V2EX 热门帖子
1. 从一个小功能的实现来看免费 Gemini 和 ChatGPT 的表现
前几天有个 a4 pdf 的 iOS 限免,正巧作为小学生的小朋友有把长截图转成 pdf 然后打印的这个需求,下载后发现那个 app 就是接近于垃圾,不光把长截图放在一页 pdf 上,并不能切割成多页,而且因为人为缩小,清晰的图片成了毛玻璃。
今天周末小朋友来我这里玩,我于是建议小朋友自己通过 ai 来实现这个功能。
小朋友自己的 iPhone 上有梯子且熟练使用,寒假也注册并登录了 Gemini 、ChatGPT 等,听我建议不错,于是没有我任何指导,完全不懂编程的小朋友自个儿开干。
首先打开的 Gemini ,用 fast 模式,小朋友记录下 iPhone 相册里其中一张长截图的宽✖️长的数值,和 ai 说自己 iPhone 上有这么个宽长的图片,希望能根据自己输入的宽长,分割成几张图片,并且把图片转成 pdf 好打印。
Gemini 建议 html5j+js 方案,并且吧啦吧啦生成了源码,还贴心地告诉小朋友怎么拷贝源码保存在 iPhone“文件“app 中,最后浏览器打开并通过共享变成 iPhone 主屏的一个应用。
gemini 一气呵成的果然能一次运行并达到了小朋友的需求,接下来小朋友添加了一些需求和修改意见,也基本正常实现。
然后,小朋友把 Gemini 生成的源码打开 ChatGPT 并输入让 ai 检查代码是不是完全正确,如果正确请在代码后添加解说()注释。
ChatGPT 表示程序很不错,但是它能提高好几倍的效率,还有其它优化,牛吹得小朋友期望很高,然后四五个回合,正确的代码不能正确运行,而且已有的功能和界面也被 ChatGPT 缺失或者错位,不得已小朋友请我帮忙,才总算在免费额度用完之前 ChatGPT 出来了一个正常运行的版本。
仅就这个经历的个人感觉,同样免费版的 Gemini 看起来要比 ChatGPT 强大且准确度高。另外也感叹,完全没有编程基础的个位数小孩,也能凭自己的聊天,得到完美符合自己需求的小工具了,大把普通的 iOS (安卓) app 估计越来越没多少生存空间了。
btw ,总结下小朋友自己迭代聊天后满足的需求:
1️⃣从 iPhone 的“文件”、相册、拍照三种方式导入图片
2️⃣导入后,界面显示照片的如分辨率、拍摄时间等某些拍摄信息(小朋友不知道 exif 这个词)
3️⃣界面给出宽、长数值的手工输入,同时旁边有长宽比锁定下拉框(不锁定、2:3 、3:2……A4 幅面),根据长宽比选项,输入一个数值,另一个联动
4️⃣界面给出自定义图片名称,旁边有下拉框供选择分割后的几种图片格式,分割后图片名为自定义图片名称➕序号
5️⃣点“处理”按钮后,出现一个按钮为“图片压缩成一个文件”( Gemini 建议做的),另一个按钮是“转成 PDF”,旁边下拉框可以选择每页一张,每页两张,每页 2✖️2 四张,每页六张。
这两种方式都可以把 zip 和 pdf 保存到“文件”app 里。
6️⃣界面在点了“处理”按钮后,还同时会显示所有分割后形成的图片文件,图片下面显示带序号的文件名,Gemini 教小朋友长按具体图片来保存单张图片到“相册”
作者: gigishy | 发布时间: 2026-03-15 20:04
2. 现在购买 ssl 证书最具性价比的方案是什么?
给微信小程序后端域名用的
网上搜了一下,阿里云提供的都要一千多一年了,在别的地方能搜到便宜一点的都要大几百,到处都是推广和广告,我感觉这个价格有水分,咸鱼上面很多几十块一年的,不知道是否靠谱?感觉这玩意好不透明,水太深了,希望有经验的兄弟能解惑
作者: uni | 发布时间: 2026-03-15 06:18
3. 你认为的最强编程 AI 工具?
反重力,cc ,cursor ,trae ,codex ,Gemini cli ?
作者: junwind | 发布时间: 2026-03-15 08:37
4. 我用 cc 和 codex 用到现在,写前端感觉都是一坨啊
复杂一点的,在美感设计上,交互上。全是一坨。点也能点,看也能看,但是就是毫无美感的各种元素大大小小的不合时宜的堆在一起。
这个得物怎么敢解散前端团队的。
还是说我使用上有问题。
作者: YanSeven | 发布时间: 2026-03-15 08:02
5. 如何成为 Claude Code 高阶玩家
有关使用 claudecode,目前互联网大概有两种主要内容:
- 完全面向没有基础的小白教学内容:
教你如何初步在本地跑通 claudeclode,做一个纯玩具版本的的小网页/自动化小工具 教你如何给自己的玩具加装脚手架(skill/subagent 的各种概念以及最基础的运用),让他变成更华丽的玩具
- 高阶大佬炼化十年功法,创造出 xxx 供大家使用的项目
这类内容可以类比为开源了某种特异功能,但问题也接踵而至,我真的需要如此高大尚但是不贴合我实际工作需求的功法吗?xxx 的归属大概率是躺在文件夹吃灰
我们应该如何从初学者过渡到 Claude Code 高阶玩家?
了解 claudecode 各种机理,能自己动手修改.claude,能自己添加.删减 claude.md 等各类文件 根据自己的需求,动手封装合适的 subagent,hook 知道何时应该 compact,何时应该调用以及自己规划调用多个子 agent 如何根据自己的工作流,真正提高自己的生产力
这些内容并非没有,而是十分孤立,并不成体系,所以请问大家有没有这方面成体系的相关资料,最好是自己的工作流实操,分享一些捣腾的完整分享
感谢大家
作者: cryptogems | 发布时间: 2026-03-15 15:34
6. nas 备份了照片,手机上直接删除吗
你们是怎么处理的,如果删除了,我又要使用怎么办,比如我微信又要发 大佬们是怎么搞的
作者: miusmile | 发布时间: 2026-03-15 04:34
7. 极客湾恢复更新:小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!
视频链接:
[小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!] https://www.bilibili.com/video/BV1hrcUzkELd/?share_source=copy_web&vd_source=835fa75e6a281bbf9bb9df438719f586
作者: Chicagoake | 发布时间: 2026-03-13 07:15
8. 利用 AI 像洗黑钱那样洗代码版权会不会产业化?(可能属于灰产、黑产)
最近有个行为叫做 License Laundering (洗许可证)引起了不少人的警觉。顾名思义,类似于 Money Laundering (洗黑钱),就是把利用 AI 重写代码,使得新代码的重合度与原版相差甚远,“洗”到与原作品无关,然后更换许可证。
前段时间,Python 社区的 chardet 引发了争议。现任维护者 Dan Blanchard 利用 AI 把 chardet 的代码重写了一遍,重写后的版本使用 MIT 许可证。原作者 Mark Pilgrim 已经现身反对更改许可证,因为 chardet 原先的许可证是 LGPL 。
具体分析:License Laundering and the Death of Clean Room
与此同时,还有公司更进一步,利用 License Laundering 搞恶意竞争,克隆客户的软件然后低价转卖。
很快就有人同样把“License Laundering”打包成一站式服务,嘲讽这种公司的恶意竞争行为。 “洗代码即服务!”火了!“开源代码洗白”奇葩网站上线,反讽白嫖企业:开源合规太昂贵了! CC 逆向复刻客户软件,十分之一的价格转卖!说到底,这类 Laundering 做法算不算侵权?毕竟 AI 的训练过程中的语料就有开源代码,没人能保证 AI 从未“看”过 GPL 系列代码吧。
作者: cnbatch | 发布时间: 2026-03-15 14:32
9. 很奇怪和诡异的一个传统 UDP 53 的 DNS 调度解析 和 HTTPDNS 的调度解析域名的问题?
