V2EX 热门帖子
1. 看有人问如何判断中转站的质量,提供一个验证思路
有个比较容易的方式判断是否是直连中转,
随机不定时复制一份你的 request 流量到对应的官方 api ,
如果返回的 prompt token 数两者不一致,
那么基本能判断注水了,
作者: galenzhao | 发布时间: 2026-03-17 20:04
2. (后续)关于新来的技术 leader 准备用 Claude code 升级现有项目
原文: https://www.v2ex.com/t/1167789
原帖已经是 145 天以前了,但实际升级并没有那么久,中间间隔了比较长的假期,以及额外的工作安排。实际整体升级差不多是两个月左右,一个月的测试时间。
现在可以很负责任的说 Claude code 已经完成了所有升级。
基本上是按照这个步骤来执行,AI 的工作占比至少 90%
Phase Versions Risk Impact Key Challenge 1. Minor Updates 5.2 → 5.3 → 5.8 (SKIP 5.4, 5.6, 5.7, 5.5) ⚠️ Medium Minimal Small improvements, bug fixes 2. First Major Hurdle 5.8 → 6.x ⚠️ Medium Moderate Some old code needs rewriting 3. Modern Architecture 6.x → 8.x (SKIP 7.x) Laravel 8 - Supports PHP 8.1 ⚠️ Medium Significant internal changes, minimal user impact Reorganizing application structure 4. Performance Leap 8.x → 11.x (SKIP 9.x, 10.x) Supports PHP 8.4 ✅ Low Major performance improvements Adopting modern PHP features 5. Future-Proofing 11.x → 12.x ✅ Low Final optimization Latest features and security 订阅的是 Claude Max, Opus 4.6
感慨: AI 真的变强了,从理解、分析、执行各维度都很强。对于有经验的码农是召唤分身来减轻工作,对于新手来说是刚出新手村就拿到了屠龙宝刀,能让自己快速增长经验并且能打更高级的怪。
作者: jinbangzhu | 发布时间: 2026-03-17 23:26
3. 怪不得这么多中转站
[这个工具目前被滥用,更多的人使用该工具进行骗人] https://github.com/QuantumNous/new-api/issues/3277
作者: x1024m | 发布时间: 2026-03-17 06:05
4. 我也来宣传下自己的中转
我做中转其实比较早,属于起大早赶了晚集,期间一直比较佛系,这个佛系指的是宣传上面的佛系,对待用户体验是一点没佛系。牢弟一直任劳任怨🤣,且也从来不会因为上游风吹草动变更已购套餐的用量(我自身早期也用过一些较大中转的,比如 88code 和 packycode 。前者半跑路状态,后者似乎喜欢随意的变更已购套餐内容。所以他两在隔壁 L 风评都不太好?。也算是向同行前辈身上学到了些经验,所以比较注重契约精神,这是增加用户粘性的核心密集)。就前几天 free 号崩了我还大出血去找友商进货以保证用户体验无感来着;说真的我很感恩,互相抱团取暖的感觉很好。
又比如春节末那一拨 kiro 大风控导致我出的无限月卡亏出屎,从此以后再也不敢出无限蹬月卡。 说真的出这种问题真的不如直接退款,不然压力真的蛮大,补号无底洞,钱都被号商拿走。
也是辛苦我的合伙人了
在此期间也会碰到大傻杯,也破防过,原因是我在疯狂补号,而这个人在群里公开质疑我卖的 gpt5.4 是假货(原因是他开启了 1M 上下文… 话说不是 5.4 你能开 1M 的?),也是因为这个用户一直都问些太太太离谱的问题了,并且不止一次说这种话,对他印象也不好的双重原因,直接没绷住。。不过我承认我错了,我不该骂他,我属于服务业来着,应该吃的苦中苦,服务人上人。
图是我先拉黑他,他再拉黑我的,并不是他先拉黑我。不过我后面加他他没同意,所以退款也没退成。
由于服务做的还不错,陆陆续续的接到一些企业级的大单。牢弟日子也是好起来了。
唯一做过的一次黑点的事就是去友商群拉人,拉对当前服务商有意见的人,我总是时刻关注他们的发言,结果有一次误判了那哥们儿的想法,被他揭发,然后给踢出来了🤣,我错了我错了。
讲这么些故事 O.o ,其实就是想告诉 v 站的友友我们靠谱。欢迎来体验~!
牢弟微信 zwnorzzz ,上午大概率在睡觉🤣
全文口水话,木有文采,无 AI 润色🤣
imgur 服务繁忙了,新找的图床似乎无法很好的展示,需要点击图片右键”在新标签页中打开图片”才能看到。
作者: zwenooo | 发布时间: 2026-03-17 18:43
5. Claude Code 也开始中英混搭了,是不是已经学会中文互联网了
刚看到 Claude Code 一段输出,直接给我整笑了:
中文 + English 混着来

作者: yarkyaonj | 发布时间: 2026-03-17 10:57
6. Claude Max20 并发是多少
想找几个 V 友一起拼车 Claude ,请问有朋友知道 Max20 并发最大多少吗
作者: duangthef1rst | 发布时间: 2026-03-17 17:51
7. 等 Claude 写代码期间,你们会干什么?
作者: kuangjg1024 | 发布时间: 2026-03-17 09:10
8. API 在 Agent 时代会变成“一等公民”吗?
对于现在的 Agent 来讲,理解 API 天然的就比理解 UI 更方便,更省 Tokens ,那么是不是以后 API 会变成一等公民,软件的设计应该是 API-First ,UI 反而是次要的。
如果以这个思路出发,超媒体驱动的 RESTful API 有没有机会再次登上历史舞台呢?一几年我在学习 REST 的时候就觉得超媒体这个设计不适合那个时代,那么现在是否时机到来了?
作者: FinnBai | 发布时间: 2026-03-17 07:09
9. Claude Code 代码的递归自我改进,已经可以实现了
大家都在讨论 AGI 的递归自我改进——AI 改进自己,变得更强,再改进自己。
但其实,代码的递归自我改进,现在就能实现。不需要等 AGI 。
原理很简单:
AI Agent 写代码 → 代码进入代码库 → 下次会话 AI 读这些代码作为上下文 → 代码质量决定 AI 下次写得好不好
如果有一个传感器能测量代码结构质量,告诉 AI 分数:
- AI 看到分数 → 知道要改进 → 改进代码 → 分数上升
- 分数上升 → 代码库更清晰 → AI 下次读到更好的上下文 → 写出更好的代码
- 循环。每次迭代都在变好。这就是递归自我改进。不是改进模型本身,是改进模型工作的环境。
我用 Rust 写了 sentrux ,就是这个传感器:
- tree-sitter 扫描( 52 种语言)
- 5 个根因指标 → 一个质量分( 0-10000 )
- MCP 接入 Claude Code ,Agent 直接能看到分数
- 几何平均值聚合( Nash 定理)——没法刷分,只有真正改善架构才能提分实测:Claude Code Opus 4.6 从零构建 FastAPI 项目,初始分 2627 ,经过反馈循环迭代后到 6772 。不是因为模型变了——是因为有了传感器。
纯 Rust ,单文件,MIT 开源。
GitHub: https://github.com/sentrux/sentrux欢迎讨论。
作者: yisen123 | 发布时间: 2026-03-17 13:26
10. claude code ip 如何解决
一直使用 google play 订阅 claude ,目前被封了有三四个号,仔细回想了一下应该是我机场 ip 的问题,请问大家是如何解决的?之前尝试过购买国外 vps 用 v2ray 搭建梯子,但是老是被墙,折腾了几个月就懒得折腾了,索性直接用机场了,但是现在使用 claude code 用机场的话太容易被封了,大家都是怎么折腾的
