V2EX 热门帖子
1. 什么成品企业级 NAS 方便维修?
前情提要: https://www.v2ex.com/t/1200956#
电脑装好开机了,我有事就提前离开了,群晖系统镜像刚下到 Windows 上面。
电脑关机关了两周(后面没关),接的 ups ,ups 接的三孔,两周没断电
今天再点亮,表现出主板带电情况:
点一下电源键,电源和 cpu 风扇转一下就不转了。
然后经历漫长的放电操作,把电源线搞坏了:插上后(主机的电源侧)能听见电流声,风扇也不转了
出电流声之前的期间成功点亮进入了 BIOS 界面,但是把电脑竖放起来就黑屏了,风扇也不转了。
买了根电源线去尝试,新电源线不至于走一次放电操作从而风扇不转了。随后又是漫长的放电过程,也没放掉电,仍表现出主板带电。老板也没耐心了,想买成品 nas 了,当简单的沉没成本的。
放电过程:
拔掉电源线,关掉电源(主机侧),扣下电池和内存条,用电池(侧边)/钥匙/螺丝刀划电池槽的金属片(含短接相连),按住开机键几秒,放上电池和单根内存条,再按几秒开机键。插上电源线,打开开关,启动。买成品 Nas 有个问题:买到成品 Nas 也出静电问题怎么办,维修肯定比台式机难,这是个大难题。
Nas 需求:4-6 盘位,自动从 oss 上拉取数据到本地上。hdd 还没有购买。如果购买的话,SAS 与 SATA 不好选择。属于那种期望兼容后续买服务器的状态。至少在相当长的时间内,没有这个正经服务器需求。
作者: Censhuang | 发布时间: 2026-04-25 14:03
2. 为了买到便宜靠谱的 Token,少被割韭菜,我做了个比价的网站
最近在开发一个小项目,想买几个 ChatGPT 账号。
但是在多个卡网和电报群里转了几圈,发现同一种类型的账号,比如 ChatGPT plus 月卡,就有 N 多种价格。
有的几块钱,有的卖 15 ,有的卖 30 ,有的卖 40.
后来我才知道,这些店铺和卖家的来源其实就是那么几种:86 、chong 、xin 、74 这些。
他们都是加价后转卖的。
所以,为了尽快找到相对靠谱的渠道,少花几块钱,减少决策成本,我就做了个比价的网站,把多个平台的价格放在一起,快速对比。
目前收录了二十多个店铺+平台。
如果您有靠谱的渠道,也欢迎在网站提交、加电报群交流。
网址: https://aibijia.org/
电报: https://t.me/+z4dDCVFqx71jYTFlhttps://imgur.com/HsPagPw
https://imgur.com/G1BpVja
https://imgur.com/sv5WecN
https://imgur.com/ZsaKz2T
https://imgur.com/HOwgRot
作者: jzyzcz | 发布时间: 2026-04-25 07:44
3. 你们一个月上班要用多少 token?
如题,我上个月用了 200M ,主要是 GPT5.4 和 Gemini3.1Pro
作者: exploretheworld | 发布时间: 2026-04-25 07:45
4. zig 写的 100kb 的 wasm 可以 http 读写任意 git 仓库
https://blog.cloudflare.com/artifacts-git-for-agents-beta/
entire git protocol engine is written in pure Zig (no libc), compiled to a ~100KB WASM binary.
Support for both v1 and v2 of the git protocol.
support capabilities including ls-refs, shallow clones (deepen, deepen-since, deepen-relative), and incremental fetch with have/want negotiation.有人知道这玩意开源不?不开源能扒出来别的地方用不?

