V2EX 热门帖子
1. 安卓哪个品牌适合做开发机?
想买个开发机,目前已经有了华为、oppo 、三星、小米。 想再买一个其他品牌的。 主要做海外市场。realme 、vivo 、一加哪个好?还有其他推荐吗?
作者: greyfreedom | 发布时间: 2026-04-26 15:17
2. [内测邀请] 做了个临时文件分享工具,无需注册登录,完全免费,最大支持 2GB 文件分享,不支持 Safari
RT ,平时临时传文件,非常不方便,就想着干脆做一个工具,功能不多:
上传文件 → 直接给你一个下载链接 链接默认有有效期(最长 7 天) 单文件最大 2GB 传输是加密的 不需要注册
基本思路就是: 不用管理、不存历史、不搞空间概念,用完就走。
目前我自己用下来还行,但也可能只是“自我感觉良好”,所以想请大家帮忙试试:
上传速度、稳定性怎么样(特别是国内的访问速度,由于服务器是在国外) 下载体验顺不顺 有没有什么明显缺的东西

作者: tfu | 发布时间: 2026-04-26 22:16
3. 第一次发帖,记录一下 claude code 被封禁经过
本人 claude 账号注册很久了,从 3.5 就开始用,一直开 pro 计划在用,今天升级 max 计划,刚消费完 125 刀,触发 KYC ,然后找小黄鱼代过 KYC ,直接封禁,目前正在申请 apple 退款,也不知道能不能把我的 125 刀退还。 近期不建议大家动 claude 计划 收到邮件如下: Hello,
Our automated systems detected a high volume of signals associated with your account which violate our Usage Policy. These signals were, in turn, reviewed by our team to validate our system’s findings. As a result, we have revoked your access to Claude.
To appeal our decision, please fill out this form or learn more about the appeals process here.
Regards
Anthropic’s Safeguards Team
作者: ruis | 发布时间: 2026-04-26 16:12
4. [开源] Patch Courier: Email 进来, Codex 在你的 Mac 上干活
最近在做一个本地优先的小工具 Patch Courier ,想解决一个很具体的问题:
人不在电脑前时,能不能继续把任务发给自己 Mac 上的 Codex 去跑,但仓库、凭据、审批和执行策略都留在本地。
TL;DR:这是一个 Email -> 本机 Codex -> Email 的 macOS daemon + console 。
现在的做法是:
- 收到可信发件人的邮件后,把一个 mail thread 尽量映射到一个 Codex thread
- 真正执行还是走本机
codex app-server- 审批、补充信息、完成结果继续通过邮件往返
- macOS app 负责看 threads / turns / approvals / mailbox health
- 状态持久化到 SQLite ,邮箱密码放 Keychain
我为什么做这个,而不是直接上云端 Agent:
- 有些代码库和 provider 凭据我不想交给第三方服务
- Email 很适合做异步审批、结果通知和审计留痕
- daemon 持有状态,UI 重启后线程和 approval 不会丢
当前已经跑通:
- IMAP / SMTP mailbox loop
- approval request / completion / failure 的邮件回发
- durable turn recovery
- sender policy / workspace scope / mailbox health
最近补的是 v0.2 的可靠性和恢复能力:重启恢复、重复 approval 邮件抑制、mailbox replay 去重、poll failure 持久化。
现在还是 pre-1.0 的 macOS 原型,更适合愿意折腾的开发者:
- 需要 macOS + Xcode CLT
- 需要本机装好 Codex CLI
- onboarding 还在继续补
仓库: https://github.com/owenshen0907/patch-courier
README (中文): https://github.com/owenshen0907/patch-courier/blob/main/README.md
如果你对这些方向有经验,想听听反馈:
- “邮件驱动本地 agent” 这个交互模型有没有价值
- approval / safety / sender policy 该怎么设计更合理
- 这类工具更应该先做邮件,还是先做 Slack / Matrix / 本地 Web inbox
如果方向对你有帮助,欢迎拍砖、提 issue 、提 PR 。
作者: owenshen456 | 发布时间: 2026-04-26 22:42
5. 关于视觉调教方面,国内安卓怎么和苹果差距这么多
PS:为了能找个替换当前苹果的方案,走遍各品牌手机旗舰店,看遍各种旗舰机型,然后发现接触了 IOS 的审美后,不知道为啥很难接受住国产的调教
期间去看了荣耀,华为,小米,vivo ,oppo ,一加,三星等机型发现一个致命的令我很不爽的点,就是视觉方面的
具体情况就是打开个常用的 APP ,譬如,今日头条,抖音,微博 1. 很统一严重的情况就是对比度特别大,白色的字体亮的刺眼,刺眼到 UI 界面,字体边缘和图片感觉不是同一个维度的东西,很跳跃 2. 然后字体布局有粗有大有小,整体比例调整就是没有 IOS 布局得那么和谐舒服 3. 图片视频显示方面,像那种国产 2000 元近距离看的电视一样,说好听点是通透,不好听的就是像 AI 过的一样,边缘很锐利,然后又确实细腻的细节,完全和苹果不是一个档次查看期间,其实我也关闭掉很多关于手机加强图片视频效果的功能,包括只显示原色,以及更换系统字体大小等功能,但是还是发现解决不了问题,期间,安卓这边勉强小米和三星,接近苹果的,三星手机做工以及审美还是国际在线的
同时我想问下,国内的调教这么恶心,国际版的安卓品牌,比如三星,谷歌,索尼,会不会调教方面,审美方面和苹果接近呢
作者: conpress | 发布时间: 2026-04-26 13:59
6. 为了买到便宜靠谱的 Token,少被割韭菜,我做了个比价的网站
最近在开发一个小项目,想买几个 ChatGPT 账号。
但是在多个卡网和电报群里转了几圈,发现同一种类型的账号,比如 ChatGPT plus 月卡,就有 N 多种价格。
有的几块钱,有的卖 15 ,有的卖 30 ,有的卖 40.
后来我才知道,这些店铺和卖家的来源其实就是那么几种:86 、chong 、xin 、74 这些。
他们都是加价后转卖的。
所以,为了尽快找到相对靠谱的渠道,少花几块钱,减少决策成本,我就做了个比价的网站,把多个平台的价格放在一起,快速对比。
目前收录了二十多个店铺+平台。
如果您有靠谱的渠道,也欢迎在网站提交、加电报群交流。
网址: https://aibijia.org/
电报: https://t.me/+z4dDCVFqx71jYTFlhttps://imgur.com/HsPagPw
https://imgur.com/G1BpVja
https://imgur.com/sv5WecN
https://imgur.com/ZsaKz2T
https://imgur.com/HOwgRot
作者: jzyzcz | 发布时间: 2026-04-25 07:44
7. kimi 订阅的 4x kimi code 指的是 kimi code 平台的 4 倍还是全平台 4 倍?
我看他们也支持其他编程平台,准备买个 4.6 给 CC 用。
作者: tankcong | 发布时间: 2026-04-26 13:00
8. 什么成品企业级 NAS 方便维修?
前情提要: https://www.v2ex.com/t/1200956#
电脑装好开机了,我有事就提前离开了,群晖系统镜像刚下到 Windows 上面。
电脑关机关了两周(后面没关),接的 ups ,ups 接的三孔,两周没断电
今天再点亮,表现出主板带电情况:
点一下电源键,电源和 cpu 风扇转一下就不转了。
然后经历漫长的放电操作,把电源线搞坏了:插上后(主机的电源侧)能听见电流声,风扇也不转了
出电流声之前的期间成功点亮进入了 BIOS 界面,但是把电脑竖放起来就黑屏了,风扇也不转了。
买了根电源线去尝试,新电源线不至于走一次放电操作从而风扇不转了。随后又是漫长的放电过程,也没放掉电,仍表现出主板带电。老板也没耐心了,想买成品 nas 了,当简单的沉没成本的。
放电过程:
拔掉电源线,关掉电源(主机侧),扣下电池和内存条,用电池(侧边)/钥匙/螺丝刀划电池槽的金属片(含短接相连),按住开机键几秒,放上电池和单根内存条,再按几秒开机键。插上电源线,打开开关,启动。买成品 Nas 有个问题:买到成品 Nas 也出静电问题怎么办,维修肯定比台式机难,这是个大难题。
Nas 需求:4-6 盘位,自动从 oss 上拉取数据到本地上。hdd 还没有购买。如果购买的话,SAS 与 SATA 不好选择。属于那种期望兼容后续买服务器的状态。至少在相当长的时间内,没有这个正经服务器需求。
作者: Censhuang | 发布时间: 2026-04-25 14:03
9. 有没有 jb 家自带的 git 的平替软件推荐
现在 jb 家的留着主要就是为了那个 diff 和解决冲突 功能,其他基本不用了,所以不太想专门为了这个续费
如果只是为了有 diff 和解决冲突 的这种相同体验的,有没有推荐的软件,至少 windows 和 mac 上要能用。可以付费,但最好是买断制的,有没有中文无所谓,jb 家这个解决冲突实在是太好用了
作者: Binwalker | 发布时间: 2026-04-26 05:48
10. glm5.1, kimi2.6, minimax2.7, mimo v2.5, deepseek v4,编程能力上的排名如何?