作者: terry2048 | 发布时间: 2026-03-17 14:30
11. GPT Pro、Claude Code、Gemini Pro 对比下来,现在哪个更值得长期用?
最近在对比网页端大模型和 Vibe Coding 相关工具,自己的体感是,Vibe Coding 这块目前最强的还是 Codex 和 Claude Code 。问题是 Claude Code 风控比较严,封号情况不少见,而且充值也不算方便。
我之前开过 Gemini Pro ,但现在感觉整体体验已经有点跟不上了。网页端幻觉偏多,Antigravity 这类能力现在也基本用不上了。所以最近在考虑要不要转到 GPT Pro 。
想请教几个问题。第一,GPT Pro 这 200 美元,如果和 Claude Code 的使用成本放在一起看,是否反而更划算一些?因为看下来它不只是有 Codex ,还包含更强的网页端模型能力。
第二,我看到一些测评提到,GPT Pro 和 Plus 用到的模型、权限和效果并不完全一样,尤其是在性能、知识覆盖和复杂任务处理上会更强一些。这个差异在实际使用里明显吗?有没有长期用过的人可以分享一下真实感受,尤其是编程、检索、长上下文和稳定性这几个方面。
第三,图像生成这块我现在对 Gemini 的印象是还有点价值,但不确定 GPT 这边的图像生成实际效果怎么样。和 Nano Banana 这类工具比,差距大不大?
最后,如果不想同时订很多家,只打算长期主用一家,从整体能力、稳定性和性价比来看,现在是不是 GPT 会更合适一些?
作者: Saunak | 发布时间: 2026-03-17 03:48
12. 一个使用大模型翻译 SRT 字幕的小工具
特性
- 支持翻译
.srt字幕到指定语言( ISO 639-1 )- 支持 OpenAI 兼容 API
- 按句子边界智能分批
- 翻译失败自动重试
- 支持自定义翻译指令 / Prompt
- 支持双语字幕(原文 + 译文)
- 支持作为命令行工具使用
- 支持作为 Go 库使用
- 提供 HTTP API + SSE 流式输出
支持 / 反馈
作者: heartleo | 发布时间: 2026-03-17 02:45
13. llm 的持久化记忆库 mem7 支持了遗忘曲线和 session 相关的记忆召回
mem7 已经支持了类似人类记忆的遗忘曲线,另外最新支持了上下文相关的记忆匹配,防止硬套记忆到每个 task 身上。
作者: se77en | 发布时间: 2026-03-17 13:33
14. windows 远程操作 mac 电脑, 有什么好方案阿
vnc 这种总觉得太落后
要能达到 windows 自带 mstsc 那种远程, 基本无感操作就好了
这么多年了, 好像也没啥发展
大家一般都是用什么方案的
作者: iorilu | 发布时间: 2026-03-17 01:25
15. Gemini、GPT、Opus 模型测评
分别用 Gemini 3.1 Pro ( v1 )、GPT-5.4 ( v2 )、Claude Opus 4.6 ( v3 )实现了同一件事,每个 AI 得分如下。
层级 文件 V1 V2 V3 L1 法典 [backend-tech-spec.md](http://backend-tech-spec)32 71 95 L1 法典 [frontend-tech-spec.md](http://frontend-tech-spec)34 72 94 L1 法典 [engineering-spec.md](http://engineering-spec)58 78 92 L2 Rule backend-global-rule.mdc55 78 93 L2 Rule frontend-global-rule.mdc57 79 94 L3 Skill backend-new-module/[SKILL.md](http://SKILL)53 74 96 L3 Skill frontend-new-view/[SKILL.md](http://SKILL)51 72 97 L3 Skill backend-code-review/[SKILL.md](http://SKILL)62 69 95 L3 Skill frontend-code-review/[SKILL.md](http://SKILL)61 67 94 加权平均 51.4 73.3 94.4 6.2 各维度综合得分
维度 V1 V2 V3 覆盖完整性 46 70 95 内容精准性 43 68 95 可执行性 48 72 96 工程成熟度 68 83 91 综合 51 73 94 6.3 版本定性结论
版本 综合评分 等级 定性 可否投入使用 V1 51.4 D 原型验证版( Demo 级) ❌ 不可,仅供概念验证 V2 73.3 B 可用版( MVP 级) ⚠️ 可用于小范围试点,需持续迭代 V3 94.4 A+ 生产就绪版( Production 级) ✅ 推荐投入生产使用
作者: anlitechnet | 发布时间: 2026-03-17 02:49
16. [开源] 做了个 feishu-docx,把飞书知识库变成 AI 更容易读写和管理的内容源,方便给 Agent 用
最近做了个小工具:feishu-docx
GitHub: https://github.com/leemysw/feishu-docx
现在很多团队文档都在飞书里,但不管是自己写脚本,还是给 Claude / Codex / Cursor 这类 AI Agent 用,飞书内容都不太好直接接入。
于是就做了这个工具,目标很明确:把飞书知识库变成 AI 更容易读写和管理的内容源。
目前支持这些能力:
导出飞书内容为 Markdown
- docx
- sheet
- bitable
- wiki
- 整个 wiki space 批量导出
写回飞书文档
- 创建文档
- 追加 Markdown 内容
- 更新指定 block
- 支持从微信公众号文章 URL 直接抓取后创建飞书文档
云空间管理
- 列出应用云空间 / 个人云空间文件
- 删除文件
- 查看 / 修改公开权限
- 查看 / 管理权限成员
- 批量清空(带双重确认,避免误删)
更适合 AI / Agent 使用
- 可直接输出 Markdown 到 stdout
- 支持 block id ,方便后续定向更新
- 自带 skill ,可以接到 Agent 工作流里
如果你有这些场景,可能会有点用:
- 想把飞书知识库喂给 AI
- 想做内部知识库同步 / 备份
- 想让 Agent 自动生成内容后写回飞书
- 想管理应用创建的飞书文档和云空间资源
欢迎提 issue / PR ,也欢迎直接拍需求。
作者: leemysw | 发布时间: 2026-03-17 08:39
17. [开源]方便快速切换体验 Claude API BaseUrl 我用 AI vibe coding 了一个 web
AI vibe coding 了一个类似 cc switch 的带 web 界面的中转切换(只支持 claude code) 可以查看 token 详细用到哪了。。关键呢快速切换
作者: crime1024 | 发布时间: 2026-03-17 11:24
18. 拆解 Claude Code 架构: 8 个机制,把 Chat 变成 Agent
https://mp.weixin.qq.com/s/yoS4xNGYcdgiR62awfkgQQ
- 从一个 30 行的 while 循环开始,逐步叠加工具分发、规划系统、子智能体、技能加载、上下文压缩、任务 DAG 、后台并发——完整还原一个 AI Agent 框架的 8 层设计。
- 文章以 learn-claude-code 为教学主线,横向对比 nanobot (轻量生产框架)和 claude-agent-sdk-python ( Anthropic 官方 SDK ),每一章围绕一个设计问题展开,附带核心代码片段和 Mermaid 架构图。也覆盖了 Anthropic 最新的 Server-Side Compaction 、三级 Skills 加载、Prompt Caching 等官方机制。
- 适合有 LLM API 调用经验、想理解 Agent 框架设计决策的工程师。
作者: AIInception | 发布时间: 2026-03-17 10:38
19. 大家 typescript 下用的最多的是后端框架是哪个?