作者: est | 发布时间: 2026-04-25 15:34
5. 请教一个关于模型训练主机配置的问题
主要是用来部署
YOLO26做数据集训练和目标检测或追踪的,图片数据暂定 5000 张(其实数据有很多,但是暂定用于训练的数据上限是 5000 张)。目前有一台 RX6600xt ,但是 directML 好像也不能使这张卡参与训练计算,上网查了一下好像是对 7000 系列以上的显卡支持的更好一些。
所以老板的意思是重新配一台 N 卡主机,但我之前没有使用 YOLO 训练的经验,不知道目前这个数量级的数据训练以及这个体量的模型该使用什么卡。咨询官网 AI 的话,就是无脑推荐 4090 、5090 这种大显存的卡。搞得我很头疼~
关于预算的话,老板只说了一句你看着办吧。但之前老板的意思是让我看看能不能把现在这台主机的显卡换成 RTX5070 ,后来我查了一下现在主机的电源,才 500W ,带不动 5070 ,才有了配新主机的这件事。所以我想着写个两三套配置单给老板看,低配高配都写一下,让老板决定选什么。
有没有有
YOLO 训练+目标检测经验的 V 友给点建议?跪谢了~
作者: jamme | 发布时间: 2026-04-25 15:02
6. 给 NginxPulse 扩展了一个服务器状态卡片
新服务器装好后,我发现我挺在意机箱里的硬件温度以及风扇转速信息的,于是花了点时间在NginxPulse上扩展了下。

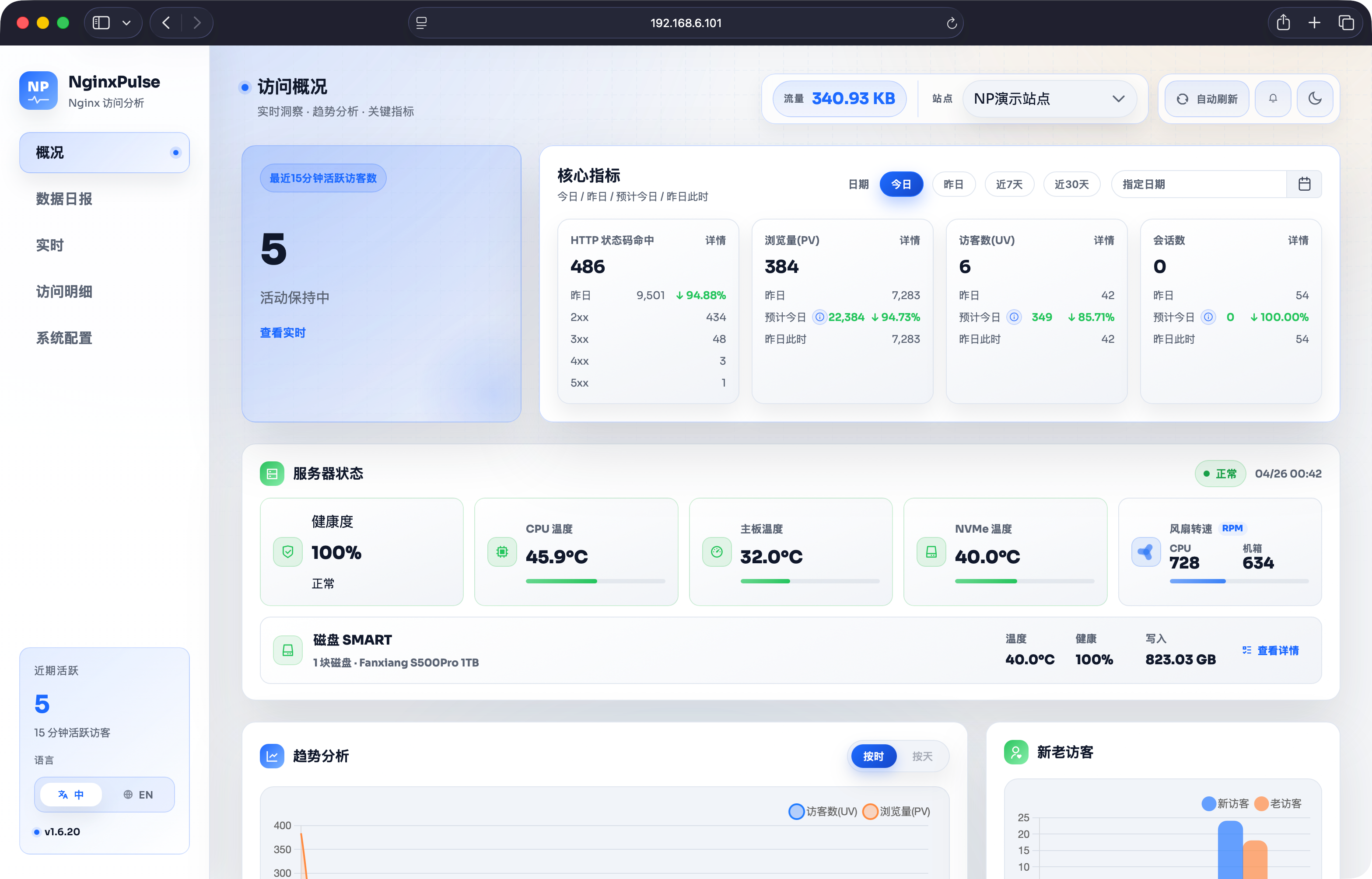
作者: MagicCoder | 发布时间: 2026-04-25 17:01
7. 2026 年,选择 Podman 还是 Docker
Docker 对于大多数自托管应用支持的比较好,个人使用也基本熟悉了。 Podman 的无守护进程和默认的 Rootless 很好用,在服务器上测试部署了一个服务,感觉还挺好的。
作者: DejavuMoe | 发布时间: 2026-04-24 10:12
8. X 的 Premium 订阅不给退款
本身对 Premium 毫无兴趣,为了投放广告才开通,3$每月的套餐无法开通,必须是 8$以上的套餐才能开通广告投放。Premium 充值成功后发现 X 广告系统账号被冻结了。