先抛个砖:GLM5.1 > deepseek v4 > minimax2.7 ≥ mimo v2.5 ≈ kimi2.6
作者: junwind | 发布时间: 2026-04-26 07:25
11. AI 编程实战: Claude Code + IDEA 的沉浸式编程方案
一、Claude Code 介绍
Claude Code 是 Anthropic 推出的面向开发者的 AI 编程协作工具,与传统的 Chat 模式不同,Claude Code 是一个能读项目、懂上下文、遵守约束的 AI 编程搭档。
Claude Code 核心目标是理解你的整个项目,并参与到真实的编码、修改和重构过程中,主要具备三点特征:
- 上下文感知:不仅理解单个文件,而是理解整个项目结构
- 工程化导向:关注可维护性、规范、测试,而不是一次性代码
- 可定制行为:通过 Skills (技能包)让 AI 遵守你的规则
二、Coding Plan 选择
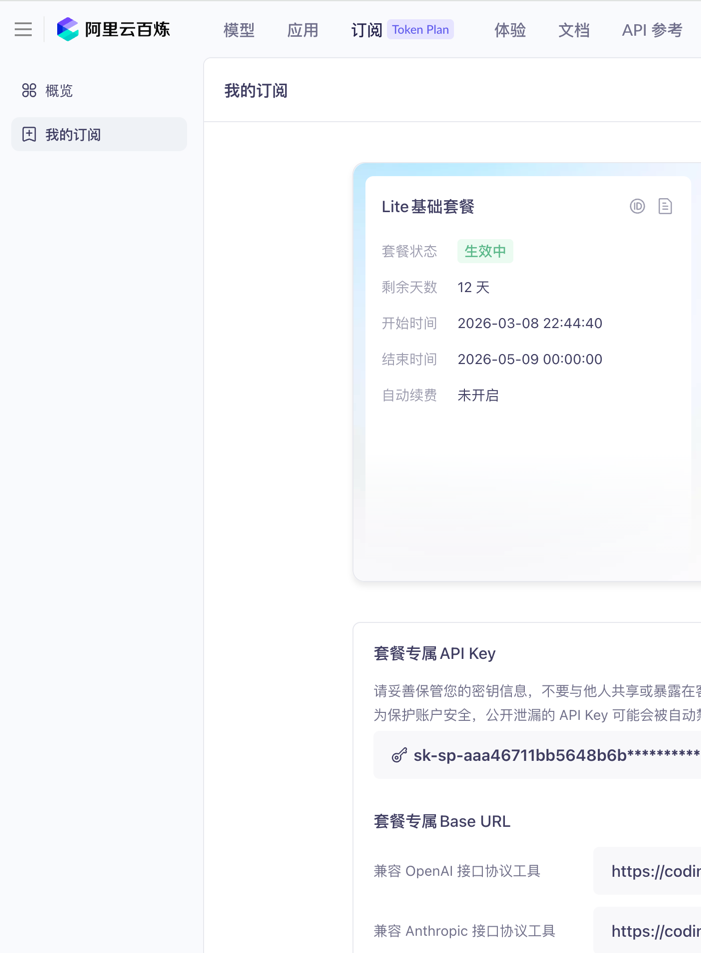
Claude Code 官方支持通过 Claude 订阅 或 Anthropic 账户 开通使用,同时也支持第三方提供商;本文以第三方 Coding Plan (阿里云百炼)为例进行讲解。
PS:业界存在多家兼容 Anthropic 协议的模型供应商,可参考选择:阿里云百炼、智谱 AI 、DeepSeek … 等。
三、Claude Code 安装配置
3.1 、Claude Code 命令安装
Claude Code 提供多种产品形态,Terminal 形态提供功能完成的 CLI ,用于直接在终端中使用 Claude Code 编辑文件、运行命令,并从命令行管理整个项目。
针对 Mac 用户可选择 Brew 方式安装:
brew install --cask claude-code3.2 、Claude Code 配置 Coding Plan
a 、初始化「流程配置文件」 :
~/.claude/settings.jsonvi ~/.claude/settings.jsonb 、编辑「流程配置文件」 :
将 YOUR_API_KEY 替换为 Coding Plan 专属 API Key ;保存配置文件,重新打开一个终端即可生效。
{ "env": { "ANTHROPIC_AUTH_TOKEN": "YOUR_API_KEY", "ANTHROPIC_BASE_URL": "https://coding.dashscope.aliyuncs.com/apps/anthropic", "ANTHROPIC_MODEL": "qwen3.6-plus", "ANTHROPIC_SMALL_FAST_MODEL": "qwen3.6-plus", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen3.6-plus", "ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen3.6-plus", "ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen3.6-plus", "CLAUDE_CODE_SUBAGENT_MODEL": "qwen3.6-plus" } }c 、 编辑或新增「客户端配置文件」 :
~/.claude.json将 hasCompletedOnboarding 字段的值设置为 true 。该步骤可避免启动 Claude Code 时报错:Unable to connect to Anthropic services 。
{ "hasCompletedOnboarding": true }3.3 、Claude Code 命令使用
打开终端,并进入项目所在的目录
cd path/to/your_project claude启动后,授权 Claude Code 执行文件
Quick safety check: Is This a project you created or one yuo trust? ... > 1. Yes, I trust this folder 2. No, exit输入
