屎
- CC / Cursor 要稳定连海外,国内断到你怀疑人生。
- Hermes 非要 WSL2 ,Windows 原生用户吃闭门羹。
- Web search 要么没有,要么接垃圾商家 API ,搜出来的全是 SEO 污染的结果。
3. 本地模型连工具都不会用
- 用户反馈:接 CC 或 Codex ,模型笨得不会调 tool 。
- 8B 模型干完活丢给你一串代码:“自己复制去运行”。
- 我是用 CC 习惯的人,这体验等于让我回去用记事本写代码。
4. 小模型本身能力就那样,但 API 还不让用
- 8B/14B 失误率高、窗口小、没联网、遇新问题就死机。
- 你不可能指望小学生解微积分——这是物理规律。
- 可 A 厂不给国人注册,花钱买注水中转,像交保护费。
凭什么?5. 明明本地运行,却是个没记忆的钢铁废料
- 在云端不记事,我认了——毕竟没花钱买存储。
- 我都本地跑了 ,硬盘 1T 还能加,你却只给我一个 markdown 文件当“记忆”?
这就像你买了一台超级计算机,结果它每次重启都忘光。6. 多模态?视频图片?不存在的
- 模型本身弱,但更大的问题是——没有专门优化。
- 闭源 API 也一样烂,但人家收钱不办事。
部署难、速度慢、硬件要求高这些,我之前的 kaiwu + LM + Turbo 能解决。
今天我们不聊这些,就聊怎么让 8B 模型跑出 Opus 的体验 。
我的革命思路:不用 CC 的依赖强 LLM 串行,改用 LLM 做 Gate + 确定性专家的 MOE 架构
核心理念 :
LLM 只负责当“接线员”,真正干活的是确定性专家 ——
不依赖模型“啥都懂”,而是让模型只做一件极小、极明确的事。原理一:Agentless 流水线( ICSE 2025 最佳证明)
不让 LLM 瞎决策,用固定流程 → SWE-bench 上通过率最高,成本最低 。
我设计的流程( KWCode ): 用户输入 └─► Gate (毫秒级分类) └─► Locator (精确定位文件/函数) └─► Generator (只改该改的地方) └─► Verifier (语法 + pytest ,失败重试)
小模型只需要在小窗口里做一件事——失误率暴跌,错误可被当场抓住 。
原理二:BM25 + AST 调用图定位(专治“隐藏依赖”)
论文 CodeCompass 发现一个反常识 事实:
context 越大的模型,反而越容易漏掉架构上关键但语义上遥远的文件 ——这叫“导航悖论”。实验数据( FastAPI 真实项目):
任务类型 BM25 图遍历 有明确关键词 100% — 可通过 import 链找到 ~85% ~85% 完全无关键词的隐藏依赖 76.2% 99.4% 🚀 我们的实现 :
- BM25 秒级召回 top-20
- AST 调用图展开 2 跳(向上找调用者,向下找被调用者)
- 发现那些“名字和 bug 无关但实际是根因”的魔鬼函数
技术栈:
tree-sitter+rank-bm25+SQLite
零依赖、零 embedding 、零 Docker 。
支持:Python · JS · TS · Java · Go · Rust原理三:专家飞轮——你的工具越用越强,大厂永远追不上
来自 EE-MCP (NeurIPS 2025) + WLBS 行为图。
预置 12 个专家(通用 7 个 + 中国场景 5 个)。
然后开始飞轮 :
- 同类任务成功 ≥5 次 → 自动生成专属专家
- 新专家经过回测 + AB 测试 三道验证门 → 投产
- 下次同类任务,Gate 直接路由 → 更快、更准
3 个月后,你的专属专家池——
Cursor 和 Hermes 永远追不上,因为它们无状态 ,而你有永久记忆 。专家可以导出、分享形成我们的社区数据资源。
原理四:失败自动搜索——墙内用 Bing ,墙外用 DDG
Verifier 连挂 2 次 → 自动触发搜索:
- 国内网络 → Bing 中文版( cn.bing.com 直连)
- 正常网络 → DuckDuckGo
- 提取正文 → 压缩 → 注入 context
零 API key ,零配置,装完即用。
想更隐私?自己部署 SearXNG ,数据不出网。
功能一览(不是为了炫技,是为了解决你的每一天的痛)
模块 做了什么 代码定位 BM25 + AST 调用图,99.4% 命中隐藏依赖 代码修改 只改 patch ,不重写全文,精确匹配 验证重试 语法 + pytest ,失败回滚,失败 2 次开搜索 项目记忆 PROJECT.md / EXPERT.md / PATTERN.md 三层分离,按需 BM25 注入 专家系统 12 预置 + 飞轮自生成 + 可分享安装 中国本地化 自动切 ModelScope / 清华镜像 / Bing 搜索 / Windows 原生