Premium 申请退款遭到拒绝:
X Support commented: Hello, Thank you for being an X customer. After further review, this scenario is ineligible for a refund according to our Purchaser Terms of Service. Your support case is now closed, and this email is not monitored for replies. For any further assistance, check out Premium FAQs or feel free to contact @Premium for support. Thank you, X Support
作者: AlangHa | 发布时间: 2026-04-25 16:50
9. 大项目中大家真的会用 Spec-Driven Development 吗?
https://openai.com/zh-Hans-CN/index/harness-engineering/ 中提到要把 Spec & Planning & Tasks 进度放进 git 仓库中,大家实践中真的会这么做吗?但是我看 codex 仓库内根本没这些东西,而且很多 Spec 他们都是放在的 Issue 中讨论的。
我自己也用 Openspec ,但实际使用中各种地方不顺手
- openspec 会自己生成一堆 design & propsoal 很多都是正确的废话,给人 Review 就很困难,找不到重点
- 执行完还是有些 Bug ,这种再写回到 Spec 让他修复感觉很 tricky ,明明是 AI 特定问题,结果却要写到给人看的文档中。
- 生成的 Spec 你要严格按照他的流程来,执行 Task 等等。但是加上 Bug 修复。总时间感觉不如用 Planning 功能,再加少量提示词修正顺手,还不用考虑后续文档和代码对不上的问题。
- 据说有人碰到过 Spec 合并 delta 对不上的问题。
请教一下大家日常怎么实践的?