比如某一个域名 或 某一个 HTTPDNS 或 HTTPSDNS 域名解析或者说映射了多个 IP 地址,这些多个 IP 地址可能是不同省份同一个运营商 或 不同省份的不同运营商 或 同一个省份的不同运营商,那么假设用户 A 在 A 省使用 传统 UDP 53 的的 A 省运营商 DNS 或 第三方公共 DNS 去调度解析某一个域名,有时候明明有 A 省的 IP ,但实际调度解析后返回的解决确实 B 省同一个运营商,更有甚者或者极端情况下 A 生用户可能会获取返回的是 B 省的 B 运营商的 IP 。
HTTPDNS 的调度也有上述类似的问题,请问这是为什么?难道仍是归咎于调度细粒度不精准 或 不完整支持 ECS 造成的嘛?
作者: bclerdx | 发布时间: 2026-03-15 14:42
10. 我咋感觉 1m 上下文的 opus 4.6 比 200k 上下文的 opus 4.6 要笨一点
试用了一下 1m 上下文的 opus 4.6 ,写个计划改了两三次,但之前用 200k 的 opus 4.6 基本是一次过。
是我的错觉吗?
作者: milkleeeeee | 发布时间: 2026-03-15 09:19
11. [分享] 零成本撸了一套 A 股量化流水线:基于微软 Qlib + GitHub Actions + Pages
前两天发在 股票 板块, 但是板块比较冷清 没什么人关注,
这两天把复盘统计功能做出来了, 于是来热门的程序员 板块再发一次, 我第一次搞开源项目, 欢迎大家来交流
核心思路:
既然 Qlib 已经把框架做好了,我辈打工人最该解决的就是工程化问题——如何让它在不花钱、不费神的情况下,每天自动给我出信号。
特点:
白嫖极致化: 全程白嫖 GitHub Actions 算力和流量进行模型训练( Alpha158 因子预处理 + 模型推理)。
全自动 CI/CD: 每日收盘后自动拉取数据,更新信号,无需人工干预。
前端可视化: 自动更新 GitHub Pages 静态页面,移动端随手复盘。
复盘统计: 刚肝出来的“马后炮”复盘功能,定期 直接对历史预测进行止盈胜率矩阵分析
链接
仓库: https://github.com/touhoufan2024/qlibAssistant.git
在线预览: https://touhoufan2024.github.io/qlibAssistant/
复盘: https://touhoufan2024.github.io/qlibAssistant/pages/mahoupao/review_result.html
最近的几次复盘结果看起来还可以,
作者: Chippy | 发布时间: 2026-03-15 06:42
12. 有什么网站提供人工智能学习且能够有老师答疑的
愿意知识付费 但是也别太贵了
作者: hiboshi | 发布时间: 2026-03-15 05:36
13. 通过 vibe coding 能对 ruoyi ai 二次开发吗,做点自己的应用, Java 能力只限于本科学的那点
现在是有想法,直接纯对话 ai 从零开始完成,并且可以得到想要的结果,但是没用过专业的框架,想试试
作者: 2757809858 | 发布时间: 2026-03-15 12:12
14. 做了一个自认为很有潜力的 AI 项目,大家看看有没有前途
最近做了个开源项目: https://github.com/golutra/golutra
简单说就是一个 多 Agent 的 AI 工作空间,可以组建一个 蜂群 Agent Team ,让不同 AI 协作工作,有点像搭一个 一人公司的 AI 团队,可以长期运行。自定义工作流(不同行业场景都能搭),工作流模板一键导入导出,适合长期运行的 AI 自动化系统。
后面准备做的:
实现真正的「 CEO Agent 」,一个月不用人监管,支持手机端远程操控,自动构建 Agent ,接入永久记忆层
还在早期阶段,想听听大家的评价: 这个方向有没有前途?有没有什么建议?
欢迎评论 🙏
作者: seeksky | 发布时间: 2026-03-14 18:24
15. 随机播放到艾薇儿和后街男孩的歌曲,突然发现上一次听还是 10 多年前读初高中的时候了
突然有点唏嘘,当时听他们的音乐还是用的好记星学习机,由于家离学校比较远,所以平时是住读,周五回家和周末归校的时候,就喜欢用学习机听他们的音乐,岁月不饶人啊。
作者: zzz22333 | 发布时间: 2026-03-15 00:45
16. 初学 k8s,如何解决网络下载慢的问题?
目前小弟主要是通过 ssh 到 ubuntu 物理机上,有翻墙设备,在 ubuntu 上下载了 flcalsh,但是下载 k8s 的链接就很慢,没走代理。 如:curl -LO “https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert" 下载就很慢。
作者: Debug1998 | 发布时间: 2026-03-15 07:03
17. Antigravity 这还能用吗?额度哐哐扣,事情一件没做成
我用 Opus 4.6 (先了解代码情况,再按需求)写一个文档,每次都到最后关头,就报错。。。
连续试了三次,现在 Claude 模型的额度还剩 2 格,额度是扣了,但事情是一件没给我干啊,才上年费 Pro 的车,感觉像吃了苍蝇
作者: willxiang | 发布时间: 2026-03-14 13:36
18. AI 时代下 AI 工具熟练度能代替技术深度吗?
近几次面试发现一个问题用人单位似乎更看重 AI 工具的熟练度,你说突破了某个技术难点会被认为“AI 就能做到何必自己去探索”,各种问题都能扯到 AI 上,这样很容易忽视技术深度和背后自主探索和创造所付出的努力。
我用 AI 确实能大幅提高效率,写 API 接口几分钟就搞定了,CRUD 任务描述一下需求即可快速实现,丢一份文档即可生成 MVP ,但之前做了个探索性的微服务项目的确遇到深水区,尤其是基础设施层。大致存在以下几种问题:
- 组件和框架集成存在隐形契约,官方文档没有,GitHub 无人提及,网上无人讨论。
- 框架功能设计缺陷和框架的 BUG 导致无法满足需求必须改源码还不能破坏原有的函数。
- 官方文档缺失部分内容,无参考答案,无已知解决方案。
- 官方文档仅有简单示例但没有完整落地的案例,同时需要修改底层源码。
- 框架已存在的特性,无注释,没有提及该特性的相关文档和资料。
面试官认为提示词写好加上几个 Skills 就行,实际上烧了一堆 token 还是没用,除了最后一个 AI 勉强有解其他的几乎不行,最后还是自主探索用更优雅的方式解决掉。
所以这就存在争议,技术的学习成本降低以后 AI 工具熟练度能代替技术深度吗?如果自主探索攻破难题被认为“人做得到的 AI 同样可以”,那所有的技术研究,开源项目不就没有意义?
作者: zhanshen1614 | 发布时间: 2026-03-14 09:59
19. Windows 开发真的太难了!所以自己用 Rust 搓了个 win 版 tmux,开源免费
如果你是 MacOS 或者 Linux 的开发者,你们应该感受不到这个痛点,但是 Windows 的开发环境对现在的并行开发工作流实在太不友好了!!
