Hacker News 高赞评论 - 2026-04-26
1. evilpie 在“Firefox 已集成 Brave 的广告拦截引擎”下的新评论
Firefox团队正在尝试改进内置的增强型跟踪保护功能。这是我们计划试验的库之一。
- 我们目前没有,也没有计划放弃MV2扩展。这将确保某些类型的插件(如广告拦截器)在Firefox中继续发挥最佳效果。
- Firefox在桌面端和Android上支持多种广告拦截器插件,包括uBlock Origin。
- 我们并没有捆绑Brave的广告拦截系统,而是在测试他们开源Rust组件中的一个,以改进Firefox处理跟踪列表的方式。
https://www.reddit.com/r/firefox/comments/1sttf82/firefox_wi…
这是Firefox官方账号在Reddit上对此事的回应。
作者: evilpie | 发布于: 2026-04-25 07:28
2. Strilanc 在“用 /dev/urandom 替换 IBM 量子后端”中的新评论
这恰恰是我2025年Sigbovik愚人节论文1的核心论点:对于小数字,Shor算法在输入随机样本时能快速成功。而当你的量子电路过长时(考虑到量子计算机的误差率),量子计算机就会表现得像随机数生成器。因此,要”做对事”并以错误的原因取得成功是轻而易举的。这正是小规模因式分解/椭圆曲线离散对数问题不适合作为量子计算进展基准的诸多原因之一。
我曾警告过project11团队这种情况会发生——他们会把比特币奖励给最善于掩盖”量子计算机其实没起什么作用”这一事实的人(很可能包括自欺欺人的提交者)。看来他们没把我的话当回事。
作者: Strilanc | 发布于: 2026-04-25 04:45
3. 在“用/dev/urandom替换IBM Quantum后端”中新增的鸽子评论
“十一号项目”刚刚奖励了1个比特币,表彰”迄今为止对ECC最大的量子攻击”——在IBM量子硬件上成功破解了一个17位椭圆曲线密钥。Yuval Adam用/dev/urandom替换了量子计算机,结果依然能恢复密钥。
作者: pigeons | 发布于: 2026-04-25 00:58
4. skybrian 在“谷歌计划向 Anthropic 投资高达 400 亿美元”下的新评论
背景:几周前,Anthropic与谷歌和博通签署了一项协议,购买”数吉瓦的下一代TPU算力”1。此前已有几笔类似交易。
有人把这类交易称为”循环交易”,但或许更准确的理解是,这是一种超大规模的供应商融资?供应商融资的简单版本是,供应商给零售商一定时间,让他们支付已购入待售商品的货款。这实际上是一笔以零售商转售商品能力为担保的贷款。零售商有可能破产不付款,但供应商了解零售商的经营状况,因此知道这笔风险是否可控。
类似地,谷歌很可能对Anthropic了如指掌,因为Anthropic从谷歌购买计算服务再转售。他们做的是股权投资而非贷款,但假设Anthropic的销售额继续像过去那样快速增长,这笔钱最终还是会流回谷歌。
另外,如果你持有谷歌股票,其中一小部分是否也算是对Anthropic的投资?
1 https://www.anthropic.com/news/google-broadcom-partnership-c…
作者: skybrian | 发布于: 2026-04-24 23:08
5. barnabee 在“谷歌计划向 Anthropic 投资高达 400 亿美元”下的新评论
在我工作的地方:
整体开发速度明显提升了很多。代码质量并没有明显下降,但这是LLM辅助的结果,而不是”氛围编码”(除了实验项目和内部工具)。
以前用TypeScript快速搭建的东西,现在都变成了Rust应用。
以前只是小型Python脚本的任务,现在变成了完整的Web应用和仪表盘。
“氛围编码”(用Claude Desktop,没人用Replit或其他工具)成了非技术人员的新版Excel。
每次有人提出任何想法,都会附带一份多页的”Claude生成”备忘录,解释为什么这是个好主意以及具体该怎么做(其中大约20%是有用的)。
以前80%的网页搜索现在都转向了Claude(至少对相当一部分人来说是这样,可能超过50%)。
没人再谈论ChatGPT了。现在要么是Claude,要么(偶尔)是Gemini。
我的主要工作不是写代码,但我尽量让Claude Code(我的个人和企业账号)和OpenCode(也几乎总是通过Copilot调用Claude)持续运转,尽可能接近100%的时间都在处理某些任务,同时不影响我的其他优先事项。
我们团队(大约20人)现在使用的推理量可能是年初时的两个数量级,而且已经从Cursor、ChatGPT和Claude集中到了几乎全是Claude(外加一点Gemini,因为它是我们Google WhateverSpace计划的一部分,有些人喜欢用它,主要是非工程任务)。
我不确定这一切是否真的会让事情变得更好,但我觉得如果我们放弃所有这些,回到以前的方式,我们会在竞争中处于严重劣势。
作者: barnabee | 发布于: 2026-04-24 22:55