/status确认模型、Base URL 、API Key 是否配置正确。然后,可以在 Claude Code 中对话使用。3.4 、Claude Code 常见命令
命令 说明 示例 /init在项目根目录生成 CLAUDE.md 文件,用于定义项目级指令和上下文。 /init/status查看当前模型、API Key 、Base URL 等配置状态。 status/model <模型名称>切换模型。 /model qwen3-coder-next/clear清除对话历史,开始全新对话。 clear/plan进入规划模式,仅分析和讨论方案,不修改代码。 plan/compact压缩对话历史,释放上下文窗口空间。 compact/config打开配置菜单,可设置语言、主题等。 config四、IDEA 集成 Claude Code
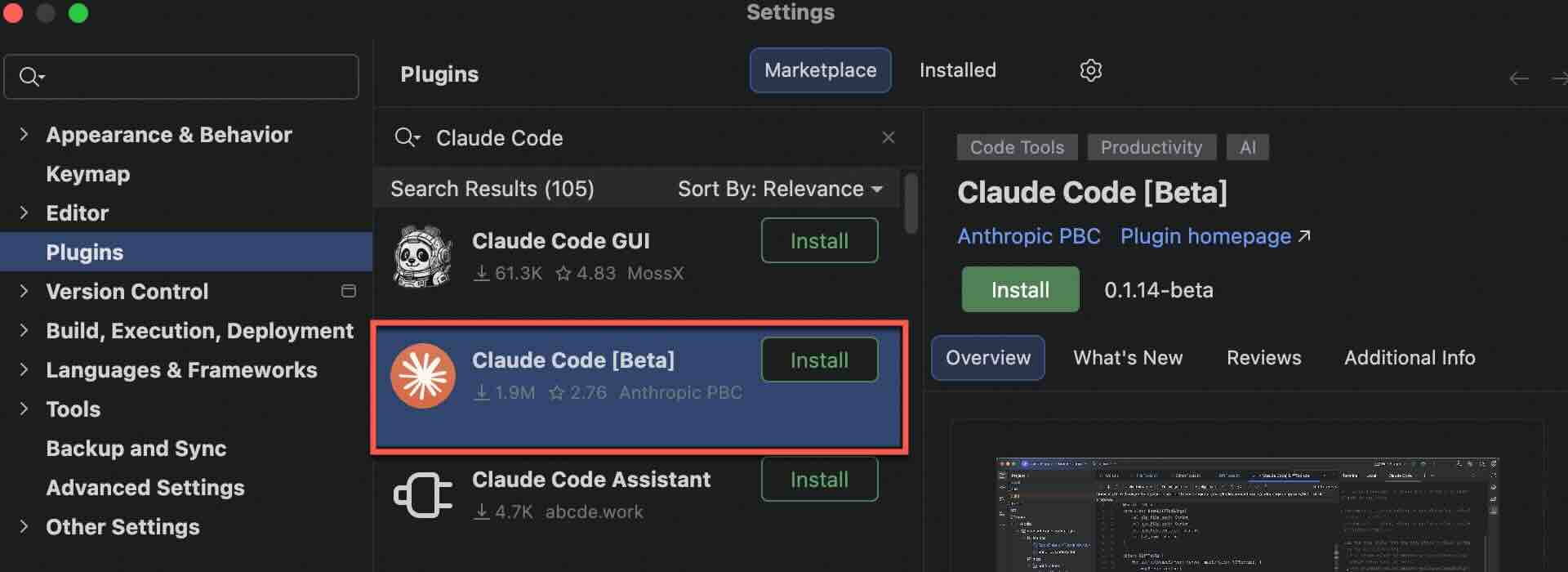
Claude Code IDE 插件支持在 JetBrains 系列 IDE 中使用。
打开 JetBrains 扩展市场( Setting -> Plugins -> Marketplace ),搜索 Claude Code 插件安装即可。
安装后重启 IDE ,单击右上角图标即可使用,可通过
/model <模型名称>命令切换模型。
五、实战演示
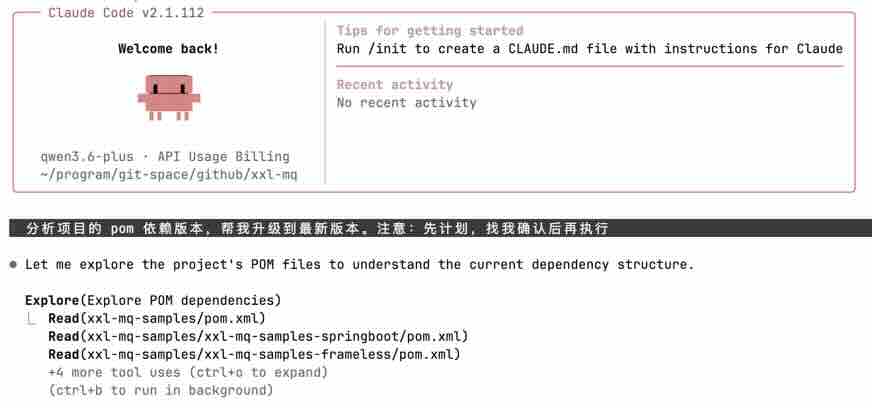
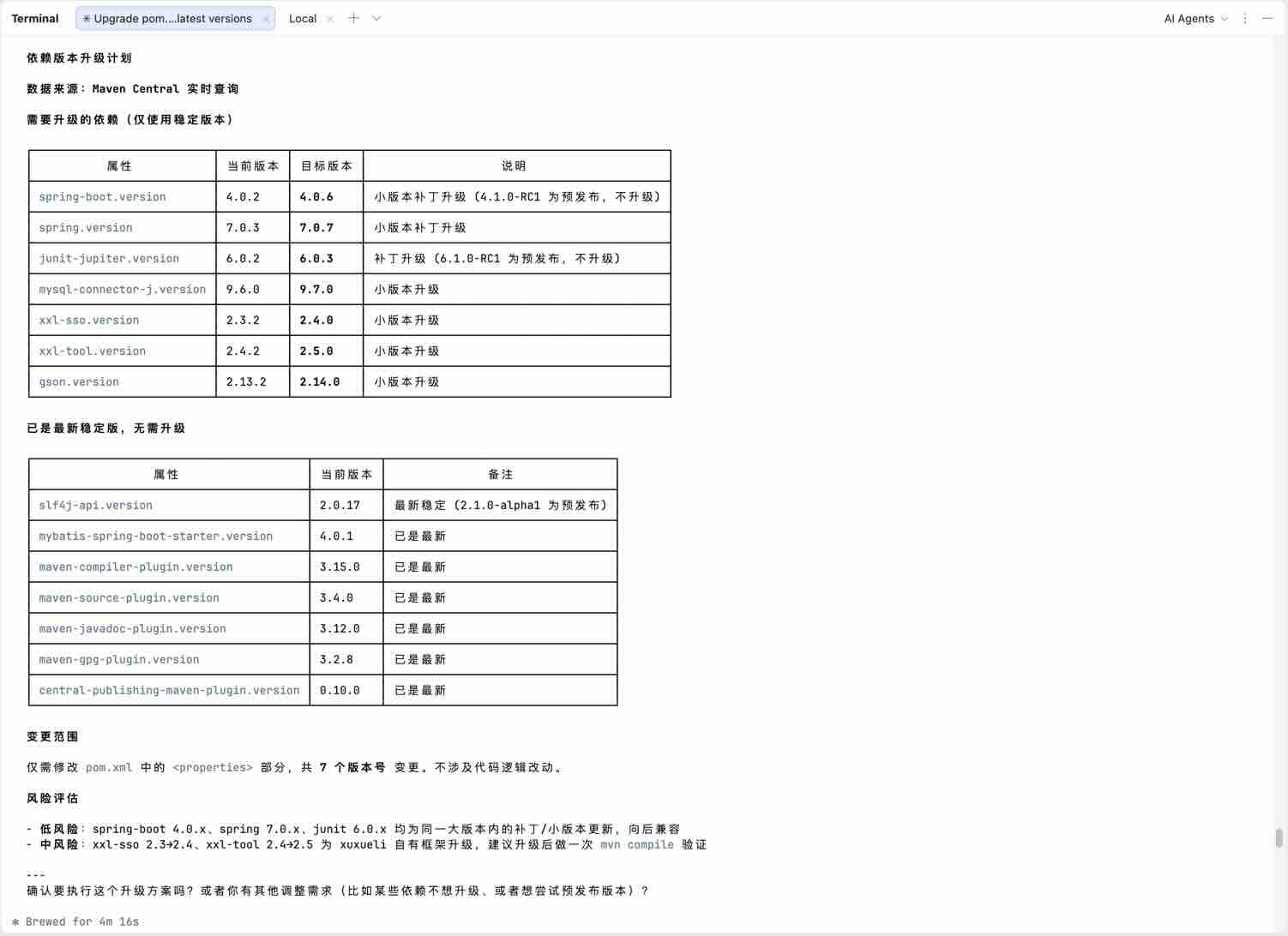
a 、发布任务:
- 任务描述:“分析项目的 pom 依赖版本,帮我升级到最新版本。注意:先计划,找我确认后再执行”
- 补充说明:为避免任务执行偏离目标,强烈建议「先计划,再执行」,参考文末最佳实践建议。
b 、生成计划:
Claude Code 接受任务后,将会按照要求生成执行计划:
1. 扫描项目依赖关系,并生成依赖树。1. 使用 Web Search 查询 Maven Central ,获取每个依赖的最新版本。1. 生成修改建议,列出需要升级的依赖及其新版本。1. 等待用户确认后,修改 pom.xml 文件,升级依赖版本。
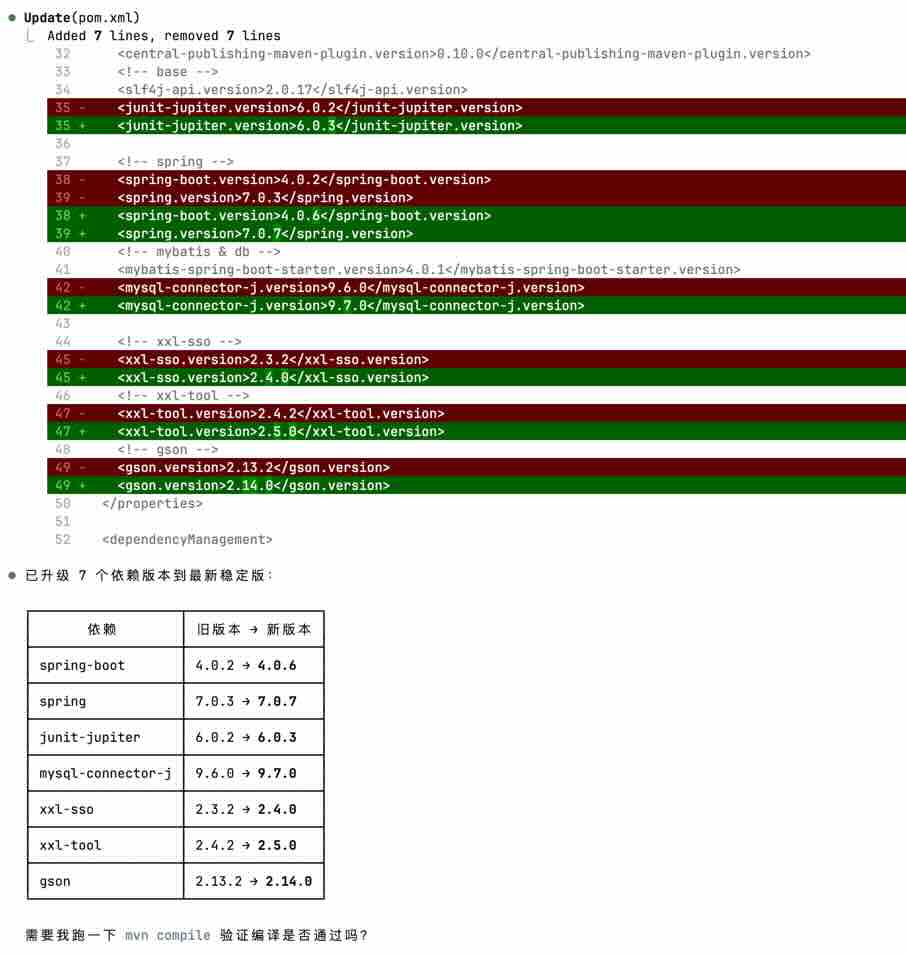
c 、执行计划:
Claude Code 生成执行计划后将输出修改建议,用户确认后 Claude Code 将会修改 pom.xml 文件,进行依赖版本升级。
六、最佳实践
6.1 、上下文管理
- 及时清理: 使用 /clear 定期重置对话,防止旧的上下文干扰新任务并节省 Token 。
- 主动压缩:使用 /compact 命令让 Claude 总结关键决策和修改的文件,保留核心记忆。
- 明确指定文件: 提问时使用 @ 引用文件(如 write a test for @auth.py ),避免模型无效扫描整个项目。
- 善用子代理( Sub-agents ): 对于大规模任务,让 Claude 启动子代理执行。子代理完成任务后返回精炼结论,保护主对话的上下文空间。
6.2 、先计划,再执行
- 启用 Plan 模式:复杂任务前,先分析方案,不实际修改文件。
- 快捷操作:连续按两次 Shift + Tab 进入 Plan Mode 。
- 提示词约束:提示词明确要求“先输出详细实施计划,经我确认后再修改文件”。
- 降低试错成本:确保逻辑闭环后再进行代码变更。
6.3 、沉淀项目核心知识:编写 CLAUDE.md
- 包含关键信息:每次会话启动时自动加载 CLAUDE.md ,建议填入构建命令、代码规范及工作流等通用规则。
- 动态维护:内容应简短易读,仅记录广泛适用的全局约定,并随项目演进持续补充新规则。
6.4 、扩展能力:MCP 与 Skills
- MCP:安装成熟的 MCP Server ,连接外部服务。例如:添加联网搜索 MCP。
- Skills:编写详细的 Skill 描述文案。Claude 决定是否调用该工具,取决于对该工具用途的定义。例如:添加视觉理解能力 Skill。
6.5 、自动化守护:Hooks
- 使用 Hooks:Hooks 是确定性规则。它在 Claude 工作流的特定生命周期节点(如 PreToolUse 工具执行前校验等)自动运行本地脚本,确保关键校验或操作 100% 执行。
- 配置方式:
- 运行
/hooks进行交互式配置。- 直接编辑
.claude/settings.json- 让 Claude 帮你编写,如:“编写一个在每次文件编辑后运行 eslint 的 hook”。
6.6 、建立自检闭环
- 强制验证: 要求 Claude 修改代码后,必须运行相关的测试用例(如 pytest 或 npm test )。
- 定义成功标准: “修改完成后,请确保编译通过,并且运行 curl 命令验证 API 返回值为 200”。
- 视觉反馈: 前端修改时,要求 Claude 截取浏览器截图来确认 UI 效果。
七、资料
作者: xuxueli | 发布时间: 2026-04-26 07:49
12. Codex agentic loop 会导致代码严重膨胀,有人遇到吗?有没有系统性的解法?
具体案例:V2EX Safe Reading Helper 5.3.0,一个油猴脚本,核心逻辑不复杂,但 530 行里能清楚看到几层叠加痕迹:
- topic 来源从 API 一路加到
/recent、节点页、ID 逐个扫描——每次拿不到帖子就加一个 fallback ,互相没有合并- 两套 refill 防重入并存(
isRefillingflag +refillPromise互斥)- legacy key 迁移代码永远留在运行时,跑一次之后就是死代码
hasGMStorage()每次读写都检测,而不是初始化时确定一次- 对一个翻页脚本加了完整的白屏 watchdog + 自动刷新恢复机制
模型每次报错就往上堆,不回头清理,不合并逻辑。
有没有系统性的解法?还是说这就是现阶段 agentic coding 的固有缺陷?
作者: longxinglink | 发布时间: 2026-04-26 08:40
13. 谈谈用 Claudecode 辅助创建一个 shopify 网站需要多久,多少钱
网站已经搭建出来并顺利上线了:网址 ineanplay.com ,这是一家出售自动 OKEY 桌的网站。
在搭建之前咨询了大概费用: 前同事收 2500 ,咸鱼 700 ,淘宝 1500 。
最后选择尝试用 AI 来解决问题,选择了 claude sonnet4.6 给了我技术方案,最终方案使用 shopify 的自订 liquid 功能,由于我不是 claude 的付费用户,再他给完第一个示例代码,我填写进去测试通过后,后面我就使用的 gemini pro 仿照这个代码做了其他页面。
总计花费 98 元,一个 gemini 学生年费。你们的项目有什么,运行起来了吗?另外想问的是,现在网站搭建起来了,我应该做些什么才能获得流量呢,好像并没有哪个 Agent 可以上手一次性跑通关于广告投放的事例,你知道吗?
作者: neword | 发布时间: 2026-04-26 09:04
14. 每天 800 美金 token 搓了几个小产品
20x 套餐这样蹬会不会用太猛了…… 搓了几个小产品: 1 、加密/美股,组合+跟单+API ,不敢上线,自己玩 2 、A 股,量化实验室( ai 写的介绍:Copilot”四合一研究终端:用 AkShare 延迟数据 + 私有 JupyterLab 沙盒写策略,跑参数优化时自动叠 CVaR/WF 三模式共识/MC 爆仓概率四道硬闸,还原 IOC vs 市价滑点 + funding regime + A 股印花税等真实摩擦,AI Copilot 中文答疑但严守”不荐股 / 不带单 / 不发实时行情”三死线——拒绝聚宽式”理想化回测幻觉”,给你 1 年实盘踩坑沉淀的”实战可信度评分”。) 3 、链上安全审计( ai 写的介绍:Web3 智能合约审计自动化平台 — 给地址或仓库就能跑全套工具扫描,11 个 AI 模型( Claude/Gemini/Grok/DeepSeek )任选给每个 finding 出修复 patch ,再用 AI 综合成 PR-ready 审计报告。代理跟随、跨链批量、升级监控、定时扫描、TG 告警全自动。)




作者: reitao | 发布时间: 2026-04-26 05:25
15. 做了一个 RAG 流,产品文档 AI 客服工具,昨天刚上线在内测,分享一下,希望大佬们提点意见🙏
最近给自己做的 SaaS 还有朋友的公司,写了个 AI 客服 widget ,干脆做成平台,上传文档就能生成一个嵌入网站的聊天机器人。回答只基于上传的文档,每条回复都会附来源引用。主要是不想再一遍遍回答同样的支持问题了。
技术栈是 Nextjs, MongoDB, Qdrant ,标准向量 RAG 管线,远程 LLM, 大约核心流程 Vibe 了一周多,整体准备内测上线快一个月时间
目前在 public beta ,免费计划够用,收费档位也还没完全定下来,边用边调。
有兴趣的可以试试看: https://kodda.dev
昨天才上线,还没走宣发程序,准备这几天找几个朋友试试修修核心 BUG ,idea 不新,老玩家也好几个了,不确定市场如何,欢迎提意见。
作者: onedge | 发布时间: 2026-04-26 13:39
16. 还得是 Claude
我之前并不是 claude 的忠粉,用过一个月 pro ,也同时订阅 gpt plus ,glm pro ,因为 cc 价格高,之后一直在国产 glm5.1 为主力,实话实说日常大部分线性开发都没大问题,最近在给一个 app 的( ios 相机类)修美颜功能的 bug ,给了给多参考文章,codex5.5 最高思考,glm5.1 都没能完美解决,直到我说算了吧最后用 opus4.7 试试吧,它一次性就完美解决了,我觉得这就很能说明差距了,你要说差距很大,那不至于,但就是这攻坚的场景,其他人就是不行!
作者: onedge | 发布时间: 2026-04-26 04:26
17. AI 时代,真的可以按需定制
在 AI 帮助下,crTerm 终于实现终端内的图片预览和窗口截图
还添加了支持 tab 页的 icon 和 title 设置
以后我在 AI coding 的时候方便交互,有些需求还来自 V 友
crTerm 原生支持 chrome theme 和 extension
希望下个礼拜可以顺利发布 MacOS 版本
作者: wuruxu | 发布时间: 2026-04-26 15:38
18. 如何将 figma make 的原型尽量 100%的还原到 cursor 中
前言:使用 stitch google 生成的页面的效果比 figma 好,但是 figma 可以直接生成原型,所以我在 stitch 生成的页面,然后复制到 figma 生成原型
问题:在 figma 生成原型后,使用官方 mcp 或者其他 mcp 都不能在 cursor 中“还原”,大家是否有一些原型到代码的技巧,请教一下!
作者: Xbathy | 发布时间: 2026-04-26 06:33
19. 各位推荐一个 32G Macbook air M5 可以跑的 moe 模型
27B/31B 甚至 35B 的 4bit 都可以, 测试了好久, 也下载了几十个了,都不太行, 感觉降智了, 这些刚出来的时候我这个配置能跑到 35tokens/s.
准备直接抄作业, 请给 huggingface 连接, 我的本地推理框架是 omlx, 感谢感谢.
作者: Hermitist | 发布时间: 2026-04-26 00:16
20. chatgpt 充值 5x pro 前已经订阅了 plus,那 plus 的 20 刀就没了吗
我在升级 ChatGPT 5x Pro 前,已经通过 iOS/App Store 订阅了 ChatGPT Plus (扣款 $20 )。
因为 iOS 端没有看到可以直接订阅 ChatGPT 5x Pro 的入口,所以我先订阅了 Plus 。随后我又升级到了 ChatGPT 5x Pro (扣款 $100 )。
我想确认:
我看到之前 Plus 的 $20 是没有自动抵扣到 5x Pro 订阅费用里的,Plus 的 $20 是否可以退款呢?
作者: keep1234 | 发布时间: 2026-04-26 03:06
21. 5.1 香港旅游,众安银行开户 额外返现 300hkd
邀请代码:HCEAD7
电报:@fgvbt123



作者: fgvbtttt | 发布时间: 2026-04-26 12:57
22. 有人用过 vmlx 吗? 这几天吹它的人比较多, 感觉可以直接替代 Omlx 直接在 Macbook 上跑了.
有用过的人能给点意见吗?