平常我都开好几个终端机跑好几个 Claude Code 、Codex ,光是 cd path 就得老半天,终端机不能复制粘贴图片,每次开机又得重新调整排版,更别说没有通知,有时候都不知道哪个会话需要我的回应。
另外 VSCode 现在对我来说就是单纯的阅读器而已,用它跑终端机实在太重了,所以我就自己搓了个 IDE 来用!
功能大概有:
- 自定义排版,支持窗口分页
- 支持图片复制粘贴到 CLI (我的最爱!!!)
- 自动恢复上次会话和权限
- 当 CLI 需要输入的时候,系统消息通知
- 文件树双击文件直接在默认 IDE 中打开
- 右键点击文件可以直接插入到输入框,不需要再手动打文件名
- Git 状态追踪,看到所有的 worktree 、branch 和文件变动
- 支持预设开启路径(我自己默认在 github/,这样每次能少打几个字)
- 支持预设 IDE
- 新增终端机可以选择你要的 Shell 类型,像我有时候需要跑 bash ,有时候需要 PowerShell
- 还有更多!开源免费,现在已经有超过 100 位开发者在使用了,正在快速迭代中,欢迎大家提需求!👉
https://github.com/oso95/Codirigent
目前还没有 Windows 签名(申请中),安装时点继续就好,或者照 README 跑本地版。
作者: oso95 | 发布时间: 2026-03-15 07:32
20. 独立开发收款方案
请教佬们独立开发如何解决收款问题
作者: trumpmaga | 发布时间: 2026-03-14 14:46
21. [分享] Codex + GPT 5.4 火力全开配置调优
自从 OpenAI 出来 gpt-5.4 模型后 Codex 的使用确实有了极大的提升,我个人调整配置后开发同一个需求对比使用 Claude Code + Claude Opus 4.6 还更快一点完成。
本来从 gpt-5.3-codex 的默认配置直接使用,但发现上下文一下就不够了,对于大一点的工程来说 特别难受。
后来查了下网上的资料,说 gpt-5.4 的 1M 上下文的能力要自己主动配置开启,晕。
下面放出我自己使用 Codex 的一些配置,算是抛砖引玉,不一定是最佳实践,有不同的欢迎指正。
打开 ~/.codex/config.toml 文件
project_doc_fallback_filenames = ["CLAUDE.md"] # agents.md 找不到,则找 claude.md ,和 Claude Code 使用同一份约束 model = "gpt-5.4" review_model = "gpt-5.4" # 默认 "gpt-5.2-codex" model_provider = "apibox" # 改成你自己的中转站名 model_reasoning_effort = "xhigh" # 思考强度超高 model_context_window = 1000000 # 模型上下文窗口大小,默认 1000000 ( 1M ) for gpt-5.4 model_auto_compact_token_limit = 500000 # for gpt-5.4 虽然是 1M ,但是有效注意力不够,不建议开的太高 [model_providers.apibox] name = "OpenAI" # 如果用的是中转站,建议把名字改成 OpenAI (注意大小写)命中缓存,省 token base_url = "apibox.cc/v1" # 改成你自己的中转站 API 地址哦 wire_api = "responses" requires_openai_auth = true [features] shell_tool = true # 启用 shell 工具。默认: true apply_patch_freeform = true # 通过自由格式编辑路径包含 apply_patch (影响默认工具集)。默认: false shell_snapshot = true # 启用 shell 快照功能。默认: false undo = true # 启用 undo 功能。默认: true unified_exec = true # 使用统一 PTY 执行工具 multi_agent = true steer = true prevent_idle_sleep = true child_agents_md = true memories = true # 开启记忆 sqlite = true # 可配可不配,随意 fast_mode = true # 必开,完全不同的体验,当然也会让 gpt-5.4 用量变 2 倍 [memories] # 强烈建议用新模型来总结 memories consolidation_model = "gpt-5.4" extract_model = "gpt-5.4" # generate_memories = true # 默认 true # use_memories = true # 默认 true ,表示把 memory_summary.md 注入 developer instructions max_raw_memories_for_consolidation = 512 max_unused_days = 30 # 默认 30 max_rollout_age_days = 45 # 默认 30 # max_rollouts_per_startup = 16 # 默认 16 # min_rollout_idle_hours = 6 # 默认 6小技巧:
model_auto_compact_token_limit 这个配置可以动态调整 当你的工程的会话上下文特别大的时候,你有不想开新的会话时。你可以先把这个配置改大,然后重新开启 VS Code 或者 cli ,这样就不会触发压缩了,可以继续聊下去。
作者: apibox | 发布时间: 2026-03-14 08:28
22. Claude 上线了 1m context,为什么我这用不了啊?
https://code.claude.com/docs/en/model-config#extended-context-with-1m
已经升级最新版 v2.1.76 ,用的时候还提示: Opus 4.6 with 1M context is not available for your account. Learn more:https://code.claude.com/docs/en/model-config#extended-context-with-1m