6. msy 在“谷歌计划向 Anthropic 投资高达 400 亿美元”下的新评论
我们突然涌现出大量新的内部工具和资源,几乎全都功能残缺、基本无用,对整体业务走向毫无明显影响,但到了晋升季却似乎格外管用。
几乎每隔不到一小时,就会冒出一份四页文档,要求所有人阅读、消化并回复,而它的“作者”自己却连这些步骤都没做过。这感觉越来越像在故意找茬。
作者: msy | 发布于: 2026-04-24 22:06
7. pash 在“深度学习将会有科学理论”一文中的新评论
转折点出现在2012年,当时深度卷积神经网络AlexNet[0]在ImageNet分类竞赛中实现了质的飞跃。
看到AlexNet的结果后,所有主要的机器学习图像实验室都转向了深度卷积神经网络,其他方法几乎从最先进的图像竞赛中完全消失。在接下来的几年里,深度神经网络也接管了其他机器学习领域。
普遍认为,正是(1)比早期时代呈指数级增长的算力,与(2)呈指数级增长的高质量数据集(例如经过精心整理和人工标注的ImageNet数据集)的结合,才最终让深度神经网络大放异彩。
“注意力”机制的发展在处理文本等相对自由排序的序列数据中的复杂关系时尤其有价值,但我认为现在大多数机器学习从业者都将神经网络架构本质上视为一种权衡选择——在数据和算力不足时,它们有助于在特定情境下进行学习,但并非学习的根本所在。”苦涩的教训”1告诉我们,更多的算力和数据最终会击败那些无法规模化扩展的更好模型。
想想看:人类体内大约有10^11个神经元,狗有10^9个,老鼠有10^7个。这些数字让我印象深刻的是,它们都很大。即使是一只老鼠,也需要数亿个神经元才能完成它要做的事情。
智能,即使是有限形式的智能,似乎只有在跨越算力容量的高阈值后才会涌现。这可能与需要大量参数来处理复杂学习环境的内在复杂性有关。(老鼠和人类都存在于相同的物理现实中。)
另一方面,我们知道许多参数数量少的简单技术在简单或程式化问题上效果很好(甚至被证明是最优的)。”学习”和”智能”这两个词,在我们使用的语境中,往往暗示着复杂的环境,而复杂性本质上需要大量参数来建模。
作者: pash | 发布于: 2026-04-24 21:45
8. tiffanyh 在 “谷歌计划向 Anthropic 投资高达 400 亿美元” 下的新评论
这就是当你从90亿美元的年经常性收入(ARR)增长到300亿美元时所需要的——而且仅仅是在一个季度之后。
这种疯狂的增长和需求,在如此规模下是前所未有的。
https://www.anthropic.com/news/google-broadcom-partnership-c...
作者: tiffanyh | 发布于: 2026-04-24 21:15
9. 33MHz-i486 在“谷歌计划向 Anthropic 投资高达 400 亿美元”中的新评论
我觉得最近几周隐含的信息是,Anthropic 正面临严重的容量限制(或者说接近这个状态)。他们似乎不得不在短时间内先后与亚马逊和谷歌签署了两项不太有利的合同。结果模型质量又突然回升了。
作者: 33MHz-i486 | 发布于: 2026-04-24 20:46
10. wg0 在“我取消了 Claude:Token 问题、质量下降和糟糕支持”下的新评论
我会编写详细的规格说明。多文件结构,附带示例代码,全部用Markdown格式。
然后交给Claude Sonnet处理。
在列出硬性要求后,我发现生成的代码要么遗漏需求,要么存在重复代码,甚至包含不必要的数据处理(比如将对象映射成更窄类型的新对象,而这些根本用不上),同时还有那些伪造数据、绕过逻辑来通过测试的测试用例。
所以到头来,我不是在写代码,而是在大量阅读代码。
在生成式AI出现之前,我亲身经历的事实是:写代码要容易得多。真正耗费大量精力的是阅读代码、理解代码、并在脑中构建心智模型。
因此,使用生成式AI反而需要我投入更多时间和精力,因为我必须阅读大量代码,理解它们,并确保它们符合我已有的心智模型。
所以,以Anthropic目前这个定价,生成式AI对我来说是净负收益。因为我不是在”随性编码”,而是在构建真正依赖这些软件的真人用户所使用的产品。我的用户理应得到我更专注的投入和关注,因此我很快就会取消订阅。
作者: wg0 | 发布于: 2026-04-24 18:14
11. nabakin 在 “DeepSeek v4” 中的新评论
另外,请注意这完全不需要CUDA依赖。它完全运行在华为芯片上。
这是一个非常重大的声明,却没有提供任何证据。
我查证了你所说的内容,但在他们的论文[0]、HuggingFace页面1、Twitter[2]、微信[3]以及新闻稿[4]中,都没有找到任何支持这一说法的陈述。
他们只在中文版新闻稿的脚注中提到,计划在Ascend 950超级节点发布后降低推理成本[5]。论文中唯一提到华为的地方,是他们验证了一种在Ascend NPU和Nvidia GPU上降低互联带宽的技术[6]。
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main...