作者: CodeY99 | 发布时间: 2026-04-25 00:22
10. OpenCode GO 已上线 deepseek v4
5 小时限额 pro 1300 次, flash 7450 次
理论上可以用于其他工具比如 claude code ,opencode 说 go 可以用于第三方。
作者: defaw | 发布时间: 2026-04-25 04:21
11. 我做了个工具让 8GB 显卡跑 30B 模型从 3 tok/s 提到 21 tok/s,记录一下技术发现
最近在折腾本地大模型,发现一个核心问题:Ollama 和 LM Studio 能让模型跑起来,但参数全靠猜——上下文长度、KV cache 类型、MoE expert 放哪、ubatch 多大……用默认参数基本是在浪费显卡。
于是做了个工具自动找最优配置,过程中踩了不少坑,记录一下。
核心发现
1. MoE 模型的 offload 策略决定了一切
Qwen3-30B-A3B 是 MoE 架构,在 8GB 显卡上:
- LM Studio 默认把所有层塞进显存 → 7549MB ( 93%),3 tok/s
- 只把 attention 层放 GPU ,MoE expert 层走 CPU → 2603MB ( 32%),21 tok/s
快了 7 倍,显存反而省了 65%。关键是 llama.cpp 支持这个,但你得自己识别哪些 tensor 是 MoE expert (
.ffn_.*_exps.这类命名),然后手动配。2. KV cache 类型影响比大多数人想的大
同一张 8GB 显卡跑 Llama 3.1 8B ,不同 KV cache 配置速度差异:
配置 ctx 速度 iso3+iso3 ,4 slot 8K 19.4 tok/s q8_0+q4_0 ,1 slot 8K 38.2 tok/s f16+f16 ,1 slot 8K 51.7 tok/s f16+f16 ,1 slot (自动) 64K 26.2 tok/s f16 比 iso3 快将近 3 倍。但 f16 显存占用更大,所以正确策略是:先算 f16 KV cache 占多少显存,装得下就用 f16 ,装不下再降级。
公式:
KV_MB = 2 × layers × kv_heads × head_dim × ctx × bytes / 1024²3. oobabooga 公式用来预测 ctx 上限
社区里流传的 oobabooga 显存估算公式,原本用来预测装载模型后剩余显存能支持多大 ctx 。但这个公式是基于 q8_0/f16 拟合的,用 iso3 的时候会严重高估显存需求,导致 ctx 只算出 4K 。
最后放弃公式预测,改成二分探测:从 min(nativeCtx, 65536) 开始,OOM 就减半,最多探 5 次,让 llama-server 自己告诉我能跑多少。Llama 3.1 8B 的 ctx 从 4K 直接到 64K 。
4. parallel slot 数量对单用户场景影响巨大
llama.cpp 默认开 4 个并行 slot (为了多用户并发),但单用户场景下这会把 VRAM 分成 4 份。
关掉多余 slot (
--parallel 1)之后:18.5 → 38.2 tok/s ,直接翻倍。5. ubatch 实测比理论更可靠
ubatch 128 vs 512 的性能差异跟模型和显卡都有关系,没有通用最优值。实测结论:
- 8K ctx:ubatch 512 比 128 快 7.6%
- 64K ctx:ubatch 512 比 128 快 21.6%
直接 benchmark 两个值取快的,比查文档猜靠谱。
6. 对话压缩不要用模型生成摘要
最初方案是上下文满了之后调本地模型生成摘要——结果单 slot 阻塞,直接超时。
改成纯算法提取:保留头部( system prompt + 首轮对话)和尾部(最近 8K tokens ),中间部分提取代码路径、函数名、文件名、TODO 等关键信息。压缩率 73%,耗时 <1ms 。
用了哪些技术,实现了什么功能
llama.cpp — 推理引擎核心
直接调用 llama.cpp 的 llama-server ,所有参数( ctx 、KV cache 类型、线程数、ubatch 、mlock 、tensor split )都通过启动参数注入。Kaiwu 本质上是一个参数决策层,不改推理引擎本身。
IsoQuant / TurboQuant — 3-bit KV cache 压缩
集成了 johndpope 的 turboquant fork (