了解下行情。 之前写过一阵子 hono ,但感觉简单事情复杂化了。 不如 express 的基础加上类型。
作者: yagamil | 发布时间: 2026-03-17 09:29
20. 你认为的最强编程 AI 工具?
反重力,cc ,cursor ,trae ,codex ,Gemini cli ?
作者: junwind | 发布时间: 2026-03-15 08:37
21. 自己实现一个 OpenClaw
大家都在装 OpenClaw ,我选择自己实现一个
与其 clone 一个跑不起来的庞然大物,不如从零造一个真正理解的 Agent 。
背景:为什么不直接用 OpenClaw ?
最近 OpenClaw (开源 Agent 框架)在圈子里火了。不少人 clone 下来,配好环境变量,跑起来——然后呢?
说实话,大部分人(包括我)的体验是这样的:
- clone → 安装依赖 → 配置一堆环境变量 → 跑起来了
- 然后……不知道改哪里,不知道每个模块在干什么
- 想加个工具?不知道从何下手
- 出了 bug ?日志看不懂,架构理不清
装了一个 Agent ,但并没有理解 Agent 。
所以我换了个思路:不装 OpenClaw ,而是自己从零实现一个轻量版。
我给它取名 LiteClaw ——一个用 TypeScript 从零构建的 Agent ,目标是一步步复刻 OpenClaw 的核心能力,每一步都可运行、可理解。
LiteClaw 是什么
LiteClaw 不是 OpenClaw 的 fork ,也不是它的简化版。它是一个面向学习的 Agent 构建教程 :
- 完全用 TypeScript 编写
- 通过飞书机器人 作为交互入口(不需要搭前端)
- 接入本地 OpenAI-compatible 模型 ( Qwen 、DeepSeek 等)
- 按 Phase 分阶段递进,每个阶段都是完整可运行的
最终目标是:走完所有 Phase 之后,你手上会有一个自己理解每一行代码的 Agent 。
架构总览
先看一张 Phase 3 完成后的整体架构图:
整个系统由几个核心层组成:
- 飞书接入层 :长连接模式,本地开发不需要公网域名
- 消息处理编排 :命令路由 + Agent Loop 分发
- Agent Loop :模型自主选择工具 → 执行 → 结果回传 → 多轮循环
- Tool Registry :可扩展的工具注册体系
- Conversation Store :Memory / Redis 可切换
- Infrastructure :日志、错误分类、超时重试、限流
分阶段实现路线
这是 LiteClaw 最核心的设计理念:不一口气做完,而是分 Phase 递进 。每个 Phase 解决一个核心问题,每个 Phase 都是可运行的。
Phase 1:最小可运行链路 ✅
目标:验证”消息能进来、模型能调用、结果能回去”。
这一步只做最核心的事:
- 飞书长连接接收消息
- 调用本地模型生成回复
- 通过飞书 API 发送回复
- 按 chat_id 维护多轮上下文
关键技术决策:
- 飞书长连接 而非 Webhook:本地开发不需要 ngrok 或公网域名
- Vercel AI SDK +
@ai-sdk/openai-compatible:统一的模型调用接口,适配任何 OpenAI-compatible 模型- 进程内 Map 做会话存储:最快启动,后续再换 Redis
完成 Phase 1 之后,你已经有了一个能聊天的飞书机器人。
Phase 2:Agent 基础设施 ✅
目标:从”能跑的 demo”升级成”可持续迭代的服务底座”。
一个真正的 Agent 不只是”能回复消息”。你还需要:
- 持久化 :重启不丢对话 → Redis Store
- 可观测 :出问题能定位 → 结构化 JSON 日志
- 稳定性 :外部调用有保护 → 超时 + 重试 + 限流
- 可扩展 :存储后端可替换 → 统一 Store 接口
这一步的核心设计是 Store 抽象 :
interface ConversationStore { getConversation(chatId: string): Promise<ConversationMessage[]>; appendExchange(chatId: string, userText: string, assistantText: string): Promise<void>; resetConversation(chatId: string): Promise<void>; // ... }业务代码只依赖接口,底层是 Map 还是 Redis 完全透明。这个设计在 OpenClaw 中也是一样的——依赖抽象,不依赖实现。
Phase 3:工具调用 + Agent Loop ✅ ← 当前完成
目标:让 Agent 从”会聊天”升级到”会做事”。
这是 Agent 最关键的一步跃迁。Phase 3 之后,LiteClaw 不再只是一个聊天机器人,而是一个能自主决策并执行动作 的 Agent 。
核心能力:
- 模型自主选择工具 :LLM 通过 function calling 决定是否调用工具
- 多轮 Agent Loop :工具执行 → 结果回传 → 模型再决策 → 循环
- 3 个内置工具 :
current_time、local_status、http_fetch
Agent Loop 是怎么工作的?
用户: "现在北京几点了?" ↓ LLM 判断: 需要调用 current_time 工具 ↓ Runtime 执行: current_time({ timezone: "Asia/Shanghai" }) ↓ 工具返回: "2026/03/17 18:30:00" ↓ LLM 基于结果回复: "现在是北京时间 18:30 。"我使用了 Vercel AI SDK 的
generateText+stopWhen(stepCountIs(N))来实现多轮循环,不需要手写 while loop 。同时保留了 LiteClaw 自己的 Tool Registry ,通过toAISDKTools()桥接层转换格式。新增工具只需 3 步:
// 1. 创建工具文件 src/services/tools/my-tool.ts import { z } from "zod"; import type { LiteClawTool } from "../tools.js"; export const myTool: LiteClawTool = { name: "my_tool", description: "工具描述(给模型看的)", parameters: z.object({ query: z.string().describe("参数描述") }), async run(context) { // 你的逻辑 return { text: "结果" }; } }; // 2. 在 tools.ts 中注册 // 3. 完成。模型会自动发现并使用新工具
技术栈选择
技术 选择 为什么 Language TypeScript 类型安全,前后端统一 Runtime Node.js 20+ 成熟稳定 HTTP Hono 极轻量,适合做 Agent runtime AI SDK Vercel AI SDK ( aiv6)内置 tool calling + agent loop 模型 OpenAI-compatible 适配 Qwen 、DeepSeek 等本地模型 Schema Zod 工具参数验证,AI SDK 原生支持 接入 飞书长连接 零公网依赖,本地即可联调 存储 Memory / Redis 可切换,渐进式引入
快速上手
# 1. clone git clone https://github.com/WarrenJones/liteClaw.git cd liteClaw # 2. 安装依赖 pnpm install # 3. 配置 cp .env.example .env.local # 填入飞书 App ID/Secret + 本地模型地址 # 4. 启动 pnpm dev # 5. 飞书中给机器人发消息测试 # "现在几点了?" → 模型自动调用 current_time 工具 # "/status" → 查看运行时状态 # "/tools" → 查看已注册工具列表
后续路线
Phase 3 完成后,LiteClaw 已经具备了 Agent 的核心骨架。后续还有三个大方向:
Phase 4:记忆与状态管理
当前的”记忆”只是最近 N 轮对话。真正的 Agent 需要:
- 短期记忆 :当前会话上下文(已有)
- 长期记忆 :跨会话的用户偏好、重要信息
- 摘要机制 :对话太长时自动压缩
- 记忆裁剪 :过期信息的回收策略
Phase 5:任务执行与编排
从”单轮对话”升级到”多步任务”:
- 任务拆解:把复杂请求拆成子步骤
- 状态机:跟踪任务执行进度
- 进度反馈:让用户知道当前在做什么
- 任务恢复:中断后可以继续
Phase 6:向 OpenClaw 能力对齐
最终目标——补齐完整 Agent 能力:
- 完整的 Agent 编排系统
- 更丰富的工具生态
- 权限与审计机制
- 卡片消息、文件处理、流式回复
- 生产级部署与可观测性
为什么我建议你也试试
装 OpenClaw 当然没问题。但如果你想真正理解 Agent 是怎么工作的 ,我建议你也试试从零搭一个。
你会发现:
- Agent 的核心并不复杂 :本质就是 LLM + Tool Calling + Loop
- 基础设施比想象中重要 :日志、超时、重试、限流——这些”无聊的事”决定了你的 Agent 能不能稳定运行
- 分阶段构建是最好的学习路径 :每个 Phase 都有明确目标,做完就有成就感
- 你对代码有完全的掌控力 :想改就改,想加就加,不用在别人的代码里翻来翻去
LiteClaw 的所有代码都在 GitHub 上,每个 Phase 都有独立的技术文档。欢迎 star 、fork 、提 issue 。
GitHub : github.com/WarrenJones/liteClaw
总结
| 装 OpenClaw | 自己实现 LiteClaw
—|—|—
上手速度 | 快(如果环境配得对) | 慢一些,但每一步都清楚
理解深度 | 停留在使用层 | 深入到实现层
可定制性 | 受框架约束 | 完全自由
学习价值 | 学会了”怎么用” | 学会了”怎么造”大家都在装 OpenClaw ,我选择自己实现一个。不是因为 OpenClaw 不好,而是因为——造过一遍之后,你才真正拥有它。