我们和“它们”的不一样
场景 其他工具 KWCode (我们) Windows 逼你装 WSL2 cmd / PowerShell 原生跑 模型下载 HuggingFace 被墙 自动切 ModelScope pip 安装 PyPI 慢死 自动切 清华/阿里镜像 搜索增强 DDG 被墙 自动切 Bing 中文版 推荐模型 GPT / Claude (要钱/要梯子) DeepSeek · Qwen · GLM (国产免费)
同志们,这不是一个人的战斗
我只有一台 5060 8G 显存 16G 内存小破电脑,硬盘还时好时坏,花钱买 api 一个月三四千。 我想要人人为龙时代,而不是 api 独大时代。 所以我想打造 一个真正属于开源社区、不依赖大厂 API 、不被墙、让 8B 模型也能干翻 Opus 的 Coding Agent 。
我们有论文支撑,有原型代码,有满腔怒火和热血。
现在还缺你——
缺每一个受够了被收割、被歧视、被网络暴力的开发者。GitHub 仓库近期开放,代码完全开源。
你可以:
- 贡献代码( Rust/Python/TS 都行)
- 分享你的专属专家(.kwx 文件)
- 提 bug 、写文档、宣传出去
- 或者只是去点一个 ⭐,让更多人看见
国际共产主义精神,从一行开源代码开始。
让大厂去卖 token 吧,我们有自己的工具了。
行动号召
👉 有没有更好的思路和路径,上述只是我个人研究
👉 后续在本链接发布 github ,欢迎 fork 继续深挖不要让资本定义“可能”与“不可能”。
我们说了算。 或许很快,8B 模型真能跑赢 OPUS ,所有人都能拥有独属于自己的智能体要不要先建个群,算了 我社恐 不会维护,有事咱们这个链接聊把
作者: KaiWuBOSS | 发布时间: 2026-04-27 10:19
47. GLM 的稳定性是不是太离谱了?
刚刚续费了季度 Pro 套餐,就开始疯狂报错
API Error: 400 {“type”:”error”,”error”:{“message”:”网络错误,错误 id 20260427233129a7ee7f005e494d82 ,请稍后重试。”,”code”:”1234”},”request_id”:”20260427233129a7ee7f005e494d82”} * 10
续费季度之前都很少碰到这个,就离谱。
作者: William97 | 发布时间: 2026-04-27 15:38
48. 我的 GPT 是猫,你呢 😄
提示词:
你陪我一段时间了,我想看看你的样子。请生成一张类似你自己用 iPhone 随手自拍的照片:没有明确主题,没有刻意构图,只是很普通,甚至有点失败的快照。照片略带运动模糊,光线不均,轻微曝光过度,角度尴尬,构图混乱,整体呈现出一种”过于真实的随手一拍感”,就像是从口袋里拿出手机不小心按到的自拍

作者: callv | 发布时间: 2026-04-28 08:05
49. Claude 现在不给购买礼品卡了
前几天还能买礼品卡,今天购买提示:
Your account isn't eligible to purchase gifts yet. Contact support if you believe this is an error.正经美国信用卡,无论账号有没有订阅,都是这个提示,这可如何是好。
作者: zhhmax | 发布时间: 2026-04-27 12:13
50. 2026 年上半年, 4000 以内国产安卓大家推荐哪些款?
上一台设备是 2022 年底购买的红米 k50u ,小米之家换过一次电池,前几天突然自己就死了,售后说是主板坏了(维修价格 269 ,修不好不收费),目前放在小米之家售后维修(修得好就等 618 看看新手机,修不好就直接买新的,因为只质保 90 天,我也不太对质量放心了,怕哪天突然又挂了)。
我的需求:
可使用 Google Play ,能正常安装 Google 系应用
拍照别太烂,比如拍细小文字能对焦清晰拍出来,而不是一团糊即可
电池尽量大一点,充电快一点(之前的 k50u 120W 充电速度让我很舒适)
几乎或很少玩游戏,对游戏性能没什么要求
有 NFC ,可满足刷小区门禁等场景,如果有红外功能(可临时应急遥控电器更好)
价格:4000 以内
品牌:由于 k50u 没磕没碰突然自己就死了,所以想说要不换个其他品牌的也试试
各位专家们,基于以上信息,可以说说你们更推荐哪台吗?
作者: willxiang | 发布时间: 2026-04-27 01:28