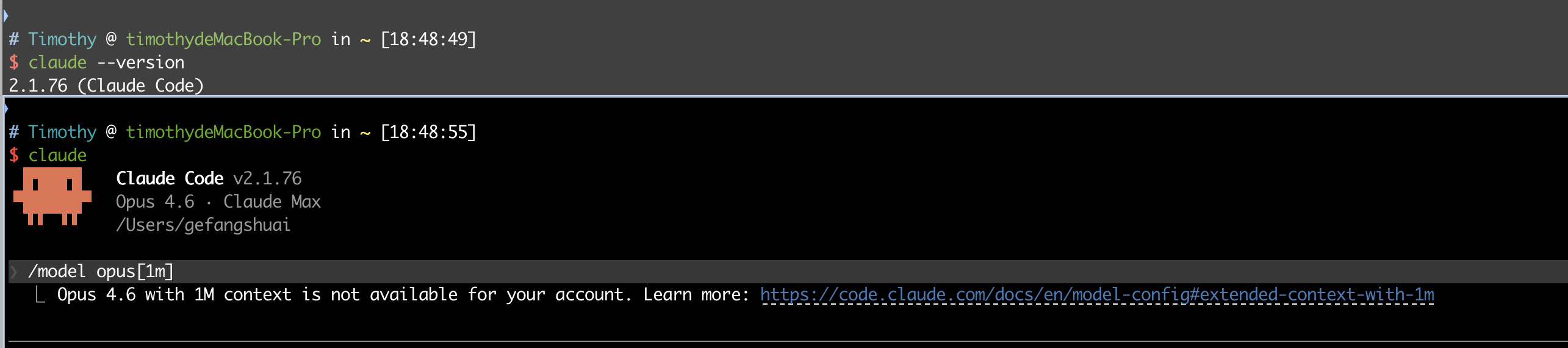
作者: gefangshuai | 发布时间: 2026-03-14 10:52
23. 手搓了最喜欢的 Android 软件, GestureExplode
Android 最喜欢的软件,Google 的 gesturesearch ,效率 No.1 ,2015 年停更后一直没有合适的替代。
而且基于 32 位,后续 64 位 cpu 无法兼容。
基于 AI 自己手搓了一个,可以通过手势输入字母来搜索手机联系人,应用,设置,无需联网权限。
欢迎大家食用:github.com/colorbeta/GestureExplode
作者: colorbeta | 发布时间: 2026-03-14 14:13
24. 告别人肉复制粘贴:我的 Claude + Codex 自动化协作工作流
背景介绍
我日常喜欢用 Claude 来做项目的架构师,而 codex 做代码执行者,不管是 claude 还是 codex ,我对他们的生成的结果都保持怀疑态度的,但我又不可能去看一行行代码看,所以我日常使用的一个最常用方式,就是让他们互相进行 review 。
在这个过程中,我往往充当一个“无情”的复制粘贴者。比如 Claude 做完架构或方案设计后,我就让 Codex 去 review ,再把 Codex 的 review 结果复制粘贴回 Claude 的终端;或者 Codex 写完代码,我就让 Claude 去 review ,再把 review 意见贴回给 Codex 。我成了他们之间沟通的桥梁,这种方式非常低效。
方案介绍
为了解决这个问题,我开发了两个开源的 Skill ,让它们可以自动沟通和 review:
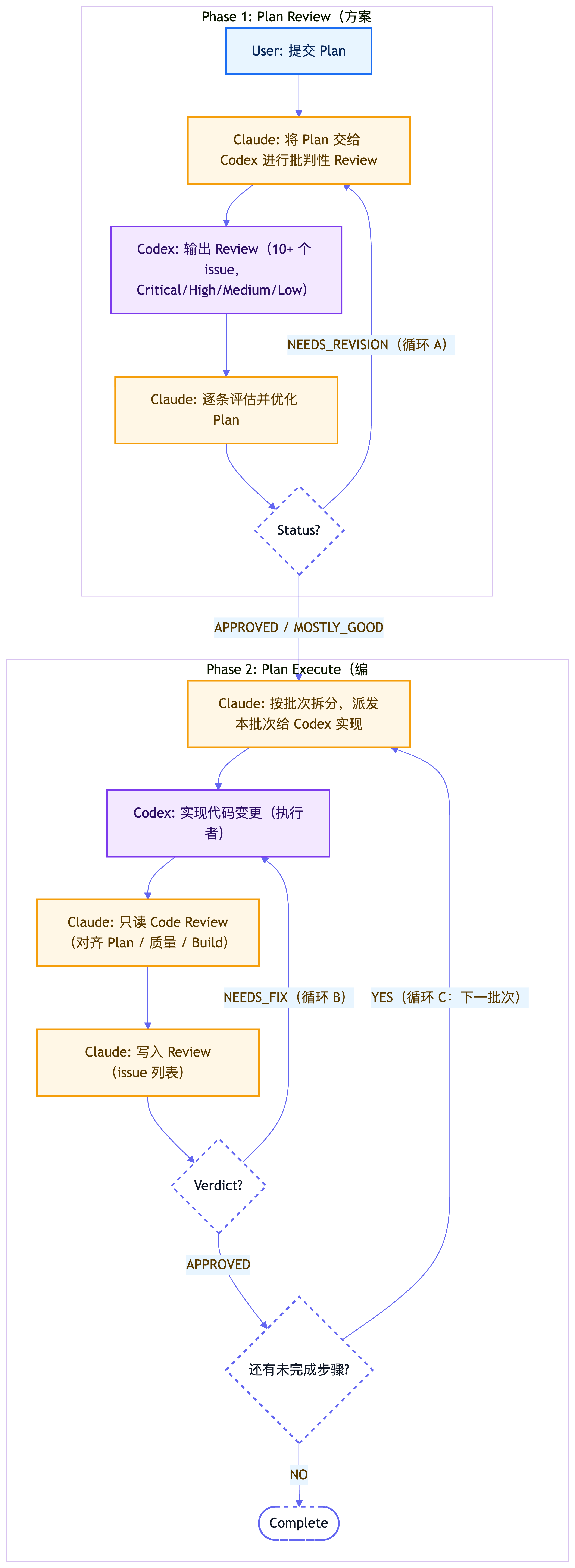
- 1. Codex Skill (底层基础) 首先需要一个把 Codex 封装成”即插即用”接口的基础 Skill 。我参考的是oil-oil/codex,把 Codex 做成一个随时可调用的 Sub-Agent 。不管是 Plan Review 还是 Plan Execute ,Claude 想让它干活就直接调这个接口。整个协作体系都是搭在这个基础之上的。
- Plan Review Skill (方案评审层) 这个项目整体由 Claude 驱动,因为我觉得 Claude 在工具调用( Tool Use )上的表现更好。
- 流程: 我先跟 Claude 沟通出一版方案,我觉得差不多了,但不确定是否有遗漏或优化空间,此时我会调用
Plan Review。- 机制: Claude 会调用封装好的 Codex Skill ,让 Codex 进行 review 。
- 迭代: review 完后,Claude 会自动读取 Codex 反馈的结果并进行修改。这个过程会反复迭代,直到两者达成一致。这完全省去了我日常手动复制粘贴的麻烦。
- Plan Execute Skill (方案执行层) 方案 review 完后进入执行阶段,我会使用这个负责“计划执行”的 Skill 。
- 角色分工: Claude 依然作为“架构师”或“代码审计员”,它不会亲自动手写代码,而是将任务交给 Codex 。
- 执行: 它通过调用 Codex Skill ,让 Codex 去完成具体的代码编写。
- 闭环: Codex 完成后,Claude 会去 review 它的代码。如果发现问题,就让 Codex 继续改,直到两者达成统一。
通过这种“左右互博”的博弈机制,最终产出的结果基本上不会有大问题。这样可以更高效地解放双手,不需要时刻盯着,就能达到满意的结果。
阶段 Skill Claude 角色 Codex 角色 方案打磨 /plan-review编排 + 改方案 批判性审稿人 代码实施 /plan-execute编排 + review 代码 写代码 + 修复 补充说明
claude 进入
plan模式之后默认存储的位置是在~/.claude下的,可以在~/.claude/settings.json进行配置plan存放的目录,如下所示,便会存放到当前项目中了{ "env": { }, ... "plansDirectory": "./plans", }工作流
安装
方式一:npx add-skill (推荐)
前置条件: 先安装 add-skill CLI:
npm install -g add-skill然后安装 skills:
npx add-skill longranger2/claude-gpt-workflow方式二:单独安装
单独安装各个 skill:
npx add-skill longranger2/claude-gpt-workflow/plan-review npx add-skill longranger2/claude-gpt-workflow/plan-execute npx add-skill longranger2/claude-gpt-workflow/codex方式三:手动安装
复制 skills 到你的 Claude Code skills 目录:
cp -r plan-review/ ~/.claude/skills/ cp -r plan-execute/ ~/.claude/skills/ cp -r codex/ ~/.claude/skills/参考链接
作者: loneranger1024 | 发布时间: 2026-03-14 06:10
25. 大家公司怎么使用 ai 的?
- 在哪些场景,怎么使用的?
- 不仅仅是编程,据了解编程领域是 ai 提效最高的。
作者: siaronwang | 发布时间: 2026-03-14 02:28
26. 自从用了 Claude Code, Intellij 家族的 ide 很少打开了
自从用了 Claude Code ,Intellij 家族的 ide 很少打开了
你们用什么工具配合 ai 工具呀?
作者: gefangshuai | 发布时间: 2026-03-13 09:48
27. 话说阿里云备案一定要买服务器?
之前的阿里云的域名,有阿里云服务器,网站跑了两年左右,服务器到期后,就把网站迁移到阿里云 oss 了,而且这个网站一直都是正常运行,包括后面做了备案的信息更新。
今天重新买了一个域名,点进去发现必须购买服务器才能备案,有什么办法可以绕过呢?
有一台火山云的服务器,若去火山云备案,岂不是得把域名转过去?