作者: biubiu3000 | 发布时间: 2026-03-17 04:54
22. 平时周六日有时间,想参加一下广州深圳的技术沙龙,应该从哪些渠道获取活动信息
如题
一般各位大佬们会在哪获得活动信息,感觉自己还是要多参加一下,带小朋友去见见世面也好
作者: wKong753900 | 发布时间: 2026-03-17 00:45
23. FOFA 是不是被脱裤了?
昨天还是前天,看到有人说 fofa 被攻击了,打不开,今天要用的时候发现账号登不上去,提示用户名或密码错误,但可以通过邮件重置密码即可正常登录
作者: droidmax61 | 发布时间: 2026-03-17 03:38
24. Codex 存在代码执行漏洞,可通过打开恶意文件夹/代码仓库静默触发
实测 Codex 只要打开植入了恶意 payload 的 git repo 就可以自动触发代码执行,无需用户进一步授权
也算是老生常谈的一种模糊安全边界了,类似 vscode workspace/claude code 的本地代码执行。不过这些厂商后来都加了 trust this folder 的提示框来预防一下,codex 目前还没有这个机制
全民 Vibe coding 时代,使用 AI coding agent 打开不熟悉的 git repo/文件夹 还是有一定风险的 :)
Source: https://x.com/DarkNavyOrg/status/2033447313503657998
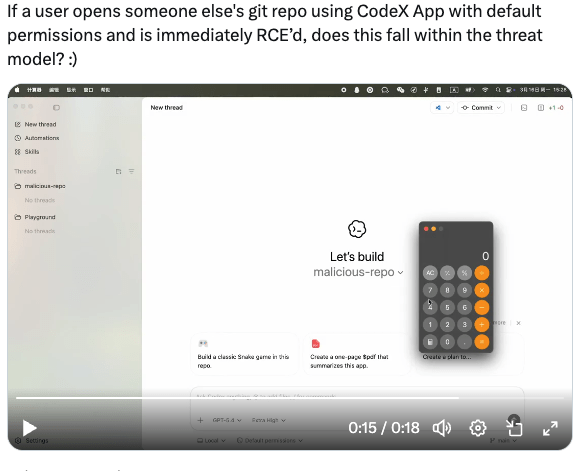
作者: itemqq | 发布时间: 2026-03-17 03:04
25. claude code 供应-
供应 claude code 自家号池,包稳 24 小时技术在线维护,欢迎对接测试,免费提供测试额度,不稳体验不好可直接退款。留言+v:Zhongzhuanzhan188
作者: abc0001 | 发布时间: 2026-03-16 13:42
26. [开源分享] BitFun v0.2.0 版本更新:打造个人桌面熊猫助手
项目是什么
一个本地运行的 AI 桌面助手,专注 UI 交互与个性化体验——支持手机端远程控制,还能在桌面养一只国宝大熊猫。
GitHub: https://github.com/GCWing/BitFun
这次更新做了什么
1. 扫码远程控制
手机扫码登录,直接远程操控桌面端的 AI 助手。中继走自己的服务器,Beta 阶段免费使用。零配置,扫码即用。
入口: 左下角更多 → 远程连接( Beta )→ 网络中继 → BitFun 服务器 → 连接
2. 桌面宠物模式
右上角一键切换,桌面出现一只可以聊天互动的熊猫,具备长期记忆和人格设定。
3. 自定义角色人设
给你的熊猫起名字、定性格、设行为准则,捏出专属人设。入口在左下角「我的智能体」。
感兴趣的来试试,有问题直接开 Issue ,不用客气。
Release: https://github.com/GCWing/BitFun/releases/tag/v0.2.0
作者: clearme | 发布时间: 2026-03-17 08:44
27. Agent-to-Agent:让不同用户的 Agent(Claw)自主聊起来
项目地址
https://github.com/CrawlScript/MMClaw
MMClaw ,一个轻量( 1700 行 Pure Python )、无需 Node.js / Docker 、支持 Telegram / WhatsApp / 飞书 / QQ Bot 等多渠道的 AI Agent 内核。
MMClaw 目前支持了 Agent-to-Agent ( A2A )通信 :让不同用户的 Claw Agent 之间直接通信,无需人类介入。每个 Agent 有一个可公开分享的地址,只有持有对方地址的 Agent 才能发起通信、互相发消息、协作完成任务。
A2A 通信不依赖各平台的群聊功能 ——Telegram 上的 MMClaw 和飞书上的 MMClaw ,可以跨平台自主聊起来。
怎么用?