feature/planarquant-kv-cache),支持-ctk iso3 -ctv iso3参数。iso3 的压缩系数实测 0.73 ,理论值 0.75 ,在 VRAM 紧张的设备( 8GB )上可以把 KV cache 占用压缩到 q8_0 的一半。但有约 600MB 固定解码 buffer 开销,VRAM 充裕时反而比 f16 慢 8%,所以策略是 VRAM > 16GB 才默认开 iso3 。oobabooga 显存估算公式 — ctx 上限预测(已放弃)
社区流传的公式用来预测剩余显存能支持多大 ctx ,基于 q8_0/f16 拟合。iso3 场景下高估显存需求,导致 ctx 只算出 4K 。最终改成二分探测代替公式,让 llama-server 自己决定能跑多少。
GQA 架构识别 — KV cache 精准估算
Qwen3 等新模型用 GQA ( Grouped Query Attention ),kv_heads 远小于 attention_heads 。KV cache 大小公式里用的是 kv_heads 而不是 heads ,不识别这一点会高估 3-4 倍。通过读 GGUF metadata 拿到准确的 kv_heads 值再做计算。
MoE tensor 识别 — 自动 expert offload
读取模型的 tensor 名称列表,匹配
.ffn_.*_exps.模式识别出 MoE expert 层,自动决定把这部分路由到 CPU 。不需要用户手动指定,也不需要提前知道模型架构。Extractive Summary — 零延迟对话压缩
上下文到 75% 时触发,纯算法提取:保留 system prompt 、首轮对话、最近 8K tokens ,中间部分按关键词权重保留(代码路径、函数名、文件名、TODO 、命令行等)。不调用任何模型,压缩耗时 <1ms ,73% 压缩率。最初试过调本地模型生成摘要,单 slot 阻塞直接超时,这条路走不通。
GitHub Actions CI — 跨平台自动编译
turboquant fork 需要自己编译带 iso3 支持的 llama-server 。用 GitHub Actions 同时编译 Windows ( MSVC )和 Linux ( GCC )版本,CUDA 12.4 ,覆盖 sm_75/80/86/89 架构,RTX 50 系列通过 PTX JIT 运行时支持。踩了三个 MSVC 编译坑( extern “C” 声明改定义、M_PI 未定义、全局符号缺失),记录在 PROGRESS.md 里。
工具
把上面这些逻辑都自动化了,叫开物( Kaiwu )。一行命令启动,参数全部自动找,结果缓存起来,第二次 2 秒启动。
GitHub: https://github.com/val1813/kaiwu
OpenAI 兼容 API ,Continue / Cursor / Claude Code 直接接。
有遇到类似问题的欢迎交流,尤其是 MoE offload 和 KV cache 这块踩坑挺深的。
作者: KaiWuBOSS | 发布时间: 2026-04-24 10:51
12. codex 使用 5.4 以上版本模型压缩上下文总失败?
在长任务里 5.4 和 5.5 总会遇到这个问题,在碰到自动压缩上下文的时候如果当前模型是 5.4 以上,极大概率触发 stream disconnected 导致自动任务失败,并且重试继续失败无法当前会话,目前看来比较靠谱的办法是手动切换到 5.3 ,回复内容触发压缩上下文后,方能成功,后面又手动切回 5.4 ,但是长任务始终不是个办法,github 上有提改 tcp user timeout 好像也不太有效,这个问题困扰比较久了,不知道各位有什么好法子?
作者: MengLUO | 发布时间: 2026-04-25 15:07
13. 小游戏出海
大家好,最近在研究小游戏出海 tiktok ,目前海外主体在资质审核阶段。希望加入相关的社群,或者我来创建一个组织。有希望了解这块儿的或者已经在从事的可以留微我加你,或者你拉我。感谢大家。base64:bHNsYmxvZw==
作者: cs3230524 | 发布时间: 2026-04-25 15:47
14. 搞了一个不需要提示词的 AI 写真网站,各位大佬帮忙分析一下有没有机会?
我发现抖音和小红书上有很多人分享 AI 写真指令,就是一群爱美女士通过豆包生成写真,不得不承认确实非常漂亮、养眼。评论区里有很多人求指令。
我以为这是一个机会,说明很多爱美女士也想拍写真,但又不掌握复杂的提示词,那么如果把这个过程简化一下呢?做一个提示词大全或者写真大全的网站,是否可以?
我用 cc 一周的时间就搞了一个美图拍的网站,https://www.meitulab.com 。 现在网站上线一周了,结果百度不收录,每天都没有流量,那么是这个需求是伪需求,还是我网站 seo 做的不好呢?