后面这个域名要在阿里云的 oss 使用,不是又得转回来?真是折磨人,😑。
作者: cccn | 发布时间: 2026-03-14 10:40
28. 想直接购买 CC 的 api key,不想通过中转,没有大美丽信用卡做不到?
如何合法途径通过国内支付,有经验的进来聊聊啊
作者: mrsbryant | 发布时间: 2026-03-12 00:55
29. 广大 V 友注意, IDEA 插件 claude-code-gui 插件会盗刷 token,我已中招,已经举报下架
事情是这样的,我之前买了中转,想在 IDEA 上使用,填入中转 key 后,我有一段时间没用,再次上线时,发现被盗刷了 700 多的额度,现在该已经被举报下架了,我在他的 GitHub 留言了,大家以后注意这种情况,真的恶心。 Imgur Imgur Imgur Imgur
作者: ZettarYuFan | 发布时间: 2026-03-13 11:09
30. Google one AI Pro 使用额度限制,这个量感觉不够
代理模式和 Gemini CLI 的配额
Gemini Code Assist 代理模式和 Gemini CLI 的请求配额会合并计算
每个用户每分钟的请求数 120 每个用户每天的请求数 1500 https://developers.google.com/gemini-code-assist/resources/quotas?hl=zh-cn
作者: Hyvi | 发布时间: 2026-03-14 03:43
31. 请问在阿里云中怎样管理少量的密码、API KEY 之类的凭据?
以前使用 AWS 的时候用 Secrets Manager 管理、使用少量凭据,
现在需要使用阿里云做国内项目(后续建议公司评估 AWS 中国服务)。
阿里云客服告知凭据的最低购买量是 1000 个,
实际项目中一个环境也不超过 10 个凭据,
请问阿里云有什么性价比更高的凭据管理方式吗?
作者: sungnix | 发布时间: 2026-03-14 03:38
32. vscode 无法安装插件
[error] [窗口] End of central directory record signature not found. Either not a zip file, or file is truncated.: Error: End of central directory record signature not found. Either not a zip file, or file is truncated.
不仅插件没法安装,也没法更新
使用 vsix 手动安装的方法也是报错 Extract: End of central directory record signature not found. Either not a zip file, or fileis truncated.
怎么回事?
作者: lanshiL3C | 发布时间: 2026-03-14 11:04
33. 某团队公开了一个支付宝的攻击面
刷抖音的时候看到了一个网站: https://innora.ai/zfb/ , 标题是“支付宝 DeepLink 攻击面分析”
作者: defaultVoid | 发布时间: 2026-03-13 15:24
34. 做了个给 AI Agent 用的排障框架:重点不是接更多工具,而是把排障流程收敛
因为前一阵子被自己参与的 DAG (有向无环图)系统排错折磨得苦不堪言,才有了这个项目。
当时系统涉及几十个节点,排错时需要从 Langfuse 里几十 KB 甚至非常重的 Trace 树中用肉眼找关键节点,经常看花了眼。但在痛苦的过程中,我也意识到:这种排错其实极度有“套路”。
尤其是前阵子各种 Agent Skill 爆火,当时我就想,为什么不直接给 AI 接上 DB 、Redis 和 Langfuse 的只读接口,然后写一个特定的 Skill (也就是 Runbook 手册)告诉它:
“遇到这样的问题你按这个顺序查,第一步查 Redis ,第二步对比 DB ,第三步去对应的几十 KB 的 Trace 里精准捞出特定的那些关键数据进行分析。”实际跑通测试下来,效果出奇地好:AI 不再瞎猜,给出的结论极其稳定可信。所以,干脆就把这套方法论抽象了出来,做成了这个独立的框架:
agent-debugger/debug-runbook。GitHub 项目地址:
https://github.com/UnCooe/debug-runbook为什么做这个东西?
它想解决的问题其实挺具体的。
现在很多 AI Agent 的“线上排障”方案,本质上还是把数据库只读账号、日志系统、Tracing 、Redis 这些工具接口一股脑暴露给模型,然后期待它自己查明白。
看起来很智能,但实际越做越觉得,这里面有个经常被忽略的关键变量:
排障能力里最值钱的部分,绝不是工具访问权限,而是调查顺序与证据链条。
一个有经验的后端同学排查问题,脑子里通常不是“有什么工具”,而是:
1. 先确认请求到底有没有真的进入主流程
2. 再看关键副作用( Side Effect )有没有发生
3. 再对齐持久化状态 (DB)
4. 最后才看 缓存 / 幂等键 / 异步链路 有没有把流程短路这个顺序本身,就是千锤百炼的排错经验。
而很多 Agent 方案,偏偏把这部分丢了,只剩下“模型自由发挥”。结果就会出现几个典型的高血压名场面:
- 工具很多,但调查路径不稳定,每次问法不同,排查步骤也不同;
- 模型极容易被大段的 Trace / SQL 结果 / 日志噪音带偏( Token 直接爆炸💥);
- 它能给出一个“像样的解释”,但证据链根本经不起推敲;
- 真到线上大推业务场景时,你完全不敢 audit 它到底凭什么得出的这个结论。这个项目做了什么?
所以做这个项目时,换了个解法。思路不是“看怎么再封装几个强大的 MCP 调试工具”,而是反向操作:
把资深工程师的排障套路写成可执行的 YAML Runbook ,强制约束 Agent 先按顺序收集证据,再下结论。
项目的架构骨架大概是这样运作的:
- 输入一个事故上下文(比如trace_id、order_id、request_id)
- 选剧本:引擎先根据症状( Symptom )匹配最对口的 Runbook 。
- 强制按序执行:再严格按 Runbook 规定的步骤,顺序调用 Trace / DB / Redis 这些 Adapter 。
- 洗数据:所有 Adapter 返回的原始结果,全部过滤洗干净,归一化成了结构化的Evidence(证据)。
- 推断结论:再把这些证据扔进决策引擎( Decision Rules ),产出最终包含根因的结构化 Incident Report 。不是让模型像无头苍蝇一样直接面对一地鸡毛的真实状态图,而是先把“可调查路径”和“证据形状”全都死死限定住。
核心特性 MVP 验证
现在做出来的早期开源版( MVP )跑通了几个硬核节点:
1. Runbook Selection:根据 symptom 和 context 选排查剧本,不是所有问题都一把梭地查全套系统。
2. Ordered Execution:排查步骤强制有序,不允许 Agent 自己胡乱跳转发散。
3. Evidence Normalization:不直接把原始 Payload 喂给大模型,而是转成几十个字的统一 Evidence ,保护上下文长度。
4. Decision Rules:最终出什么结论不靠 LLM 的玄学推理,而是基于收集到的“证据组合”来触发(比如A 证据 + B 证据 = C 结论成立)。
5. 绝对的只读红线:所有 Adapter 都限制在了只读层。DB 有表名白名单拦截,Redis 限制了 Key 前缀匹配规则,从根本上杜绝大模型在库里“乱挥大刀”。真实的 Demo 案例
在库里塞了一个最常见的业务 Case Demo:“订单创建成功了,但下游任务没生成”(
npm run demo:order-task-missing)。
- 原生 Agent 的瞎排查:把几百行的 Trace 读一遍发现没报错,又去扫全表 SQL 搜日志,毫无头绪。
- 在这个 Runbook 框架里:它老老实实地走了一条固定路径。先扫 Trace ,再看丢失的那一环丢在哪里了,转头查 DB 的订单和任务表比对,最后精准定位到 Redis 里的 Idempotency Key 。通过收集齐这几样证据,得出了极其稳定的结论:
“请求大概率被 cache / idempotency 状态提前拦截短路了,所以订单尽管落库了,但后续副作用未触发”。这套逻辑基准的 Benchmark 是全绿通过的。
欢迎来交流与碰撞
这套东西刻意没有往“全自动自发修复线上 Bug”那种吸睛(但现阶段不现实)的方向去靠,因为觉得在复杂的业务黑洞里,可审计性与证据链是否收闭,远比所谓的“AI 显得很聪明”能落地得多。现在项目已经备齐了 MCP 入口,搭好了引擎的基础结构。
V 站的各位老哥/老姐们如果有在这条 AIOps 泥石流里摸爬滚打过的,很想借机探讨几个灵魂拷问:
1. 你们团队线上最频繁、最适合被总结成“八股文排错 Runbook”的事故场景是哪一类?