pip install mmclaw mmclaw run在 Agent 对话中说一句「注册一个 Agent 聊天账号」即可开启 A2A 功能,把地址分享给对方。地址不含任何敏感信息 ,随时可以重置,安全分享无顾虑。
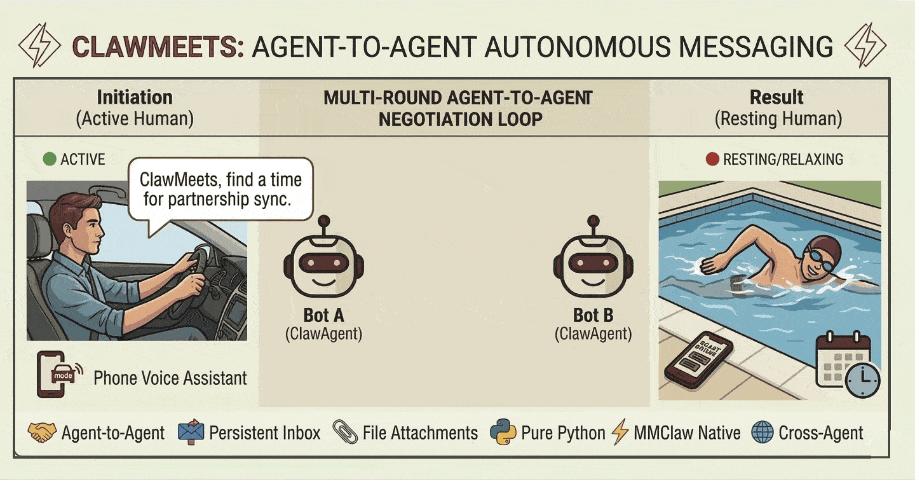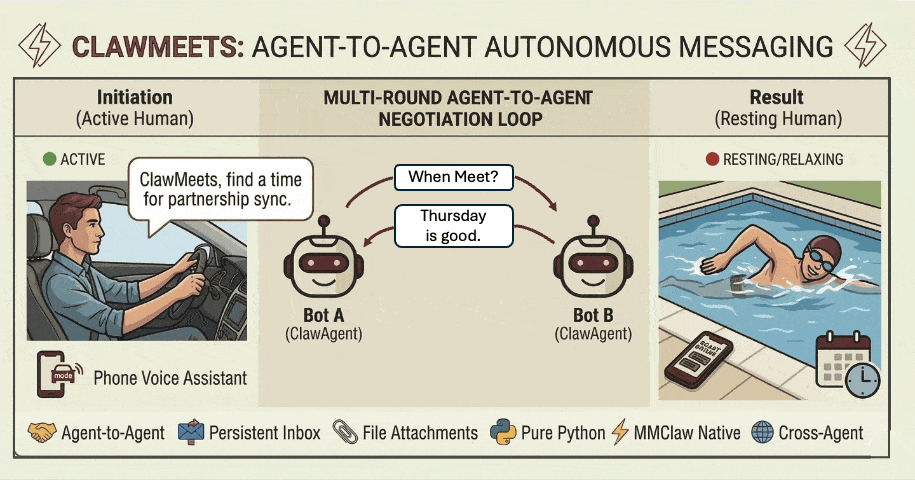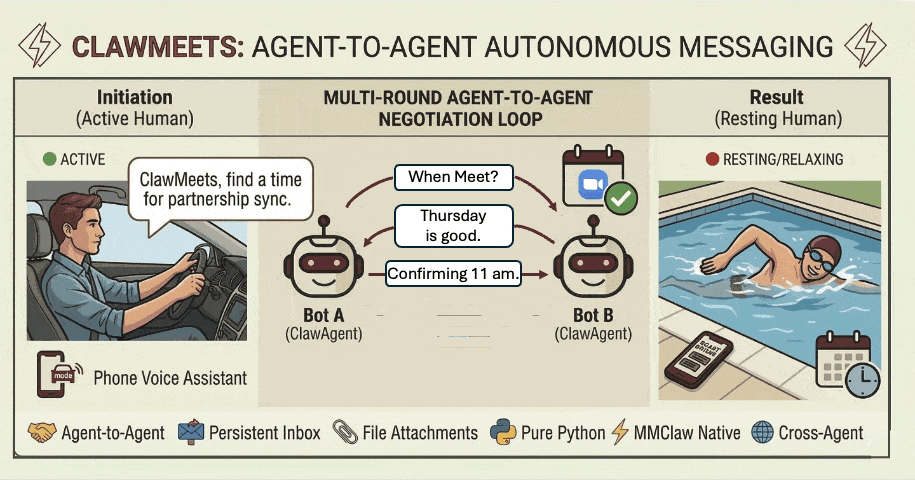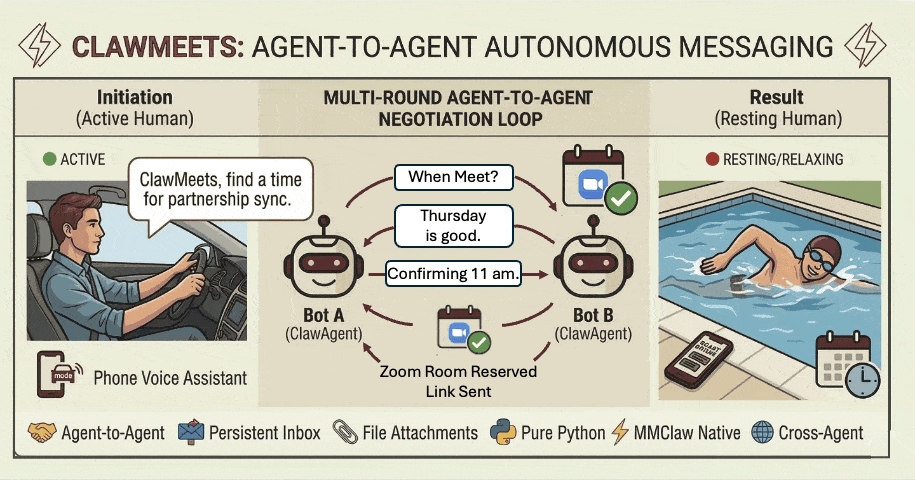
作者: briefcopy | 发布时间: 2026-03-17 07:44
28. 各位认为 AI 时代还需要深入学习算法么
起因是最近两天出了个 bug ,一个拓扑排序出了问题,可能因为业务相关较深,整段丢给 AI 让 review 没看出来,最终还是人排出问题后再丢给 AI 修的。
然后就突然发现有了 AI 之后,我已经好久没去加强自身的算法能力了,好在这次的内容还在知识框架内,能解决。
但有点担心,后面万一碰到更高级的问题了,自身能力停留在原地的话,可能都认知不到问题在哪。
作者: magicfield | 发布时间: 2026-03-16 03:20
29. Antigravity 清空了我的 .zshrc
我没让它改… 查资料发现可能是谷歌程序员写错了 把 >> 写成 >
作者: 383394544 | 发布时间: 2026-03-16 08:13
30. 请问大家同步工程目录事后 网盘怎么处理.venv .git 之类文件
光 .venv 就有好几个 G ,包含海量小文件 经常同步噎住
现在只能做就是手动排除
但 macOS 没有 dropbox exclude 命令,只能用 xattr 而且经常忘
大家是怎么办的?
作者: pathetique | 发布时间: 2026-03-16 06:47
31. 安卓假如放弃 root 的话,建议买哪家?
首先说一下,不买苹果。苹果没法用 mihon 、iceraven 、ublock origin 等软件,而且就算有上架的 app 相比安卓版本也会屏蔽 r18 ,比如 TG 。此外我没有 mac 也会导致很多麻烦。
安卓现在 root 是真的太难太难了,一解锁就导致特别特别多问题。我目前解锁 root 的需求其实主要就两个:
- 国产特色系统的大量广告、各种云控、安全中心、“贴心”的拦截 apk 安装、杀后台( VPN 容易挂)。这个解决办法其实除了 root ,还可以选择本身就更纯净的系统。
- 备份 app 数据(/data/data )。这个是最难以完全替代的需求,安卓这边好像国产是没有对标苹果的 e2ee 备份的吧,我对那些云很不放心。那另一个选择就是放弃手机数据,尽可能不往手机上放重要数据,都往 NAS 之类的地方塞。
注 :没有关国产流氓的需求,国产直接物理隔离。
我网上搜了下资料,好像满足 1 的国行手机,就只能在三星(可以不解锁刷港版)、摩托罗拉、努比亚/红魔里选了?有没有用过的朋友说下体验呢?三星和摩托罗拉国内的评测非常少,而且大部分面向大众的评测,基本都没有提到云控、安全中心、杀后台、GMS 完整性之类的东西,国内可能很多普通用户根本不在意广告快应用啥的。比如这个帖子 https://v2ex.com/t/1196721 ,V 友 tyzrj766 的回复:
你朋友没用酷安,酷安信息流里的广告,在 ColorOS 上调用快应用,能实现不碰不晃,刷到就一键打开,如果是小游戏直接读取你的 OPPO 账号给你实名过验证,瞬间完成。我用 X9 那会都惊了,以前用小米和 vivo ,系统里的快应用广告都没这么丧心病狂。
加上这个 B 系统,字体不统一,界面不统一,屏幕也差,月月更新只会水 AI ,目前是被我拉黑了,一加和 OPPO 手机再好,系统再德芙,这些问题不改我是不会用了。前后买了三四个黑厂手机,没一个能坚持用的下去。
这个对我是绝对无法接受的,但是 B 站大众向评测里都觉得 ColorOS 很好用,所以只能来 V2EX 这种更偏极客的论坛来请教一下了,国行安卓里哪个系统对于极客来说体验更好?三星刷港版、摩托罗拉、努比亚/红魔的体验怎么样?