作者: Hermitist | 发布时间: 2026-04-26 06:40
23. ai 编码业务功能验收的正确流程
在 AI 实现自动化编程时,任务编写完成后,工程质量检查( lint 、类型检查、单元测试)都正常通过。但是在业务功能验收时,存在业务功能验收通过了,但是实际功能并没有实现的问题,例如:数据根本就没有正确显示。请教各位大神,如何更好的做 AI 自动化的业务功能验收。
需求文档模版:
# 需求文档 ## 介绍 需求描述 ## 需求 ### 需求 REQ-001 - 用户登录 用户故事:用户故事内容 #### 验收标准 - id: REQ-001-AC-001 ears: 采用 EARS 描述的子句 While <可选前置条件>, when <可选触发器>, the <系统名称> shall <系统响应>, - id: REQ-001-AC-002 ears: 采用 EARS 描述的子句 While <可选前置条件>, when <可选触发器>, the <系统名称> shall <系统响应>,任务 task 模版:
# 实施计划 执行时需严格遵循 `docs/spec/requirements.md` 中对应需求和验收标准。每项任务通过引用相关需求编号。 ## TASK-001 用户登录功能 - [ ] - 关联需求: - REQ-001 - 关联验收: - REQ-001-AC-001 - REQ-001-AC-002 - REQ-001-AC-003 ### 实施内容 1. 创建登录表单 2. 实现登录 API 调用 3. 处理 loading 状态 4. 处理错误提示 5. 登录成功后跳转 dashboard ### 测试要求 - 单元测试: - 表单校验 - 登录成功 - 登录失败 - E2E 测试: - 用户可完成登录流程 - 错误密码显示提示 - loading 状态防止重复提交 ### 规范对齐:constitution.md 「 UI/UX 一致性」「工程化规范」; design.md 「项目结构」「核心模块设计」「国际化」
作者: manbudezhu | 发布时间: 2026-04-26 04:58
24. 你们一个月上班要用多少 token?
如题,我上个月用了 200M ,主要是 GPT5.4 和 Gemini3.1Pro
作者: exploretheworld | 发布时间: 2026-04-25 07:45
25. 大模型终于不卷跑分,改卷打工了!
这两天我刷帖子刷得有点懵。
4 月 20 号,Kimi 悄悄放出 K2.6 。4 月 23 号,腾讯混元 3.0 开源,小米 MiMo-V2.5 同一天公测。4 月 24 号,DeepSeek V4 Preview 上线。大洋彼岸那边,GPT-5.5 、Claude Opus 4.7 接连发出,image2 火遍全网。
我数了一下,就这 7 天,至少 6 个万亿参数级别或者准万亿级别的模型同时在线。
这种密度,大模型火了这三年,一共都没见过几次。
热闹归热闹,我发现一件有意思的事。
大家聊的东西变了。以前一个新模型出来,讨论区清一色的「几分」「跑分第几」「 MMLU 多少」。现在呢?我刷了两天帖子,发现讨论最多的不是谁更聪明,而是两个特别具体的问题。
一个是「它能帮我干什么活」。
一个是「用它要花多少钱」。
傅盛之前在节目里做过一个大致测算,要想大模型产生生产力,一个人每天花在买 token 上的钱,大约是 10 美元,我的体感与此类似。
顶尖的模型做出一流的工作,一流的模型做出二流的工作,其他模型做出来的就很废了。
所以你看,这背后其实就是两件事,产能和成本。
这两个词,恰好对应了这波神仙打架里我最想聊的两个选手。
DeepSeek V4 和 Kimi K2.6 。
一个把「 AI 能帮你干多少活」这件事往前推了一大步,一个把「用 AI 要花多少钱」打到了一个让人不敢相信的地板价。
而且这两家之间有一段特别有意思的关系。K2.6 的架构用了 DeepSeek 的 MLA 注意力机制,V4 的训练用了 Kimi 的 Muon 优化器。两家公司最后的深层交汇点,居然是芯片。
这不是段子。这是 2026 年中国 AI 行业让人觉得「能打」的那个部分。
我觉得这件事值得好好聊聊。先说模型,再聊体验,最后我们聊开源。
DeepSeek 做到了啥
先聊 DeeSeek V4 。
DeepSeek 的路线,我给它取了个名字叫「基础设施路线」。单点极致,不做多模态,不做花哨的 C 端交互,所有力气花在推理和编码上,然后把 API 定价打到地板。
V4 Pro 的定价,输入$1.74/百万 token ,输出$3.48/百万 token 。
GPT-5.5 呢?输入$5 ,输出$30 。
Mashable 算了一笔账,V4 比 GPT-5.5 便宜大约 85%。VentureBeat 的说法更直接,大概是 GPT-5.5 的七分之一,Opus 4.7 的六分之一。
V4 Flash 更离谱。输入$0.14/百万 token ,输出$0.28/百万 token 。Cline 的 CEO 算了一笔账说,如果 Uber 用 V4 替代 Claude ,它 2026 年的 AI 预算本来只够用四个月,换成 V4 够用七年。
七年。
这就是 DeepSeek 的风格。你要造什么都行,我负责把成本给你打下来。
(这里说明一下,由于没有查到 K2.6 价格,这里通过公开数据计算得出)
这对 Agent 场景的意义太大了。一个 Agent 跑长任务的时候,每个工具返回的结果都会追加到上下文里,上下文越来越长,每生成一个新 token 都要对前面所有内容做一遍注意力计算。如果这个成本降不下来,100 万 token 就是个摆设。V4 在这块做的事情,其实是在给整个 Agent 生态铺路。
当一群 AI 开始帮你干活
K2.6 走的是另一条路。
坦率的讲,K2.6 让我真正兴奋的不是模型本身有多强。强不强,数据摆两个你自己看。
OpenRouter 编程能力日榜第一。
Artificial Analysis 的 Intelligence Index 给了 54 分,全球第四。前面三个分别是 Claude Opus 4.7 、Gemini 3.1 Pro 、GPT-5.4 ,而这四个里面,仅有 K2.6 是开源模型。
火了一段时间了,模型配置我就不摆了,大家应该都看到了。
真正让我坐直的,是跑在 K2.6 上面的两个功能。
一个叫「 Agent 集群」。一个叫「 Office 文档转 Skill 」。
翻译翻译,一个叫产能,一个叫标准。
Agent 集群,这个架构跟 Anthropic 今年 2 月在 Claude Code 里上线的 Agent Teams 异曲同工,但 Claude 那个是给开发者用的,得敲命令行配 settings.json ,产物主要是代码。K2.6 的 Agent 集群面向所有人,说句话就行,交付的是 PDF 、PPT 、Excel 、Word 这些办公产物。
同样的群体智能方向,截然不同的答卷。
现实世界里,一个真正复杂的项目是怎么完成的?不是一个天才坐在那里从头干到尾。而是一个团队,产品经理定方向,设计师出视觉,工程师写代码,分析师跑数据,每个人各司其职,并行推进,最后汇总交付。
Agent 集群做的就是这件事。
它不再是一个 Agent 在那里单打独斗了。K2.6 驱动的 Agent 集群架构迎来一次大升级,现在支持 300 个子 Agent 并行完成 4000 个协作步骤。其实 Agent 集群在 K2.5 就有了,但这次我是真的觉得,它达到了生产级。
Kimi 官方文档里说了,最多可以有 300 个 Agent 一起干活。
既然如此,我不客气了。必须拉满。
请看我的提示词。
从思维链中可以看到,它立刻生成了一堆子 agent 开始安排任务。
过程中能够看到,始终有两个子 agent 在总揽全局。
第一次跑通的时候,说实话愣了好几秒。
因为它输出给我的不是一个数据模拟器,而是有过程、有可视化呈现、有结果报告的全方位展示。
甚至还有意见领袖上台演讲。大家可以看一下辩论过程呈现网页中的这一部分,有演讲大纲、说服网络、达成效果。我感觉自己不是在和 AI 对话,更像是站在一个 300 人的报告厅里听辩论。
这还没完。总输出物是一个辩论过程网页呈现、一个辩论 PPT 报告,还有一个 33 页的混合架构白皮书。
大家可以看一下这个白皮书。
我当时的反应不是「哇好厉害」,而是一种很奇怪的恍惚感。
当你第一次看到 AI 也开始协作的时候,那种感觉其实挺奇妙的。你不是在用一个工具。你是在旁观一个组织开始工作。
甚至它还做了成本分析和对比。
AI 开始雇佣 AI 了? AI 也开始计算人效比?
后来我又试了几个场景。
例如我要制作一个包豪斯风格的日历,直接告诉它需求,它就开始分步骤,给不同的 Agent 安排活儿。
出来的是中英文配套、审美在线的日历图,并且还配了一个 PPT 产品展示。
每次看到这些产物一次性弹出来的时候,我都会想起一个数字。
广告公司一个项目组做类似的事情,大概需要 100 个小时。
Agent 集群需要多久?
大概 30 分钟。
前两天我和一个深度 ChatGPT 用户的朋友聊天,他感叹了一句,Pro 的活儿是真好,慢也是真慢,贵也是真贵。
ChatGPT Pro 之所以有这样的效果,核心原因是它有非常长的思维链,大模型在不断回溯之前的结果,不断修改。此刻我有了使用 Pro 的感觉,Kimi 用多 Agent 的方式做到了同样的事。
100 个小时和 30 分钟。记住这个对比,后面还会用到。
回到 Skill 这块。
Skill 满天飞,但我觉得它是最容易被低估的一个东西。因为真正决定交付质量的,往往不是你有没有灵感,而是你有没有稳定的方法。
K2.6 的「 Office 文档转 Skill 」功能,把这件事做得极其简洁。
把你认为最好的那份产物,一份顶级研报、一份精美的 PPT 模板、一份专业的财务分析表,直接发给 Kimi Agent ,它会自动深度学习这份产物的结构、风格、排版、配色和逻辑,然后生成一份对应的 Skill 。
以后你每次让 Agent 集群干活的时候,调用这个 Skill ,产出的东西就会自动对齐那份顶级产物的标准。Excel 、PDF 、Word 、PPT ,全格式支持。
Skill 加上 Agent 集群,等于标准化批量交付。
这两个功能合在一起,才是 K2.6 真正的杀手锏。
DeepSeek V4 vs Kimi K2.6
聊到这儿,一个有趣的问题出现了。
K2.6 和 V4 ,到底谁更强?