我下一步想接着做小程序和 app ,但如果需求不是真需求,是不是也没有机会呢?

作者: imdodd | 发布时间: 2026-04-25 15:40
15. 现在还有那个中转站有 openai 包月啊
用量比较大,已经被 glm 封了,我刷过几次帖子了。 本来有个包月的 gpt 用着,但是前些天的号池内斗都废了。我现在还在找包月,能用 gpt5.4 就行。
kimi 199 冲了,三天就跑了一个星期的量。早晚要把我封了。 deepseek 跑不起。 minimax 傻,不想和他讲话了。
作者: feelapi | 发布时间: 2026-04-25 13:08
16. 在 vscode 中使用 claude code 插件,怎么设置任务提醒功能?
需求:目前主要在 cvcode 中使用 claude code ,它每次在后台执行任务需要很久,我希望它执行完任务后或者需要决策地方,Windows 能弹出一个消息提醒,方便我继续安排它干活。
有没有好的办法呢,谢谢各位啦!
作者: SiWXie | 发布时间: 2026-04-25 14:37
17. 请问,调用 gpt-image-2 通过 api 的方式使用,请问用什么 app 呢?
请问,调用 gpt-image-2 通过 api 的方式使用,请问用什么 app 呢?
要支持图片的处理哦。
open webui , 只能上传,不能做局部图片的修改。
请问你们用的哪个?
作者: think9999 | 发布时间: 2026-04-25 09:06
18. Claude+obsidian 真是太强大了……
claude 帮我部署了任务管理系统(带看板+列表,类似 jira )、架构监控系统(会话自动更新系统架构变动+探针防漂移),感觉效率又要起飞了。。。 多会话并行合作越来越顺滑了。。。
作者: reitao | 发布时间: 2026-04-25 07:50
19. Windows Update 开始推送无限暂停体验
Windows Update 新体验已经开始逐步推送,Windows 更新的暂停功能现在引入了新的日历体验,用户可以选择具体日期暂停更新,最长可达 35 天,便于围绕旅行、会议、考试或繁忙周期进行规划。如果需要更长的暂停时间,用户可以多次延长暂停截止日期,每次最多 35 天,且无延长次数限制。
作者: Fdyo | 发布时间: 2026-04-25 05:44
20. [Selfsync] 自托管 Chrome 数据同步服务器 支持 同步 Edge 浏览器数据同步了
https://www.v2ex.com/t/1206460?p=1#reply15
已经支持 Edge 浏览器数据同步
作者: charlselee59 | 发布时间: 2026-04-25 11:06
21. 如何根治 Claude 在编译 C++时自作聪明的问题
用的是 GitHub Copilot Claude Sonnet 4.6 ,已经在 copilot-instructions.md 里面写了 please redirect building log to a temporary file instead of using tail or grep.
每次编译的时候,只要因为模版导致报错信息过长,AI 就会无视我的指令,无限的自作聪明重复这个弱智行为:
1. 先 tail 20 行,什么也没看到,然后再编译一次 tail 50 行,还是什么也没看到。
2. 再编译一次,用 grep | err ,真正的错误信息还是被淹没。
3. 最后实在没办法了,才去/tmp 写入临时文件。
我大概能猜到这是跟 agent 内部要缩短上下文的机制冲突了,如何根治?