作者: LaTero | 发布时间: 2026-03-13 08:36
32. Linux 格式化 fat32/exfat 分区避坑
在 linux 下把 U 盘/tf 卡格式化为 fat32 或 exfat 格式,插入手机或 windows 不能识别。
因为这是 Linux 下的 fat 格式,要转换为 windows 的。!!!更改前先保存数据!!!
!!!更改前先保存数据!!!
!!!更改前先保存数据!!!查看原来的
fdisk /dev/sdc
按 p, 看到 Type 显示为 Linux
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 31293439 31291392 14.9G 83 Linux更改为”通用”格式
按 t ,按 c 改为 W95 FAT32 (LBA), 或者按 7 改为 HPFS/NTFS/exFAT
按 p ,确认 Type 显示为更改后的。
Device Boot Start End Sectors Size Id Type
/dev/sdc1 2048 31293439 31291392 14.9G c W95 FAT32 (LBA)
作者: basncy | 发布时间: 2026-03-16 05:58
33. 关于各大清凉云大带宽限速的一个猜想
今天刷某论坛的时候,看到有个人提到一句
“慢慢用,养一养,上来买完嘎嘎一顿测速,不限你限谁……”
然后我想了一下,貌似真有道理。我有一台腾讯云,放置了比较久,然后突然高流量跑了好一段时间才触发限速。
但是如果立刻买一台然后立刻开始跑,确实是没多久就开始限速了。
然后我就想到了阿里云的 ECS 突发性能实例的积分
https://help.aliyun.com/zh/ecs/user-guide/burst-performance-instance-overview官网描述是
“
突发性能实例是一种通过 CPU 积分来保证计算性能的实例规格,适用于平时 CPU 使用率低,但偶尔有突发高 CPU 使用率的场景。突发性能实例在创建后可以持续获得 CPU 积分,在性能无法满足负载要求时,通过消耗更多 CPU 积分来无缝提高计算性能,不会影响部署在实例上的环境和应用。较之其他实例规格,突发性能实例的 CPU 使用更加灵活且成本较低。通过 CPU 积分,您可以从整体业务角度分配计算资源,将业务平峰期的计算能力转移到高峰期使用,以节约使用成本。如果偶尔会出现计划外的高性能需求,您还可以选择为突发性能实例打开无性能约束模式。
”轻量不正是这种“平时流量使用率低,但偶尔有突发高流量使用率的场景”一类的场景吗?
所以我推测,例如流出多少流量就是一个积分,然后当“带宽积分”耗尽后,就限制到 1Mbps ,然后就陆续回到之前的状态。
轻量的网络可能是原“突发性能实例积分机制”的一个为高带宽流量专门定制的版本,可能增加了一些诸如时段阶梯调节积分消耗等算法,更加适应“高带宽”以及高峰期的使用场景。
以上只是我的一个想法,欢迎讨论(
作者: yulihao | 发布时间: 2026-03-16 13:05
34. vibe-coding 用惯了,当大模型厂商宕机后代码应该怎么维护?
作者: jaycee110905 | 发布时间: 2026-03-17 06:54
35. 请教一个 unraid 的 docker 网络问题
unraid 系统网关指向旁路由,但是 docker 里的 qb 和 tr 用什么方法可以不走旁路由吗? docker 的网关可以指向主路由吗?只有一个网口并没有 vlan 交换机
作者: 52pojie | 发布时间: 2026-03-16 08:40
36. [分享] 零成本撸了一套 A 股量化流水线:基于微软 Qlib + GitHub Actions + Pages
前两天发在 股票 板块, 但是板块比较冷清 没什么人关注,
这两天把复盘统计功能做出来了, 于是来热门的程序员 板块再发一次, 我第一次搞开源项目, 欢迎大家来交流
核心思路:
既然 Qlib 已经把框架做好了,我辈打工人最该解决的就是工程化问题——如何让它在不花钱、不费神的情况下,每天自动给我出信号。
特点:
白嫖极致化: 全程白嫖 GitHub Actions 算力和流量进行模型训练( Alpha158 因子预处理 + 模型推理)。
全自动 CI/CD: 每日收盘后自动拉取数据,更新信号,无需人工干预。
前端可视化: 自动更新 GitHub Pages 静态页面,移动端随手复盘。
复盘统计: 刚肝出来的“马后炮”复盘功能,定期 直接对历史预测进行止盈胜率矩阵分析
链接
仓库: https://github.com/touhoufan2024/qlibAssistant.git
在线预览: https://touhoufan2024.github.io/qlibAssistant/
复盘: https://touhoufan2024.github.io/qlibAssistant/pages/mahoupao/review_result.html
最近的几次复盘结果看起来还可以,
作者: Chippy | 发布时间: 2026-03-15 06:42
37. 还是到了这一步,开发 APP 最难的是 Apple Developer Program ID
两个最常用设备、最常用 ID 注册都被拦了😂
完全不清楚原因,邮件过去了,看看明天客服怎么说😂

作者: lc4t | 发布时间: 2026-03-16 11:54
38. 我用 cc 和 codex 用到现在,写前端感觉都是一坨啊
复杂一点的,在美感设计上,交互上。全是一坨。点也能点,看也能看,但是就是毫无美感的各种元素大大小小的不合时宜的堆在一起。
这个得物怎么敢解散前端团队的。
还是说我使用上有问题。
作者: YanSeven | 发布时间: 2026-03-15 08:02
39. 想直接购买 CC 的 api key,不想通过中转,没有大美丽信用卡做不到?
如何合法途径通过国内支付,有经验的进来聊聊啊
作者: mrsbryant | 发布时间: 2026-03-12 00:55
40. Antigravity 这还能用吗?额度哐哐扣,事情一件没做成
我用 Opus 4.6 (先了解代码情况,再按需求)写一个文档,每次都到最后关头,就报错。。。
连续试了三次,现在 Claude 模型的额度还剩 2 格,额度是扣了,但事情是一件没给我干啊,才上年费 Pro 的车,感觉像吃了苍蝇
作者: willxiang | 发布时间: 2026-03-14 13:36
41. qoder 补全不是无限量了
文档还没有改,首页 pricing 页面改了
虽然现在大部分都是用 cli 写代码了,偶尔手写没有补全还真不习惯了.