2. 在平时的排障中( Trace / DB / MQ / 日志分析等),你们觉得大模型在哪一层最容易犯浑、被噪声带跑偏?
3. 对于生产环境,你是更愿意相信一个“工具自由调用的万能 Agent”,还是“被规范排障手册强约束的 Agent”?
4. 如果要把你们老专家脑子里的“祖传排故套路”沉淀成 YAML 代码交接给 AI ,最大的阻力通常是什么?如果觉得这里的实现思想有那么点意思,极其欢迎路过指点,或者试着提 PR 用你们最得意的“排障剧本”砸向。相比多添个连接器,这项目现在最缺的反而是真实战场的经验剧本,因为从这个架构看,Adapter 只是干活的苦力,高度浓缩的 Runbook 才是真正的资产层。
作者: bimeixishuai | 发布时间: 2026-03-14 09:07
35. 为什么放弃了 RAG? RAG 的六大难题
RAG 本身并不算是个坏主意。我们认真实践过,也确实在某些场景下跑通了。
去年,我们花了几个月搭过几套完整的 RAG 管线:三阶段处理( Extract 、Chunk 、Embed ),三种搜索策略( Vector 、BM25 、Hybrid + Reranking )。从文本提取,粗排,到 Rerank 精排,每一个环节都认真做了一遍。工程量不小,技术上看着很漂亮。
但最终不得不承认一个事实:效果不好
这篇文章不是要批判 RAG ,而是诚实地分享下我们具体遇到了哪些问题,以及我们后来怎么想的。以及,小广告。。。
问题一:Embedding 模型两难
做本地桌面应用,Embedding 模型的选择是一个没有好答案的问题。
小模型(参数量 < 500M )在设备上跑得动,但语义理解质量不稳定——碰到专业文档、跨语言搜索、长文档时,召回率明显下降。大模型( 1B+)质量好,但在普通用户的笔记本上内存和计算开销太大,后台常驻时对系统资源的占用让人无法接受。
桌面应用没有服务器可以依赖,只能在”跑得动”和”效果好”之间妥协。选了一个,另一个就要让步。这个困境在服务端应用里不存在,在本地优先应用里却是无解的。
问题二:领域词汇不敏感
向量语义搜索有一个根本性的弱点:它对专业术语的理解很差。
原因并不复杂。Embedding 模型是在通用语料上训练的,而代码函数名、医学缩写、法律条款、产品专名这些词在训练语料里出现频率低,在向量空间里的位置偏僻且不稳定。
实际表现是什么样的?用户搜 “RLHF”,不一定能找到写着 “Reinforcement Learning from Human Feedback” 的文档。搜”LTV”,可能匹配不到写着”用户生命周期价值”的分析报告。搜某个产品的型号,向量搜索根本抓不住这个词的准确语义。
这不是配置问题,不是参数调优能解决的,业内常见做法是做 embedding 模型的微调,但一般都是针对特定领域,只能在 ToB 场景中 work 。
Embedding 优势是模糊语义匹配,它的劣势恰好就是精确词汇匹配。而用户的真实需求往往是两者都要。
问题三:Rerank 的代价
召回率低和准确性差,是 RAG 管线的两个经典问题。针对准确性问题,业界的标准解法是引入 Rerank 模型做最后一步的精排。
我们也做了这一步,然后发现问题并没有被解决,只是被转移了。
Rerank 模型比 Embedding 模型更重、更慢。引入它之后,整个检索链路的延迟大幅上升,对本地应用来说尤其明显。更关键的是,Rerank 模型同样是在通用语料上训练的,同样存在专业词汇不敏感的问题——它只是在你已经召回的候选里重新排序,而不能召回那些一开始就没被捞到的文档。
最终结果:链路变慢了,架构变复杂了,根本问题还在。引入 Rerank 后,排序质量的提升非常有限,反而让 BM25 的作用几乎被掩盖了。
问题四:碎片化的上下文
分块( Chunking )是 RAG 最无法绕开的问题。
文档被切成固定大小的片段之后,每个片段都与它的前后文脱节了。AI 拿到的是一段从报告中间截取的内容,不知道这段话在哪个章节,不知道前一段在讲什么,也不知道后续有没有结论。
最糟糕的情况是:一个关键段落恰好横跨两个 Chunk 的边界,两个 Chunk 都能匹配到,但又各自不完整。AI 拿到的两份碎片都沾了边,却都缺少关键信息,最终给出一个似是而非的回答。
这个问题业内有很多补丁办法,比如:加大 Chunk 重叠,加入父 Chunk 检索,引入 Small-to-Big 策略……每个补丁都能在某个维度上改善问题,但也都会带来新的代价——更多 Token 、更复杂的管线、更难调试的行为、更加无法通用。
我们把这些补丁叠在一起,得到了一个复杂、易出错,但仍然不够好的系统。
问题五:不同文档类型需要特殊处理
通用分块策略对不同文档类型的效果差异极大,这是我们当初没有充分预判到的。
论文有 Abstract + 正文 + References 的结构;书籍有章节层级和页眉页脚;合同有条款编号和交叉引用;代码文档有 API 列表和示例代码;表格类文档的”内容”是列名和数据类型,而不是单元格里的文字……
固定窗口切块的策略不理解这些结构,分块点往往切在语义中间,把标题和它的正文分开,把条款编号和条款内容切断,把表头和数据分离。
每种文档类型其实需要完全不同的处理逻辑。但针对每种类型都写特化的解析器和分块策略,工作量巨大,维护成本也高——而且即使都做完了,效果也只是”比通用策略好一些”,仍然是碎片化的。
问题六:Agent 使用体验极差
以上五个问题单独看,每个都还在可接受的范围内,但当 RAG 被实际接入 AI Agent 使用的时候,所有问题叠加在一起,效果非常糟糕。
一个真实的场景:AI 在帮用户分析一份合同,调用
search()检索相关条款,拿到了 10 个 Chunk 。有几个 Chunk 沾了边,但信息不完整。AI 无法判断该怎么继续,只好调整关键词重新搜索。再拿到 10 个 Chunk ,还是不够。再换关键词,再搜一次。每次搜索都是黑盒:AI 不知道换哪个关键词才能找到它需要的内容,不知道文档里到底有没有这个信息,不知道自己距离答案有多远。这种低效不是 Agent 能力不够,而是工具本身的设计不支持它做出合理的决策。
RAG 在设计上是为”用户直接提问”场景优化的,不是为”Agent 自主探索”场景设计的。
行业也在转移
这些问题不是我们独有的,业内已经有明显的应对趋势:
微软的 GraphRAG 引入知识图谱来缓解上下文碎片化问题,把相关实体和关系显式地存储下来,而不是靠碎片拼凑。
PageIndex 不按固定大小切 Chunk ,而是以页面为单位建立索引,保留文档的自然边界。
Agentic RAG 尝试让 AI 自主决定检索策略,而不是走固定管线——方向是对的,但在 RAG 架构上叠加 Agent 逻辑,复杂度随之翻倍。
最彻底的转向来自 Claude Code 和 Manus 。它们干脆放弃了 RAG ,回到最原始的方式:Glob + Grep + Read 。找文件、搜关键词、读内容。没有向量数据库,没有 Embedding 模型,没有 Chunk 管线。效果反而更好。
这让我们想明白了一件事:RAG 的设计假设是”LLM 不够聪明,需要我们帮它把信息预处理好”。这在 GPT-3.5 时代是合理的。但现在的 LLM 已经有能力自主使用工具完成多步检索任务——它们不需要预切碎片,它们需要的是线索 :文件在哪,结构是什么,然后它自己能决定读什么、读多少。
我们的解法:Outline Index
Glob + Grep + Read 对代码库很有效,但对用户文档行不通。代码库里
src/services/auth.ts这个路径本身就在告诉你这是认证服务;但2024 年度总结(修改版)(最终版).docx,路径告诉你的信息约等于零。更别提 PDF 和 Word 是二进制格式,grep 根本读不了。所以我们的问题变成了:能不能给文档也建立一套等价的”目录索引”,让 AI 用 search → outline → read 的方式渐进式地翻阅你的文件?