坦率的讲,这个问题本身就问错了。它们走的是完全不同的路。
K2.6 是系统优化路线。模型加产品加 Agent 一起上,原生多模态,能处理文本、图片和视频,Agent 集群能力是它最重要的差异化。它想做的是 AI 时代的操作系统,让每个人都能调度一个 AI 团队帮自己干活。
V4 是基础设施路线。单点极致,100 万 token 上下文,API 定价打到地板,不做多模态,专注推理和编码。它想做的是 AI 时代的水电煤,让所有开发者和企业都能用最低成本跑最强的模型。
一个面向所有人说「你只要开口,剩下的交给我的团队」。
一个面向开发者说「我把成本给你打下来」。
而且正因为走的不同,才有了我开头提到的那段有意思的关系。
DeepSeek V4 的训练,用了 Kimi 的 Muon 优化器。月之暗面团队在万亿参数规模上验证了 MuonClip 的训练稳定性,预训练全程零 Loss Spike 。DeepSeek 看到效果,直接拿来用了。
Kimi K2.6 的架构,用了 DeepSeek 的 MLA 注意力机制。Multi-head Latent Attention ,通过对投影矩阵做低秩近似,把 KV Cache 的压缩率做到了 93%以上。翻译成人话就是,推理时占的显存大幅降低,同样的硬件能跑更大的模型。
这两个技术创新都不是偷来的。是光明正大地、通过论文和 GitHub 拿来用的。
你品品这个事。
两家中国最顶尖的 AI 公司,各自拿出了自己最核心的技术创新,开源出去,然后对方在下一代模型里直接用上了。
开源正在改写游戏规则
顺着这个再往深聊一层。
很多朋友可能会问,互相用对方的技术,那护城河在哪?如果谁都能用你的东西,你凭什么比别人强?
这个问题问得好。但它基于一个旧世界的假设,就是「技术是排他性资产」。
在闭源体系里确实是这样。你发明了一个牛逼的注意力机制,那是你的护城河,你得申请专利,设置使用限制。
但在开源体系里,逻辑完全不同。
你发明了 MLA ,全世界都能用。但你的团队因为最先使用它、最理解它的设计意图、在工程实现上跑得最远,所以你天然领先。护城河不是「你有什么别人没有的」,而是「你能比别人更快地把最新的技术整合到下一代模型里」。
这有点像 Linux 。Linux 从来不属于任何一家公司。但基于 Linux 构建的生态,支撑了整个互联网时代。Red Hat 、Google 、Amazon ,都在 Linux 上面建了自己的商业帝国。它们的护城河不是 Linux 本身,而是在 Linux 之上构建的独特能力。
DeepSeek 和 Kimi 正在做的事情,是在共同浇筑中国 AI 的「 Linux 」。
回头看看大洋彼岸在干什么。
当时看到 OpenAI 创始人和 Claude 创始人两人合照用手势对立的时候,当时第一反应是。。。你们认真的吗?
怎么说呢,有点像小学生吵架。
我不想把这个事情上升到什么宏大叙事,什么制度优越性,那太扯了。但有一个事实是很难反驳的,当技术通过开源代码自由流动的时候,整个生态的进化速度,是封闭生态没法比的。
DeepSeek 的 MLA 发明出来之后,不只 Kimi 在用,全世界的开源模型都在用。Kimi 的 MuonClip 验证成功之后,不只 DeepSeek 在用,学术界和其他公司也在跟进。每一个技术创新都在被以最快的速度吸收、改进、再释放出去。
还有一条很多人没注意到的暗线。
H20 已经断供一年了。推理芯片短期内只有国产一个选项。
Kimi 上周末发了一篇论文,叫 Prefill-as-a-Service 。简单来讲就是,它用 Kimi Linear 混合注意力架构把 KV Cache 的传输需求压到了极低的水平,然后把 Prefill 和 Decode 两个阶段解耦到不同的异构集群,甚至可以跨数据中心。实验结果是吞吐量提升 54%,P90 TTFT 降低 64%。
论文里有一句容易被忽略的话。
这个方案对「算力强但显存容量和带宽有差距的国产卡」特别友好。
与此同时,Fortune 的报道提到 DeepSeek V4 正在跟华为芯片做紧密整合。
你看到了吗?两条线又汇到一起了。
Kimi 用新架构为国产芯片打开了推理的大门。DeepSeek 可能成为第一个在国产芯片上大规模部署的万亿参数模型。一个从软件侧降低硬件要求,一个从应用侧直接适配硬件。
殊途同归。
黄仁勋前阵子在 The Dwarkesh Podcast 上被问到禁止对中国出口芯片这件事,他说了一句很耐人寻味的话,芯片又不是铀浓缩,禁售阻挡不了中国芯片的进步,他们依旧可以通过国产芯片暴力堆叠来开发模型。
DeepSeek 和 Kimi 的下一步,就是标准答案。
其实写到这里,我本来想收了。但有一个念头一直在脑子里转。
这一周发生的事情,表面上看是几个模型在打架。但往后退一步看,你会发现一个更大的图景正在成型。
过去三年,我们一直在跟 AI 「聊天」。一问一答,一来一回。这个交互模式让我们不自觉地把 AI 想象成「一个人」。
但这一周的发布,不管是 K2.6 的 300 个子 Agent 并行,还是 V4 的 100 万 token 长上下文,还是 Claude 的 Agent Teams ,它们指向的都是同一个东西。
AI 不再是「一个聪明人」了。
它开始变成一个组织。一个能拉群、能分工、能协作的组织。
还记得前面那个对比吗?广告公司 100 个小时,Agent 集群 30 分钟。V4 把推理成本打到地板,让这种大规模协作在经济上可行。K2.6 把 Agent 集群做成产品,让普通人也能调度这种协作。
一个在铺路,一个在开车。
我不确定这到底会走向哪里。但我确定的是,当 DeepSeek 和 Kimi 各自交出这样的答卷,而且还在互相借力往前跑的时候,这场游戏的走向,已经跟很多人想的不一样了。
历史不会简单重复。但它会押韵。
















作者: dearzhzhao | 发布时间: 2026-04-26 15:27
26. 如何根治 Claude 在编译 C++时自作聪明的问题
用的是 GitHub Copilot Claude Sonnet 4.6 ,已经在 copilot-instructions.md 里面写了 please redirect building log to a temporary file instead of using tail or grep.
每次编译的时候,只要因为模版导致报错信息过长,AI 就会无视我的指令,无限的自作聪明重复这个弱智行为:
1. 先 tail 20 行,什么也没看到,然后再编译一次 tail 50 行,还是什么也没看到。
2. 再编译一次,用 grep | err ,真正的错误信息还是被淹没。
3. 最后实在没办法了,才去/tmp 写入临时文件。
我大概能猜到这是跟 agent 内部要缩短上下文的机制冲突了,如何根治?
作者: xuegy | 发布时间: 2026-04-25 12:37
27. 2026 年,选择 Podman 还是 Docker
Docker 对于大多数自托管应用支持的比较好,个人使用也基本熟悉了。 Podman 的无守护进程和默认的 Rootless 很好用,在服务器上测试部署了一个服务,感觉还挺好的。
作者: DejavuMoe | 发布时间: 2026-04-24 10:12
28. 大项目中大家真的会用 Spec-Driven Development 吗?
https://openai.com/zh-Hans-CN/index/harness-engineering/ 中提到要把 Spec & Planning & Tasks 进度放进 git 仓库中,大家实践中真的会这么做吗?但是我看 codex 仓库内根本没这些东西,而且很多 Spec 他们都是放在的 Issue 中讨论的。
我自己也用 Openspec ,但实际使用中各种地方不顺手
- openspec 会自己生成一堆 design & propsoal 很多都是正确的废话,给人 Review 就很困难,找不到重点
- 执行完还是有些 Bug ,这种再写回到 Spec 让他修复感觉很 tricky ,明明是 AI 特定问题,结果却要写到给人看的文档中。
- 生成的 Spec 你要严格按照他的流程来,执行 Task 等等。但是加上 Bug 修复。总时间感觉不如用 Planning 功能,再加少量提示词修正顺手,还不用考虑后续文档和代码对不上的问题。
- 据说有人碰到过 Spec 合并 delta 对不上的问题。
请教一下大家日常怎么实践的?