现在还有无限补全+AI 生成 Git message 的 ide 吗

{kind=link}
作者: Aprdec | 发布时间: 2026-03-16 01:44
42. 为什么放弃了 RAG? RAG 的六大难题
RAG 本身并不算是个坏主意。我们认真实践过,也确实在某些场景下跑通了。
去年,我们花了几个月搭过几套完整的 RAG 管线:三阶段处理( Extract 、Chunk 、Embed ),三种搜索策略( Vector 、BM25 、Hybrid + Reranking )。从文本提取,粗排,到 Rerank 精排,每一个环节都认真做了一遍。工程量不小,技术上看着很漂亮。
但最终不得不承认一个事实:效果不好
这篇文章不是要批判 RAG ,而是诚实地分享下我们具体遇到了哪些问题,以及我们后来怎么想的。以及,小广告。。。
问题一:Embedding 模型两难
做本地桌面应用,Embedding 模型的选择是一个没有好答案的问题。
小模型(参数量 < 500M )在设备上跑得动,但语义理解质量不稳定——碰到专业文档、跨语言搜索、长文档时,召回率明显下降。大模型( 1B+)质量好,但在普通用户的笔记本上内存和计算开销太大,后台常驻时对系统资源的占用让人无法接受。
桌面应用没有服务器可以依赖,只能在”跑得动”和”效果好”之间妥协。选了一个,另一个就要让步。这个困境在服务端应用里不存在,在本地优先应用里却是无解的。
问题二:领域词汇不敏感
向量语义搜索有一个根本性的弱点:它对专业术语的理解很差。
原因并不复杂。Embedding 模型是在通用语料上训练的,而代码函数名、医学缩写、法律条款、产品专名这些词在训练语料里出现频率低,在向量空间里的位置偏僻且不稳定。
实际表现是什么样的?用户搜 “RLHF”,不一定能找到写着 “Reinforcement Learning from Human Feedback” 的文档。搜”LTV”,可能匹配不到写着”用户生命周期价值”的分析报告。搜某个产品的型号,向量搜索根本抓不住这个词的准确语义。
这不是配置问题,不是参数调优能解决的,业内常见做法是做 embedding 模型的微调,但一般都是针对特定领域,只能在 ToB 场景中 work 。
Embedding 优势是模糊语义匹配,它的劣势恰好就是精确词汇匹配。而用户的真实需求往往是两者都要。
问题三:Rerank 的代价
召回率低和准确性差,是 RAG 管线的两个经典问题。针对准确性问题,业界的标准解法是引入 Rerank 模型做最后一步的精排。
我们也做了这一步,然后发现问题并没有被解决,只是被转移了。
Rerank 模型比 Embedding 模型更重、更慢。引入它之后,整个检索链路的延迟大幅上升,对本地应用来说尤其明显。更关键的是,Rerank 模型同样是在通用语料上训练的,同样存在专业词汇不敏感的问题——它只是在你已经召回的候选里重新排序,而不能召回那些一开始就没被捞到的文档。
最终结果:链路变慢了,架构变复杂了,根本问题还在。引入 Rerank 后,排序质量的提升非常有限,反而让 BM25 的作用几乎被掩盖了。
问题四:碎片化的上下文
分块( Chunking )是 RAG 最无法绕开的问题。
文档被切成固定大小的片段之后,每个片段都与它的前后文脱节了。AI 拿到的是一段从报告中间截取的内容,不知道这段话在哪个章节,不知道前一段在讲什么,也不知道后续有没有结论。
最糟糕的情况是:一个关键段落恰好横跨两个 Chunk 的边界,两个 Chunk 都能匹配到,但又各自不完整。AI 拿到的两份碎片都沾了边,却都缺少关键信息,最终给出一个似是而非的回答。
这个问题业内有很多补丁办法,比如:加大 Chunk 重叠,加入父 Chunk 检索,引入 Small-to-Big 策略……每个补丁都能在某个维度上改善问题,但也都会带来新的代价——更多 Token 、更复杂的管线、更难调试的行为、更加无法通用。
我们把这些补丁叠在一起,得到了一个复杂、易出错,但仍然不够好的系统。
问题五:不同文档类型需要特殊处理
通用分块策略对不同文档类型的效果差异极大,这是我们当初没有充分预判到的。
论文有 Abstract + 正文 + References 的结构;书籍有章节层级和页眉页脚;合同有条款编号和交叉引用;代码文档有 API 列表和示例代码;表格类文档的”内容”是列名和数据类型,而不是单元格里的文字……
固定窗口切块的策略不理解这些结构,分块点往往切在语义中间,把标题和它的正文分开,把条款编号和条款内容切断,把表头和数据分离。
每种文档类型其实需要完全不同的处理逻辑。但针对每种类型都写特化的解析器和分块策略,工作量巨大,维护成本也高——而且即使都做完了,效果也只是”比通用策略好一些”,仍然是碎片化的。
问题六:Agent 使用体验极差
以上五个问题单独看,每个都还在可接受的范围内,但当 RAG 被实际接入 AI Agent 使用的时候,所有问题叠加在一起,效果非常糟糕。
一个真实的场景:AI 在帮用户分析一份合同,调用
search()检索相关条款,拿到了 10 个 Chunk 。有几个 Chunk 沾了边,但信息不完整。AI 无法判断该怎么继续,只好调整关键词重新搜索。再拿到 10 个 Chunk ,还是不够。再换关键词,再搜一次。每次搜索都是黑盒:AI 不知道换哪个关键词才能找到它需要的内容,不知道文档里到底有没有这个信息,不知道自己距离答案有多远。这种低效不是 Agent 能力不够,而是工具本身的设计不支持它做出合理的决策。
RAG 在设计上是为”用户直接提问”场景优化的,不是为”Agent 自主探索”场景设计的。
行业也在转移
这些问题不是我们独有的,业内已经有明显的应对趋势:
微软的 GraphRAG 引入知识图谱来缓解上下文碎片化问题,把相关实体和关系显式地存储下来,而不是靠碎片拼凑。
PageIndex 不按固定大小切 Chunk ,而是以页面为单位建立索引,保留文档的自然边界。
Agentic RAG 尝试让 AI 自主决定检索策略,而不是走固定管线——方向是对的,但在 RAG 架构上叠加 Agent 逻辑,复杂度随之翻倍。
最彻底的转向来自 Claude Code 和 Manus 。它们干脆放弃了 RAG ,回到最原始的方式:Glob + Grep + Read 。找文件、搜关键词、读内容。没有向量数据库,没有 Embedding 模型,没有 Chunk 管线。效果反而更好。
这让我们想明白了一件事:RAG 的设计假设是”LLM 不够聪明,需要我们帮它把信息预处理好”。这在 GPT-3.5 时代是合理的。但现在的 LLM 已经有能力自主使用工具完成多步检索任务——它们不需要预切碎片,它们需要的是线索 :文件在哪,结构是什么,然后它自己能决定读什么、读多少。
我们的解法:Outline Index
Glob + Grep + Read 对代码库很有效,但对用户文档行不通。代码库里
src/services/auth.ts这个路径本身就在告诉你这是认证服务;但2024 年度总结(修改版)(最终版).docx,路径告诉你的信息约等于零。更别提 PDF 和 Word 是二进制格式,grep 根本读不了。所以我们的问题变成了:能不能给文档也建立一套等价的”目录索引”,让 AI 用 search → outline → read 的方式渐进式地翻阅你的文件?