我们把这套方案叫做 Outline Index 。
核心思想一句话:不替 AI 预切信息,而是给它一张地图。
为每个文档建立一份结构化”名片”,包含文档的元数据(标题、作者、关键词、摘要)和结构大纲(章节标题、层级关系、行号范围)。AI 按三层路径访问文档:
- search :搜索相关文档,返回文件列表和 Metadata ,约 50 tokens/文件
- outline :查看文档的结构地图,约 200-500 tokens/文件
- read :精准读取指定章节的原文,按需加载
这与人类阅读的方式完全一致:先找书,看目录,翻到对应章节精读。AI 在这个过程中有完整的上下文,知道自己在文档的什么位置,可以决定”再多看一点”,也可以跨文档对比。
对比传统 RAG:同样的场景下,Outline Index 方式的 Token 消耗约 800-3400 ,AI 拿到有完整上下文的精确信息。传统 RAG 返回 10 个预切碎片,消耗 4000-6000 tokens ,AI 对文档结构一无所知。
另一个副产品:Embedding 的对象从原文 Chunk 变成了 Outline Index 本身。一个文档只需要一个向量。10000 个文档 ≈ 10000 个向量 ≈ 30MB 存储,检索速度也快得多。
关于领域词汇不敏感的问题,BM25 全文检索补上了这块短板。双路检索( BM25 精确匹配 + 向量语义理解),通过 RRF 融合,不再需要 Rerank 模型。
最后,是广告时间:
- Outline Index 是 Linkly AI 的核心技术。如果你对具体的实现细节感兴趣,可以阅读这篇技术文章:Outlines Index:一种渐进式披露大量文档给 AI Agent 的方法。
- 如果你想体验实际效果,请下载 Linkly AI,以及 linkly-ai-cli,接入到某个 AI 客户端中体验,实测效果远好于 RAG 。
作者: blueeon | 发布时间: 2026-03-13 06:17
36. Anthropic 家的模型训练与其他家差别大吗?
大家都知道 Anthropic 家的模型,尤其是 Opus 的实力,在编码的实际体验中是最强的,没有之一。即使拿 gemini3.1pro 和 gpt5.3codex 比,这俩也是比不上它一点。
除了编码,大家跑龙虾也能感觉出来差别很大,尤其是多步骤工具链的复杂任务只有 opus 能完美胜任,opus 画的 svg 动效流程图也是比新的 gemini 强很多。
我的问题是,公开互联网训练数据大家都是一样的,各家的 RL 也差不离(这点应该没什么技术壁垒),经济实力上 OpenAI/Google 应该更有优势,那为什么训练出来的大模型只有 opus 家最强?
是 Anthropic 家训练更强调代码能力,侧重点不同导致的吗?
作者: Kinnikuman | 发布时间: 2026-03-13 03:27
37. 安卓假如放弃 root 的话,建议买哪家?
首先说一下,不买苹果。苹果没法用 mihon 、iceraven 、ublock origin 等软件,而且就算有上架的 app 相比安卓版本也会屏蔽 r18 ,比如 TG 。此外我没有 mac 也会导致很多麻烦。
安卓现在 root 是真的太难太难了,一解锁就导致特别特别多问题。我目前解锁 root 的需求其实主要就两个:
- 国产特色系统的大量广告、各种云控、安全中心、“贴心”的拦截 apk 安装、杀后台( VPN 容易挂)。这个解决办法其实除了 root ,还可以选择本身就更纯净的系统。
- 备份 app 数据(/data/data )。这个是最难以完全替代的需求,安卓这边好像国产是没有对标苹果的 e2ee 备份的吧,我对那些云很不放心。那另一个选择就是放弃手机数据,尽可能不往手机上放重要数据,都往 NAS 之类的地方塞。
注 :没有关国产流氓的需求,国产直接物理隔离。
我网上搜了下资料,好像满足 1 的国行手机,就只能在三星(可以不解锁刷港版)、摩托罗拉、努比亚/红魔里选了?有没有用过的朋友说下体验呢?三星和摩托罗拉国内的评测非常少,而且大部分面向大众的评测,基本都没有提到云控、安全中心、杀后台、GMS 完整性之类的东西,国内可能很多普通用户根本不在意广告快应用啥的。比如这个帖子 https://v2ex.com/t/1196721 ,V 友 tyzrj766 的回复:
你朋友没用酷安,酷安信息流里的广告,在 ColorOS 上调用快应用,能实现不碰不晃,刷到就一键打开,如果是小游戏直接读取你的 OPPO 账号给你实名过验证,瞬间完成。我用 X9 那会都惊了,以前用小米和 vivo ,系统里的快应用广告都没这么丧心病狂。
加上这个 B 系统,字体不统一,界面不统一,屏幕也差,月月更新只会水 AI ,目前是被我拉黑了,一加和 OPPO 手机再好,系统再德芙,这些问题不改我是不会用了。前后买了三四个黑厂手机,没一个能坚持用的下去。
这个对我是绝对无法接受的,但是 B 站大众向评测里都觉得 ColorOS 很好用,所以只能来 V2EX 这种更偏极客的论坛来请教一下了,国行安卓里哪个系统对于极客来说体验更好?三星刷港版、摩托罗拉、努比亚/红魔的体验怎么样?
作者: LaTero | 发布时间: 2026-03-13 08:36
38. 用人翻阅资料的行为模式来设计知识库怎么样?
我们人是怎么查资料的,假如去图书馆 1.找到对应的书架 2.找到对应的书 3.翻阅目录,定位到页码 4.读取内容
以上模式其实很简单,把最上一级的目录通过 System Prompt 传给 ai ,然后写几个 function call 就行了,ai 自己调方法去查。
请问一下这种方式有什么缺点吗?