作者: xuegy | 发布时间: 2026-04-25 12:37
22. 今天失去奴隶主的身份后本人非常彷徨,逐立刻购置了百度 Coding Plan…
毕竟它的 Lite 用了优惠券只要 20¥,自己部署 Ollama 后 24 小时开机电费只会比这个更高。
现在除了火山方舟,就剩百度还有 Coding Plan 了,浅尝一下……
作者: konakona | 发布时间: 2026-04-25 14:19
23. 网易 UU 加速器的加速 Claude 能用吗
有没有人试过
作者: Wataru | 发布时间: 2026-04-25 14:17
24. 百炼 Lite Plan 加入了 qwen3.6
百炼 Lite Plan 加入了 qwen3.6 ,虽然已经不卖了,但算是还给留存百炼几个月的小伙伴一点福利
千问
qwen3.6-plus
文本生成、深度思考、视觉理解
qwen3.5-plus
文本生成、深度思考、视觉理解
qwen3-max-2026-01-23
文本生成、深度思考
qwen3-coder-next
文本生成
qwen3-coder-plus
文本生成
作者: onedge | 发布时间: 2026-04-25 04:50
25. 各位大佬,有没有注册机可以用的,有偿
主要是 chatgpt ,claude 这类的
作者: dingshaofeng328 | 发布时间: 2026-04-25 11:26
26. Antigravity 两个 PRO 账号,一个正常,另一个无限 high traffic 不能用
大家有没有遇到过这种情况,我有两个 PRO 账号,在 antigravity 里,A 账号正常使用,但是切换 B 账号后,虽然都是 PRO ,antigravity 好像视作是 FREE 账号,无限 high traffic 等待。我切换回 A 就又正常用了。 而且 B 账号显示就是 PRO ,看 setting 里的 model 额度也都正常显示,但是就是无限 high traffic 。
难道谷歌看破不说破,B 账号虽然显示 PRO 但是暗地里已经降级成 FREE 了?
作者: KCL | 发布时间: 2026-04-25 06:18
27. 占比大幅提升!谷歌:公司内部 75%的新代码已由 AI 生成
程序员这个行业职业生涯基本到头了吧,没有再进入的必要了,之后会越来越平民化。
但是按道理应该老程序能焕发第二春了,有了 AI 加持越来越需要有编程经验的老炮。
作者: TimLang | 发布时间: 2026-04-24 06:20
28. 使用软路由的大佬们是怎么代理 claude code 的?
之前在软路由中使用 openclash 配置了 claude code 的代理规则,使用 fakeip ,但 claude code 经常断开,后面换成了 passwall ,重新配置相关的代理规则,但仍然时不时断开。但是直接在电脑上使用 surge 开启增强代理,反而一直没啥问题。
求问下老哥们现在都是软路由怎么配置的?
作者: closedevice | 发布时间: 2026-04-25 15:23
29. vscode 中 codex 插件加载不出来的问题
我在最新版本中使用 GPT-5.5 的 Codex 插件时,遇到加载对话内容不出来的问题。具体情况如下:
- 在服务器和 WSL2 中都会出现。
- 我已更新到最新的 VSCode 版本,更新后 VSCode 自带了一个“聊天”选项。点开“聊天”再切回 Codex ,有时能让 codex 之前加载不出来的对话显示出来。
- 网络状况正常,看起来不像是网络问题。
我想问一下,有人遇到过类似情况吗?在其他地方看到有人反馈加载卡顿的情况,似乎回退到旧版本就没有这个问题。请问这是 Codex 插件自身的 bug ,还是与 VSCode 的新版本存在兼容性问题?
作者: Saunak | 发布时间: 2026-04-25 01:25
30. claude code 长时间卡住
这两天感觉 claude code 是不是存在很严重的问题? 长时间卡主,一直在 think,几次都思考了几十分钟都没有任何结果,只能强制关掉再来,然后问一两个问题之后就有卡主不出结果了。 token 全被这样消耗了。
作者: yoyoluck | 发布时间: 2026-04-25 06:31
31. google 搜索的 AI 模式(自动右侧弹出)是个谜啊?
最早偶尔发现,我认为是从哪个时间线之后都带
后来发现有时候就没有
忽而想起来自己的🪜不稳飞机场一直换来换去
可能跟这个有关系
后来验证确实跟国家/地区有关
那我想,总归美国节点都可以吧?
谁承想,也是有时候可以,有时候不行。
那这判断因素还挺细致啊 ?
比如我现在用的这个节点
2602:f6f6:2:65fe::1
United States undefined Fourplex Telecom LLC
就不能自动弹出 AI 模式
应将浏览器切至 https://gemini.google.com/
居然还告诉我:Gemini isn’t currently supported in your country. Stay tuned!