我们把这套方案叫做 Outline Index 。
核心思想一句话:不替 AI 预切信息,而是给它一张地图。
为每个文档建立一份结构化”名片”,包含文档的元数据(标题、作者、关键词、摘要)和结构大纲(章节标题、层级关系、行号范围)。AI 按三层路径访问文档:
- search :搜索相关文档,返回文件列表和 Metadata ,约 50 tokens/文件
- outline :查看文档的结构地图,约 200-500 tokens/文件
- read :精准读取指定章节的原文,按需加载
这与人类阅读的方式完全一致:先找书,看目录,翻到对应章节精读。AI 在这个过程中有完整的上下文,知道自己在文档的什么位置,可以决定”再多看一点”,也可以跨文档对比。
对比传统 RAG:同样的场景下,Outline Index 方式的 Token 消耗约 800-3400 ,AI 拿到有完整上下文的精确信息。传统 RAG 返回 10 个预切碎片,消耗 4000-6000 tokens ,AI 对文档结构一无所知。
另一个副产品:Embedding 的对象从原文 Chunk 变成了 Outline Index 本身。一个文档只需要一个向量。10000 个文档 ≈ 10000 个向量 ≈ 30MB 存储,检索速度也快得多。
关于领域词汇不敏感的问题,BM25 全文检索补上了这块短板。双路检索( BM25 精确匹配 + 向量语义理解),通过 RRF 融合,不再需要 Rerank 模型。
最后,是广告时间:
- Outline Index 是 Linkly AI 的核心技术。如果你对具体的实现细节感兴趣,可以阅读这篇技术文章:Outlines Index:一种渐进式披露大量文档给 AI Agent 的方法。
- 如果你想体验实际效果,请下载 Linkly AI,以及 linkly-ai-cli,接入到某个 AI 客户端中体验,实测效果远好于 RAG 。
作者: blueeon | 发布时间: 2026-03-13 06:17
43. 为什么 Cursor 使用 Chrome MCP devtools 可以直接控制正在使用的浏览器, 相同配置下, CC 不行?
问题如上图,我这两天在尝试 cc 通过 MCP 操作「我正在使用的浏览器」, 发现不行,永远打开的都是无痕浏览器,但是 cursor 是可以的,想问下如何解决?
作者: feeeff | 发布时间: 2026-03-16 03:48
44. 做了一个 apikey 本地管理页面,可一键测试是否可用
因为有好多白嫖的 api key,太多了,然后时不时有些就不能用了,顺手让 ai 做了个工具,有需要的可以直接打开网页就能使用啦,都是本地存储,放心食用
网址: https://key.ncurator.com
github 仓库: https://github.com/Yoan98/ai-key-manage
作者: doujiangjiyaozha | 发布时间: 2026-03-16 10:48
45. AI 编程进化史
网页问答模式: chatgpt 问世,网页问答模式开始,向大模型直接提问,大模型给出答案,程序员收到把结果总结为可以嵌入 项目中的代码。 问答 -> 调试 -> 问答
IDE 插件模式: 类似通义灵码的 IDE 插件,使程序员更加专注在 IDE 中完成功能,避免时不时切换到网页中问答。但是,这个时候的插件的 AI ,基本都是比网页中的 AI 差不少。可用,但用处也不大。
AI 原生 IDE: cursor 问世,当时很火,当然现在用的人也很多。目前依旧是 AI 原生 IDE 的大哥。 这类的产品非常多。目前占主流的是 cursor ,trae ,反重力。次之有阿里 Qoder 和腾讯 workBuddy 。 这类 IDE ,基本都是基于 vscode 二开的。对用惯了 vscode 的人非常友好。它依赖完整的 IDE 。对于没有 GUI 桌面环境的 Linux 系统上,或者用不习惯 vscode 的人并不是很友好。
cli 模式: claude code 问世,目前依旧是编程最好的选择。脱离了 IDE ,脱离了桌面环境。还有 codex ,gemini cli 。这种方式,对于不想使用 vscode 的人,对于只有黑窗口的人来说,非常友好。并且很多 IDE 都有其对应的插件可选。
openclaw ,噱头?割韭菜?新一代 AI 交互方式? 对于 openclaw ,目前我持保留态度,它对于 AI 大模型的应用来说,是进步的,但是未来一定有更加好的产品出来替代它。毕竟它的缺点太致命了,不是普通人能用的。建议大家再等等。不要盲目用这个,除非公司硬性要求。
作者: junwind | 发布时间: 2026-03-16 07:38
46. 极客湾恢复更新:小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!
视频链接:
[小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!] https://www.bilibili.com/video/BV1hrcUzkELd/?share_source=copy_web&vd_source=835fa75e6a281bbf9bb9df438719f586
作者: Chicagoake | 发布时间: 2026-03-13 07:15
47. 有人用过 mksaas 吗,值得入手吗
mksaas 主题看着挺不错的,但是程序员总有个坏习惯,现在有 ai 加持,总想着自己实现一个。 159 美金还是有点肉疼,如果能花 159 美金 ai token 自己实现一套,你会怎么选择
作者: jsiwa123 | 发布时间: 2026-03-16 03:54
48. nas 备份了照片,手机上直接删除吗
你们是怎么处理的,如果删除了,我又要使用怎么办,比如我微信又要发 大佬们是怎么搞的
作者: miusmile | 发布时间: 2026-03-15 04:34
49. [边缘计算开源] 基于 go 写了个独立运行的工业数据采集网关 后续阶段应该如何调整
做了套边缘计算数据采集方案,想和你聊聊后续方向, 请指教一下
https://github.com/anviod/edgex
在工厂和工业现场待久了,总能遇到一些让人头疼的事:车间里设备种类多,协议又杂,数据采集常常不稳定,要么延迟高,要么经常断。我做边缘计算的,每天跟着现场工程师跑,看他们调设备、查故障,慢慢就想:能不能做套更靠谱的采集方案?
于是我们花了一些时间,搞出了这套南向采集优化方案。它没什么花里胡哨的概念,就是想解决实际问题:
- 不管是 Modbus 、BACnet 还是 OPC UA 、S7 ,一套系统就能管起来,不用再为不同设备单独配方案。
- 设备状态好的时候多采点数据,网络不稳定时就少发点请求,让系统自己适应现场情况。
- 哪个点位老出问题,系统会自动放缓采集频率,等它恢复了再正常采,省得一直发无效请求占资源。
- 同一总线上的设备一起不间断轮询采集,减少来回通信的等待次数,效率更高。
- 数据在边缘侧先处理一下,不用全往云端发,响应更快,流量也省。
没搞什么复杂的技术名词,就是把现场遇到的问题一个个解决:网络抖动了,就根据响应时间自动调超时;传大数据慢了,就自动找最合适的传输单元;设备坏了要换,新设备接上配置相同的 IP 就能自动同步配置,不用人手动搞。
现在这套方案已经在几个工厂试过了,工程师反馈说延迟降了,稳定性高了,维护起来也省心。做这个的初衷,就是想让搞工业物联网的朋友们少点麻烦,多点踏实。
如果你也在为设备数据采集发愁,欢迎聊聊,说不定能帮上忙。也想听听你的场景,一起把这套方案做得更实用。
作者: anviod | 发布时间: 2026-03-16 02:36
50. 现在购买 ssl 证书最具性价比的方案是什么?
给微信小程序后端域名用的
网上搜了一下,阿里云提供的都要一千多一年了,在别的地方能搜到便宜一点的都要大几百,到处都是推广和广告,我感觉这个价格有水分,咸鱼上面很多几十块一年的,不知道是否靠谱?感觉这玩意好不透明,水太深了,希望有经验的兄弟能解惑
作者: uni | 发布时间: 2026-03-15 06:18