作者: CodeY99 | 发布时间: 2026-04-25 00:22
29. 请教一个关于模型训练主机配置的问题
主要是用来部署
YOLO26做数据集训练和目标检测或追踪的,图片数据暂定 5000 张(其实数据有很多,但是暂定用于训练的数据上限是 5000 张)。目前有一台 RX6600xt ,但是 directML 好像也不能使这张卡参与训练计算,上网查了一下好像是对 7000 系列以上的显卡支持的更好一些。
所以老板的意思是重新配一台 N 卡主机,但我之前没有使用 YOLO 训练的经验,不知道目前这个数量级的数据训练以及这个体量的模型该使用什么卡。咨询官网 AI 的话,就是无脑推荐 4090 、5090 这种大显存的卡。搞得我很头疼~
关于预算的话,老板只说了一句你看着办吧。但之前老板的意思是让我看看能不能把现在这台主机的显卡换成 RTX5070 ,后来我查了一下现在主机的电源,才 500W ,带不动 5070 ,才有了配新主机的这件事。所以我想着写个两三套配置单给老板看,低配高配都写一下,让老板决定选什么。
有没有有
YOLO 训练+目标检测经验的 V 友给点建议?跪谢了~
作者: jamme | 发布时间: 2026-04-25 15:02
30. OpenCode GO 已上线 deepseek v4
5 小时限额 pro 1300 次, flash 7450 次
理论上可以用于其他工具比如 claude code ,opencode 说 go 可以用于第三方。
作者: defaw | 发布时间: 2026-04-25 04:21
31. 我做了个工具让 8GB 显卡跑 30B 模型从 3 tok/s 提到 21 tok/s,记录一下技术发现
最近在折腾本地大模型,发现一个核心问题:Ollama 和 LM Studio 能让模型跑起来,但参数全靠猜——上下文长度、KV cache 类型、MoE expert 放哪、ubatch 多大……用默认参数基本是在浪费显卡。
于是做了个工具自动找最优配置,过程中踩了不少坑,记录一下。
核心发现
1. MoE 模型的 offload 策略决定了一切
Qwen3-30B-A3B 是 MoE 架构,在 8GB 显卡上:
- LM Studio 默认把所有层塞进显存 → 7549MB ( 93%),3 tok/s
- 只把 attention 层放 GPU ,MoE expert 层走 CPU → 2603MB ( 32%),21 tok/s
快了 7 倍,显存反而省了 65%。关键是 llama.cpp 支持这个,但你得自己识别哪些 tensor 是 MoE expert (
.ffn_.*_exps.这类命名),然后手动配。2. KV cache 类型影响比大多数人想的大
同一张 8GB 显卡跑 Llama 3.1 8B ,不同 KV cache 配置速度差异:
配置 ctx 速度 iso3+iso3 ,4 slot 8K 19.4 tok/s q8_0+q4_0 ,1 slot 8K 38.2 tok/s f16+f16 ,1 slot 8K 51.7 tok/s f16+f16 ,1 slot (自动) 64K 26.2 tok/s f16 比 iso3 快将近 3 倍。但 f16 显存占用更大,所以正确策略是:先算 f16 KV cache 占多少显存,装得下就用 f16 ,装不下再降级。
公式:
KV_MB = 2 × layers × kv_heads × head_dim × ctx × bytes / 1024²3. oobabooga 公式用来预测 ctx 上限
社区里流传的 oobabooga 显存估算公式,原本用来预测装载模型后剩余显存能支持多大 ctx 。但这个公式是基于 q8_0/f16 拟合的,用 iso3 的时候会严重高估显存需求,导致 ctx 只算出 4K 。
最后放弃公式预测,改成二分探测:从 min(nativeCtx, 65536) 开始,OOM 就减半,最多探 5 次,让 llama-server 自己告诉我能跑多少。Llama 3.1 8B 的 ctx 从 4K 直接到 64K 。
4. parallel slot 数量对单用户场景影响巨大
llama.cpp 默认开 4 个并行 slot (为了多用户并发),但单用户场景下这会把 VRAM 分成 4 份。
关掉多余 slot (
--parallel 1)之后:18.5 → 38.2 tok/s ,直接翻倍。5. ubatch 实测比理论更可靠
ubatch 128 vs 512 的性能差异跟模型和显卡都有关系,没有通用最优值。实测结论:
- 8K ctx:ubatch 512 比 128 快 7.6%
- 64K ctx:ubatch 512 比 128 快 21.6%
直接 benchmark 两个值取快的,比查文档猜靠谱。
6. 对话压缩不要用模型生成摘要
最初方案是上下文满了之后调本地模型生成摘要——结果单 slot 阻塞,直接超时。
改成纯算法提取:保留头部( system prompt + 首轮对话)和尾部(最近 8K tokens ),中间部分提取代码路径、函数名、文件名、TODO 等关键信息。压缩率 73%,耗时 <1ms 。
用了哪些技术,实现了什么功能
llama.cpp — 推理引擎核心
直接调用 llama.cpp 的 llama-server ,所有参数( ctx 、KV cache 类型、线程数、ubatch 、mlock 、tensor split )都通过启动参数注入。Kaiwu 本质上是一个参数决策层,不改推理引擎本身。
IsoQuant / TurboQuant — 3-bit KV cache 压缩
集成了 johndpope 的 turboquant fork (
feature/planarquant-kv-cache),支持-ctk iso3 -ctv iso3参数。iso3 的压缩系数实测 0.73 ,理论值 0.75 ,在 VRAM 紧张的设备( 8GB )上可以把 KV cache 占用压缩到 q8_0 的一半。但有约 600MB 固定解码 buffer 开销,VRAM 充裕时反而比 f16 慢 8%,所以策略是 VRAM > 16GB 才默认开 iso3 。oobabooga 显存估算公式 — ctx 上限预测(已放弃)
社区流传的公式用来预测剩余显存能支持多大 ctx ,基于 q8_0/f16 拟合。iso3 场景下高估显存需求,导致 ctx 只算出 4K 。最终改成二分探测代替公式,让 llama-server 自己决定能跑多少。
GQA 架构识别 — KV cache 精准估算
Qwen3 等新模型用 GQA ( Grouped Query Attention ),kv_heads 远小于 attention_heads 。KV cache 大小公式里用的是 kv_heads 而不是 heads ,不识别这一点会高估 3-4 倍。通过读 GGUF metadata 拿到准确的 kv_heads 值再做计算。
MoE tensor 识别 — 自动 expert offload
读取模型的 tensor 名称列表,匹配
.ffn_.*_exps.模式识别出 MoE expert 层,自动决定把这部分路由到 CPU 。不需要用户手动指定,也不需要提前知道模型架构。Extractive Summary — 零延迟对话压缩
上下文到 75% 时触发,纯算法提取:保留 system prompt 、首轮对话、最近 8K tokens ,中间部分按关键词权重保留(代码路径、函数名、文件名、TODO 、命令行等)。不调用任何模型,压缩耗时 <1ms ,73% 压缩率。最初试过调本地模型生成摘要,单 slot 阻塞直接超时,这条路走不通。
GitHub Actions CI — 跨平台自动编译
turboquant fork 需要自己编译带 iso3 支持的 llama-server 。用 GitHub Actions 同时编译 Windows ( MSVC )和 Linux ( GCC )版本,CUDA 12.4 ,覆盖 sm_75/80/86/89 架构,RTX 50 系列通过 PTX JIT 运行时支持。踩了三个 MSVC 编译坑( extern “C” 声明改定义、M_PI 未定义、全局符号缺失),记录在 PROGRESS.md 里。
工具
把上面这些逻辑都自动化了,叫开物( Kaiwu )。一行命令启动,参数全部自动找,结果缓存起来,第二次 2 秒启动。
GitHub: https://github.com/val1813/kaiwu
OpenAI 兼容 API ,Continue / Cursor / Claude Code 直接接。
有遇到类似问题的欢迎交流,尤其是 MoE offload 和 KV cache 这块踩坑挺深的。
作者: KaiWuBOSS | 发布时间: 2026-04-24 10:51
32. zig 写的 100kb 的 wasm 可以 http 读写任意 git 仓库
https://blog.cloudflare.com/artifacts-git-for-agents-beta/
entire git protocol engine is written in pure Zig (no libc), compiled to a ~100KB WASM binary.
Support for both v1 and v2 of the git protocol.
support capabilities including ls-refs, shallow clones (deepen, deepen-since, deepen-relative), and incremental fetch with have/want negotiation.有人知道这玩意开源不?不开源能扒出来别的地方用不?

作者: est | 发布时间: 2026-04-25 15:34
33. codex 使用 5.4 以上版本模型压缩上下文总失败?
在长任务里 5.4 和 5.5 总会遇到这个问题,在碰到自动压缩上下文的时候如果当前模型是 5.4 以上,极大概率触发 stream disconnected 导致自动任务失败,并且重试继续失败无法当前会话,目前看来比较靠谱的办法是手动切换到 5.3 ,回复内容触发压缩上下文后,方能成功,后面又手动切回 5.4 ,但是长任务始终不是个办法,github 上有提改 tcp user timeout 好像也不太有效,这个问题困扰比较久了,不知道各位有什么好法子?