1 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] https://xcancel.com/deepseek_ai/status/2047516922263285776
[3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg
[4] https://api-docs.deepseek.com/news/news260424
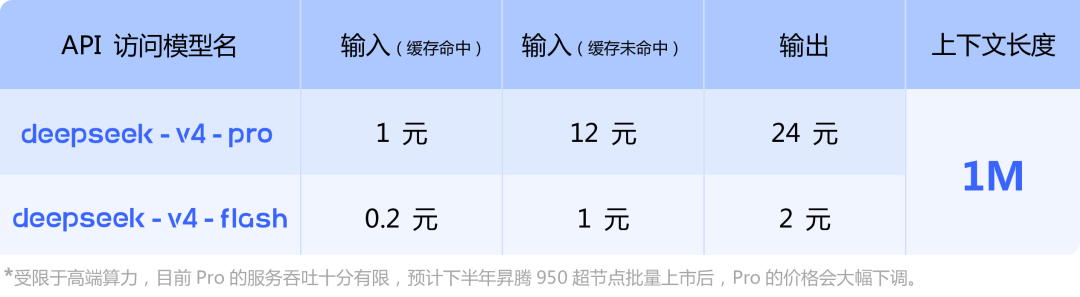
[5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png
[6] 第16页
{kind=link}
作者: nabakin | 发布于: 2026-04-24 16:55
12. rectang 在“我取消了 Claude:Token 问题、质量下降和糟糕支持”中的新评论
我觉得自己用Claude Opus还挺顺手的,说实话,在中档订阅下也没怎么碰到使用限制。我的工作流更像是”副驾驶”模式,而不是”自动驾驶”——我会为具体的任务精心设计提示词,并且几乎每段输出都会仔细审核。跟那些搞”氛围编程”的人比起来,我的用法算是比较轻量的。
就我的使用方式而言,目前市场领先的技术已经相当”够用”了。我很期待有一天LLM辅助编程能变成一种通用商品。我真心希望能有一个基于合规授权代码的开源模型。
作者: rectang | 发布于: 2026-04-24 16:50
13. ryandrake 在“我不再做桌面应用了(2009)”下的新评论
Patrick的观点几乎都很好——前提是你的软件开发目标是赚钱。如果你是在写开源软件,这些观点似乎就不那么重要了。我认为在开源世界里,桌面应用依然重要且精彩。我刚刚开始了一个新的业余项目,选择做成跨平台、非Electron的桌面应用,因为这才是我喜欢开发的东西。
用户引导流程:只有当你试图扩大用户群并实现销售时才需要关心。
转化率:只有当你收费时才需要关心。
Adwords广告:用他的话来说,只有当你试图”碾压竞争对手”时才需要关心。
技术支持:如果你在卖软件,你多少得提供支持。对于免费和开源软件来说,这只是个小问题。
盗版:只涉及商业软件。
分析和用户行为追踪:同样,似乎只有商业软件才觉得有必要监视用户,把他们当作A/B测试的小白鼠。
我唯一同意他的一点是,Web开发周期更短。但我认为这只是”开发者的便利”,对用户来说并不重要(事实上,更短的开发周期对用户可能更糟,因为他们的软件会像流沙一样快速变化)。对我来说,在我的开源项目中,我的”开发周期”在我推送到git时就结束了,而且我想推多少次都行。
作者: ryandrake | 发布于: 2026-04-24 16:23
14. sidewndr46 在“过度思考、范围蔓延和结构性差异导致项目破坏”中的新评论
第一天:我们的目标是展示一种现有工业催化剂在尚未商业化的新应用中的有效性,从而可能降低关键药物前体的生产成本。
第400天:在详尽描述了一个万有理论之后,我们着手在拉格朗日点轨道上建造一个实验装置,用于探测一种能够介导已知宇宙中所有可观测力的普遍粒子。
作者: sidewndr46 | 发布于: 2026-04-24 15:12
15. bennettnate5 在“过度思考、范围蔓延和结构差异如何破坏项目”下的新评论