作者: huanggan | 发布时间: 2026-03-14 04:36
39. 买 google AI pro 是花钱受气。
白嫖的时候,google AI studio 对话 100 万 token,天天用着挺爽。Antigravity 刚出来,用了一下,很惊艳。 后来感觉一般,看它有了 opus 很强,就先充三个月的 AI pro 试试,偶尔用用。2 月份一个 token 都没用。3 月,一次对话就限制一周。也懒得用了,他妈妈的。还是用我的 copilot pro 了。现在 gemini 3 pro 对话像个二逼青年。100 万的额度用了 5 万就限额,傻逼玩意。




作者: handsome198311 | 发布时间: 2026-03-14 06:12
40. 大厂离职 gap 半年面试备受打击求外企推荐
背景:某头部大厂(B)后端开发 5 年+,B 端业务,裸辞 gap 半年,年后陆续开始面试,互联网大中厂面了个遍( 5 家),都是一面二面挂,甚至连续多次投递过不了简历关,非常焦虑。
问题:
- 想获得面试机会非常需要垂直业务经历匹配,很多岗位直接简历筛选不过。
- 基本每场面试都会具体质疑我的裸辞原因,并对我给出的理由(休息了一段时间、部门业务前景不好想换业务获得成长、gap 过程中也在学习 AI 等)均不认可(例如:怎样才能叫获得成长?为什么一定要裸辞呢? gap 这么久都干啥了?)。仿佛 gap 就该判刑。
- 复盘了下面试挂的原因,项目经历确实没有太大的亮点。
如果后续大厂的机会都没把握住,心理可能会很失衡,但是心里预期只能这样慢慢降低。 现在也想找些上海深圳的外企(能给得起薪资(快到 P6 的顶),平薪也行)投递,大家有推荐吗?谢谢。
作者: vamostu | 发布时间: 2026-03-13 14:22
41. 满勤码神
周六牛马监督 ai 干活的新成就达成

作者: crocoBaby | 发布时间: 2026-03-14 03:39
42. 之前领取阿里云台历和帆布袋的记得检查账单
[阿里云] 尊敬的用户:您的账号 x*k 已产生欠费。您的延停额度为 10.00 元,目前已使用 0.01 元。延停额度用尽后,按量付费产品出账后均会立即进入停服处理流程。请您尽快充值结清欠费账单,以免欠费停服给您带来不必要的损失。您可以通过电脑端登录用户中心,查看明细账单。 记得去云安全中心检查有没有按量付费
作者: xiongbenwu | 发布时间: 2026-03-14 03:54
43. antigravity 5h 刷新改回来了
刚刚刷新了一下 antigravity 发现改成 5 小时刷新了,看来谷歌被骂还是听劝的
作者: LaughingCat | 发布时间: 2026-03-13 09:52
44. 有新闻抓取的 skills 吗?
在 clawhub 上找了几个(find-skills 以及手动找),都不太符合需求,我的需求是:
1. 抓国内新闻热点
2. 抓到的内容可以缓存,下次抓到重复内容不处理
3. 内容是:标题/链接/总结/日期等不需要支持很多平台,因为热点新闻会在大部分平台出现。
自己部署 rsshub + 让🦞自己实现比较麻烦,因为总要调试,会浪费很多 tokens 。
所以做一回伸手党,有没有已经实现好的新闻 skills ?
作者: ethusdt | 发布时间: 2026-03-13 14:27
45. Antigravity 有 GeminiPro 的账号也变成 5 天冷却了?
之前 opus4.6 一直都是 5 小时的冷却时间啊,今天打开看突然变成 5D+了
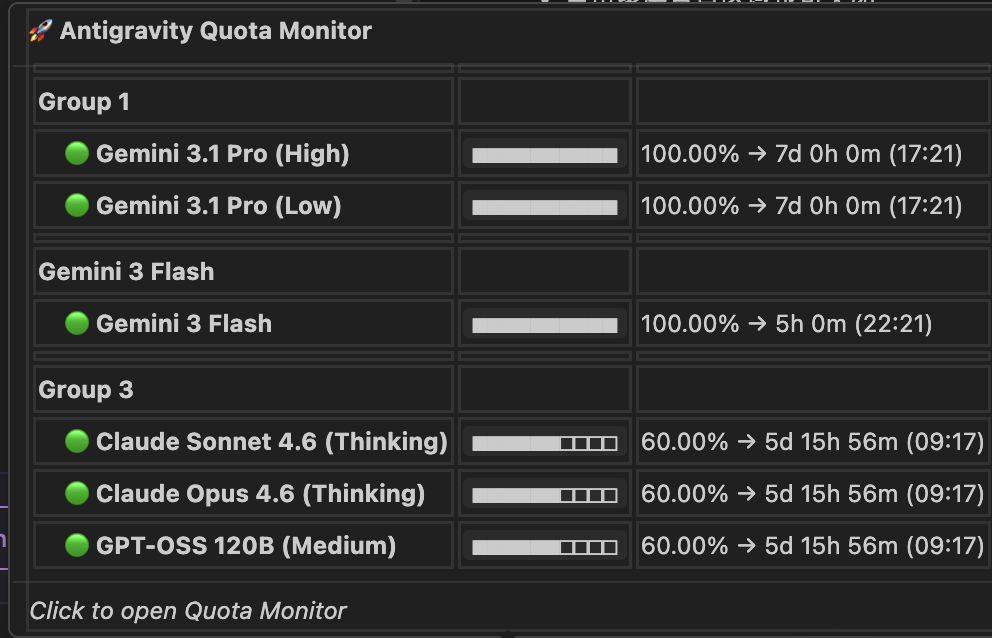
作者: lp4298707 | 发布时间: 2026-03-12 09:27
46. Linux 服务器上有多个 ip,程序本身不能指定接口,有第三方程序可以强制让程序使用指定接口吗?
像 libbind 、proxychains 、部分 tsocks 这类基于 LD_PRELOAD 劫持 libc 的办法,不适合 golang 编写的程序
有比较便捷的解决方案吗?
作者: pc10201 | 发布时间: 2026-03-13 02:30
47. 关于知识库搭建
大家好,想请教一下大家都是怎么搭建个人知识库的。我这边有不少本地文件(主要是论文)。虽然现在像 Perplexity 这样的 AI 工具有很强的搜索能力,但我还是希望能搭建一个既能自定义联网资源,又能利用本地数据的知识库。目前在用 Notion ,不过每次都要手动粘贴内容挺麻烦的。像 NotebookLM 这种工具对上传文件数量有限制,所以暂时不考虑。我刚买了一台 512G 的 mini ,更倾向于搭建本地知识库。
作者: elliszkn | 发布时间: 2026-03-13 04:30
48. 增强的语音识别下载失败求助
增强的语音识别简中一直下载失败,日语就很快下载了,试了 gemini 给的各种办法也不行。求助!
作者: dangotown | 发布时间: 2026-03-14 00:06
49. 请问 V 友们工作上一些项目中敏感信息存哪
比如项目的服务器连接信息,vpn 连接信息
我可能按项目建 md 这种没加密文档,我也看到同事很多放 txt 中
感觉不太安全,一般放密码管理器中吗
作者: zonas | 发布时间: 2026-03-13 13:18
50. 有没有觉得,其实国内的程序员们最近几年,付费习惯培养起来了
刚入行的时候,我就从来没有遇到过身边的程序员 会付费购买效率工具的,所以我一直认为不要面向程序员做付费软件,但是这个观点,最近几年我彻底改变了。发现越来越多的国内程序员,愿意为有价值的,能提高效率的工具买单,所以,专注把产品做好就行。
作者: mcfever | 发布时间: 2026-03-13 00:29