作者: MengLUO | 发布时间: 2026-04-25 15:07
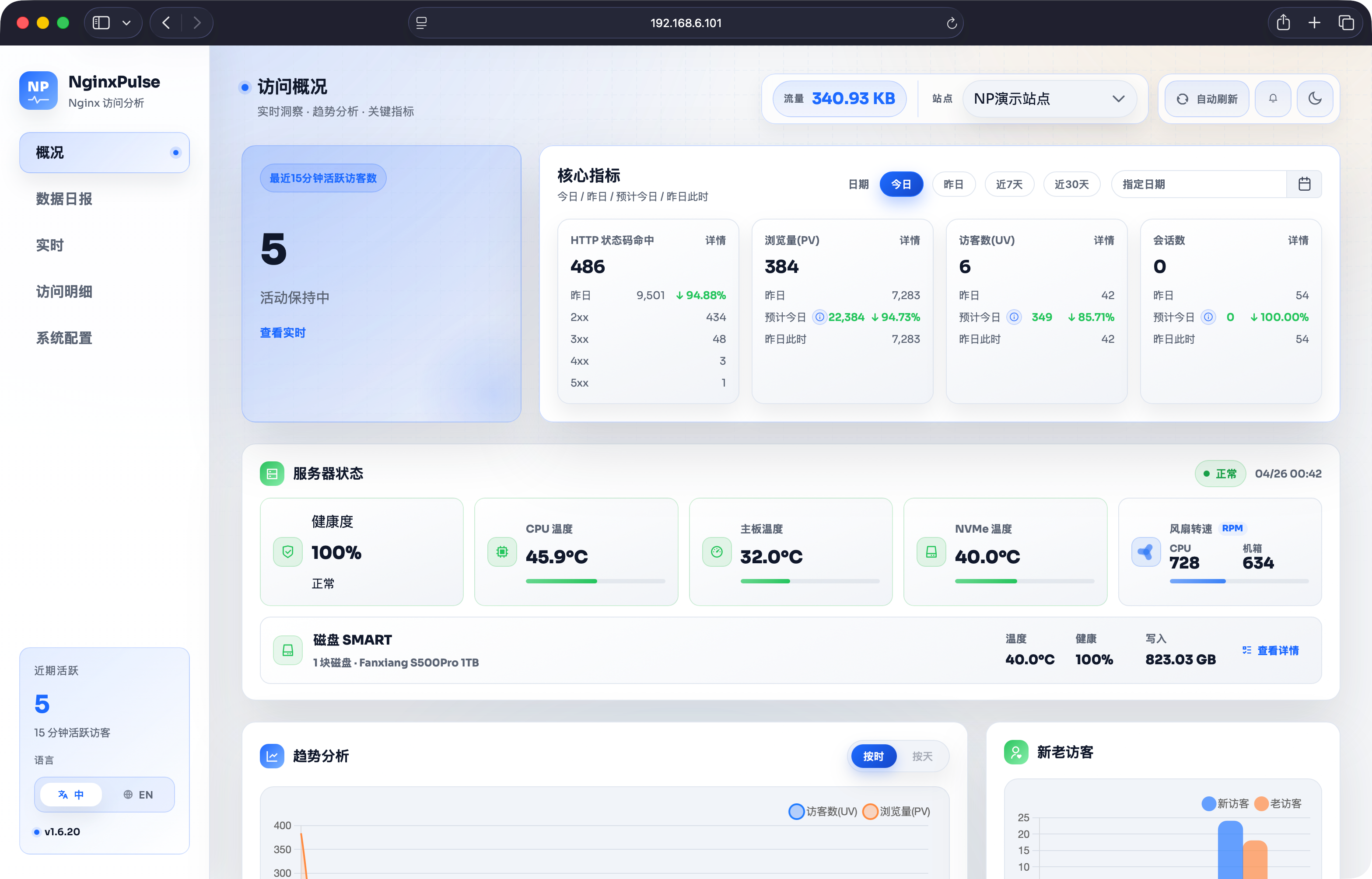
34. 给 NginxPulse 扩展了一个服务器状态卡片
新服务器装好后,我发现我挺在意机箱里的硬件温度以及风扇转速信息的,于是花了点时间在NginxPulse上扩展了下。

作者: MagicCoder | 发布时间: 2026-04-25 17:01
35. 占比大幅提升!谷歌:公司内部 75%的新代码已由 AI 生成
程序员这个行业职业生涯基本到头了吧,没有再进入的必要了,之后会越来越平民化。
但是按道理应该老程序能焕发第二春了,有了 AI 加持越来越需要有编程经验的老炮。
作者: TimLang | 发布时间: 2026-04-24 06:20
36. GPT5.5 在 codex 中 credit 消耗量相比 5.4 翻倍
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
Model Input Credits Output Credits GPT-5.3-Codex 43.75 350 GPT-5.4 62.50 375 GPT-5.5 125 750 天塌了啊,最新 openai 的模型越来越贵,穷人要用不起了啊
看 gpt5.5 的 token 价格翻倍了感觉不妙,结果一看 codex 消耗果然相比 5.4 也翻倍了
本来 codex 的 credit 计算规则改了后就明显消耗量加快了,结果现在 5.5 用量还翻倍了
然后 codex 中 5.5 默认的推理强度还是 extra high 。。。。。
当作和 opus 一样的高级模型好了。。。。
作者: BeautifulSoap | 发布时间: 2026-04-24 03:29
37. 小游戏出海
大家好,最近在研究小游戏出海 tiktok ,目前海外主体在资质审核阶段。希望加入相关的社群,或者我来创建一个组织。有希望了解这块儿的或者已经在从事的可以留微我加你,或者你拉我。感谢大家。base64:bHNsYmxvZw==
作者: cs3230524 | 发布时间: 2026-04-25 15:47
38. 现在还有那个中转站有 openai 包月啊
用量比较大,已经被 glm 封了,我刷过几次帖子了。 本来有个包月的 gpt 用着,但是前些天的号池内斗都废了。我现在还在找包月,能用 gpt5.4 就行。
kimi 199 冲了,三天就跑了一个星期的量。早晚要把我封了。 deepseek 跑不起。 minimax 傻,不想和他讲话了。
作者: feelapi | 发布时间: 2026-04-25 13:08
39. 请问,调用 gpt-image-2 通过 api 的方式使用,请问用什么 app 呢?
请问,调用 gpt-image-2 通过 api 的方式使用,请问用什么 app 呢?
要支持图片的处理哦。
open webui , 只能上传,不能做局部图片的修改。
请问你们用的哪个?
作者: think9999 | 发布时间: 2026-04-25 09:06
40. 在 vscode 中使用 claude code 插件,怎么设置任务提醒功能?
需求:目前主要在 cvcode 中使用 claude code ,它每次在后台执行任务需要很久,我希望它执行完任务后或者需要决策地方,Windows 能弹出一个消息提醒,方便我继续安排它干活。
有没有好的办法呢,谢谢各位啦!
作者: SiWXie | 发布时间: 2026-04-25 14:37
41. 网易 UU 加速器的加速 Claude 能用吗
有没有人试过
作者: Wataru | 发布时间: 2026-04-25 14:17
42. Claude+obsidian 真是太强大了……
claude 帮我部署了任务管理系统(带看板+列表,类似 jira )、架构监控系统(会话自动更新系统架构变动+探针防漂移),感觉效率又要起飞了。。。 多会话并行合作越来越顺滑了。。。
作者: reitao | 发布时间: 2026-04-25 07:50
43. Windows Update 开始推送无限暂停体验
Windows Update 新体验已经开始逐步推送,Windows 更新的暂停功能现在引入了新的日历体验,用户可以选择具体日期暂停更新,最长可达 35 天,便于围绕旅行、会议、考试或繁忙周期进行规划。如果需要更长的暂停时间,用户可以多次延长暂停截止日期,每次最多 35 天,且无延长次数限制。
作者: Fdyo | 发布时间: 2026-04-25 05:44
44. [Selfsync] 自托管 Chrome 数据同步服务器 支持 同步 Edge 浏览器数据同步了
https://www.v2ex.com/t/1206460?p=1#reply15
已经支持 Edge 浏览器数据同步
作者: charlselee59 | 发布时间: 2026-04-25 11:06
45. 今天失去奴隶主的身份后本人非常彷徨,逐立刻购置了百度 Coding Plan…
毕竟它的 Lite 用了优惠券只要 20¥,自己部署 Ollama 后 24 小时开机电费只会比这个更高。
现在除了火山方舟,就剩百度还有 Coding Plan 了,浅尝一下……
作者: konakona | 发布时间: 2026-04-25 14:19
46. 百炼 Lite Plan 加入了 qwen3.6
百炼 Lite Plan 加入了 qwen3.6 ,虽然已经不卖了,但算是还给留存百炼几个月的小伙伴一点福利
千问
qwen3.6-plus
文本生成、深度思考、视觉理解
qwen3.5-plus
文本生成、深度思考、视觉理解
qwen3-max-2026-01-23
文本生成、深度思考
qwen3-coder-next
文本生成
qwen3-coder-plus
文本生成
作者: onedge | 发布时间: 2026-04-25 04:50
47. 这封邮件是告知你关于《互联网平台企业涉税信息报送规定》(国务院令第 810 号) 这一新的信息报送要求。
你好,
这封邮件是告知你关于《互联网平台企业涉税信息报送规定》(国务院令第 810 号) 这一新的信息报送要求。根据该规定,Apple 有义务从通过 App Store 分发 App 的开发者处收集特定信息并提供给中国税务机关*。
为了遵守国务院令第 810 号及相关税务法规,你需要前往 App Store Connect 的“商务”部分提供你的信息。
进一步了解国务院令第 810 号
如有任何税务问题,请联系你的税务顾问。
如有隐私相关问题,请联系 Apple 数据保护官。
如有其他疑问,请联系我们 (英文)。
App Store 团队有收到的吗?
作者: andforce | 发布时间: 2026-04-24 05:22
48. codex 额度不够用啊, pro 一天花了 40%的周额度
兄弟们,太难了…难道我需要开两个账号了? 你们现在都是什么配置
作者: caorushizitest | 发布时间: 2026-04-24 03:24
49. 希望 AGO 三大厂商持续竞争
gpt5.5 一发布,claude 降智问题就被修复了,gemini cli 里面的 3.1 也变得可用了(虽然很慢
是不是说明了市场竞争对我们小老百姓可太重要了啊 没啥主题,就是感慨一下
作者: ljstao | 发布时间: 2026-04-25 04:16
50. 现在开发 agent 应用,你们用什么框架?
langchain 还是 claude-agent-sdk ?
作者: 0bit0 | 发布时间: 2026-04-24 06:48