顺便说一句,这正好说明了我认为博士研究最大的难点所在。你得选一个自己感兴趣的课题,然后读遍所有相关文献,结果往往会发现,你想做的事情已经有太多人做过了,研究范围就这样不知不觉地越扩越大。等到最初的热情和精力耗尽,你还得硬撑着完成最后那20%到30%的工作,才能把研究成果写成可以发表的水平。
作者: bennettnate5 | 发布于: 2026-04-24 14:53
16. b40d-48b2-979e 在“成人及赌博初创公司的运营成本”一文中的新评论
你可能在体育博彩、赌场或彩票领域有一个很酷的产品。但几乎所有社交网络和搜索引擎都不会允许你在没有相关司法管辖区许可证的情况下投放广告。
_做得好_。你 应该 因为创造那些实际上毁掉人们生活的产品而面临社会污名。
作者: b40d-48b2-979e | 发布于: 2026-04-24 13:05
17. _fw 在“韩国警方因发布AI生成的逃跑狼照片逮捕一名男子”下发表新评论
你是想告诉我,在公元2026年的今天,竟然有人因为字面意义上的“狼来了”而被逮捕(无论对错)?
一个大约2500年前的寓言,因为AI而在今天依然适用,这真是有种滑稽的诗意。
作者: _fw | 发布于: 2026-04-24 10:10
18. Ladioss 在 “DeepSeek v4” 中的新评论
每次看到美国人自认为在道德上比中国高一等时,我都觉得这是大众宣传力量的生动体现——尽管他们每隔半年就会在全球某个地方,要么为了石油,要么代表以色列,发动一场新的战争。
作者: Ladioss | 发布于: 2026-04-24 07:45
19. chvid 在“DeepSeek v4”中的新评论
美国发起的科技战所展现出的惊人傲慢与狂妄——看着它逐渐瓦解,实在是一件美妙的事情。
撇开中美竞争不谈,LLM(大型语言模型)的真正价值将在应用层得以体现。随着LLM的商品化以及缺乏明确的垄断格局,这一领域充满了无限可能。
曾几何时,LLM似乎会成为某个严密守护的垄断者的专属领域——那将是一个极其黑暗的世界。幸运的是,我们并未陷入那种境地,现在仍有充分的理由保持乐观。
作者: chvid | 发布于: 2026-04-24 07:19
20. hodgehog11 在 “DeepSeek v4” 下的新评论
这里有不少关于基准测试和编程性能的评论。我想就它在活跃研究场景中处理数学问题的能力,提供一些个人看法。
我收集了一系列硕士和博士级别的新颖概率与统计问题,难度各不相同。我的测试流程是:先让模型处理这些问题(通常需要提供2-6篇论文作为背景),然后要求它给出严谨的证明作为后续。由于这些问题相当棘手,没有量化的性能指标,我只是根据输出在勾勒出有望发表的解决方案方面的有用性来评判。
在这个模型出现之前,Gemini 表现最好,GPT-5 紧随其后。其他模型都远不及这两者(不,连 Claude 也不行)。Gemini 有时会对一些较难的问题给出惊人的洞见(对相关程序的有洞察力的猜测在研究中最有用),但两者在单次后续提示中勾勒出具体证明方面都表现挣扎。而这款开启最大思考模式的 DeepSeek V4 Pro 在这方面做得非常出色。它在首次回复中的洞见水平不如 Gemini(更接近 GPT-5),但在后续回复中往往表现更好,而且证明过程令人印象深刻;在好几个案例中几乎完整。
考虑到 Gemini 和 DeepSeek 在 token 性能上也似乎领先,我猜测这可能对它们处理这类问题的能力有影响。这很可能更多是在合理的计算预算下,它们能走多远的问题。
尽管基准测试结果似乎并非如此,但这对于开源权重模型来说,感觉是一次巨大的进步。向 DeepSeek 团队致敬!
作者: hodgehog11 | 发布于: 2026-04-24 07:11