我就纳闷了,居然老美也不是全境 IP 都可以用?
作者: intoext | 发布时间: 2026-04-25 02:54
32. 希望 AGO 三大厂商持续竞争
gpt5.5 一发布,claude 降智问题就被修复了,gemini cli 里面的 3.1 也变得可用了(虽然很慢
是不是说明了市场竞争对我们小老百姓可太重要了啊 没啥主题,就是感慨一下
作者: ljstao | 发布时间: 2026-04-25 04:16
33. 有中转站导航吗?
作者: kongkongye | 发布时间: 2026-04-25 03:35
34. 虚拟机内的 VS Code Server 怎么加速更新
怎么让它走宿主机代理。
vbox + LinuxMint
作者: wdssmq | 发布时间: 2026-04-25 02:14
35. 我的开源项目,欢迎大家使用和批评,本地无字典字符型模型训练架构代码完全开源,可形成语义结构
欢迎批评,也是 vibe coding 的产物,我是在尝试学习数学和物理相关理论的时候结合编码学的一些自己的看法在做实验,当然实验内容大部分也是 vibe coding 的产物,现有基准是这个模型在本地学习 fineweb 数据集,架构没有词典层,只有字符学习和相关纯数学架构和编码尝试的情况下可以涌现类英语语义结构,而且训练和展开输出均是显存和内存优化形式的,大家可以尝试自己分析和使用一下,相关的思考方式和架构本身也在代码中注释了,如果用其他 ai 去分析该项目会对其数学结构有不同看法,当然可能是我的思考角度导致我的用语和提示词导致其结构偏移和我的用语没有广泛被接受的问题。请大家批评指正,我尽力提高我自己。 项目地址: https://github.com/makai891124-prog/H2Q-MicroStream
作者: evegod | 发布时间: 2026-04-25 17:17
36. 火山方舟 Coding Plan 慎买
火山方舟 Coding Plan 慎买啊,群里全是要退款的,又卡又慢,额度消耗的还特别快
作者: ghostman | 发布时间: 2026-04-23 07:43
37. 天下苦 Claude 久矣, GPT 就出招了, 5.5 目测下限是 opus 4.6
1 ,输出好多了,不讲八股文了 2 ,体感变快 2 ,大上下文目测增强很多
解决了 5.4 最大的 l 几个问题,可主力使用。
我想说出早了,再等 1-2 周,Claude 继续硬着脖子说自己模型没问题。等着 claude 的口碑再烂点。奥特曼太着急了
作者: sampeng | 发布时间: 2026-04-24 00:23
38. codex 额度不够用啊, pro 一天花了 40%的周额度
兄弟们,太难了…难道我需要开两个账号了? 你们现在都是什么配置
作者: caorushizitest | 发布时间: 2026-04-24 03:24
39. 没想到 2026 年,还要浪费大量时间在跨域问题上
公司后端写的接口部署到测试环境了,访问之后发现跨域了,把浏览器的跨域截图发给后端开发,问我报什么错了?难道都 2026 年还不理解跨域是什么原理吗?还需要我给他科普一下吗?心累。
作者: guansixu | 发布时间: 2026-04-23 01:23
40. GPT5.5 在 codex 中 credit 消耗量相比 5.4 翻倍
https://developers.openai.com/api/docs/pricing?latest-pricing=standard
Model Input Credits Output Credits GPT-5.3-Codex 43.75 350 GPT-5.4 62.50 375 GPT-5.5 125 750 天塌了啊,最新 openai 的模型越来越贵,穷人要用不起了啊
看 gpt5.5 的 token 价格翻倍了感觉不妙,结果一看 codex 消耗果然相比 5.4 也翻倍了
本来 codex 的 credit 计算规则改了后就明显消耗量加快了,结果现在 5.5 用量还翻倍了
然后 codex 中 5.5 默认的推理强度还是 extra high 。。。。。
当作和 opus 一样的高级模型好了。。。。
作者: BeautifulSoap | 发布时间: 2026-04-24 03:29