V2EX 热门帖子
1. 广大 V 友注意, IDEA 插件 claude-code-gui 插件会盗刷 token,我已中招,已经举报下架
事情是这样的,我之前买了中转,想在 IDEA 上使用,填入中转 key 后,我有一段时间没用,再次上线时,发现被盗刷了 700 多的额度,现在该已经被举报下架了,我在他的 GitHub 留言了,大家以后注意这种情况,真的恶心。 Imgur Imgur Imgur Imgur
作者: ZettarYuFan | 发布时间: 2026-03-13 11:09
2. 某团队公开了一个支付宝的攻击面
刷抖音的时候看到了一个网站: https://innora.ai/zfb/ , 标题是“支付宝 DeepLink 攻击面分析”
作者: defaultVoid | 发布时间: 2026-03-13 15:24
3. 为什么放弃了 RAG? RAG 的六大难题
RAG 本身并不算是个坏主意。我们认真实践过,也确实在某些场景下跑通了。
去年,我们花了几个月搭过几套完整的 RAG 管线:三阶段处理( Extract 、Chunk 、Embed ),三种搜索策略( Vector 、BM25 、Hybrid + Reranking )。从文本提取,粗排,到 Rerank 精排,每一个环节都认真做了一遍。工程量不小,技术上看着很漂亮。
但最终不得不承认一个事实:效果不好
这篇文章不是要批判 RAG ,而是诚实地分享下我们具体遇到了哪些问题,以及我们后来怎么想的。以及,小广告。。。
问题一:Embedding 模型两难
做本地桌面应用,Embedding 模型的选择是一个没有好答案的问题。
小模型(参数量 < 500M )在设备上跑得动,但语义理解质量不稳定——碰到专业文档、跨语言搜索、长文档时,召回率明显下降。大模型( 1B+)质量好,但在普通用户的笔记本上内存和计算开销太大,后台常驻时对系统资源的占用让人无法接受。
桌面应用没有服务器可以依赖,只能在”跑得动”和”效果好”之间妥协。选了一个,另一个就要让步。这个困境在服务端应用里不存在,在本地优先应用里却是无解的。
问题二:领域词汇不敏感
向量语义搜索有一个根本性的弱点:它对专业术语的理解很差。
原因并不复杂。Embedding 模型是在通用语料上训练的,而代码函数名、医学缩写、法律条款、产品专名这些词在训练语料里出现频率低,在向量空间里的位置偏僻且不稳定。
实际表现是什么样的?用户搜 “RLHF”,不一定能找到写着 “Reinforcement Learning from Human Feedback” 的文档。搜”LTV”,可能匹配不到写着”用户生命周期价值”的分析报告。搜某个产品的型号,向量搜索根本抓不住这个词的准确语义。
这不是配置问题,不是参数调优能解决的,业内常见做法是做 embedding 模型的微调,但一般都是针对特定领域,只能在 ToB 场景中 work 。
Embedding 优势是模糊语义匹配,它的劣势恰好就是精确词汇匹配。而用户的真实需求往往是两者都要。
问题三:Rerank 的代价
召回率低和准确性差,是 RAG 管线的两个经典问题。针对准确性问题,业界的标准解法是引入 Rerank 模型做最后一步的精排。
我们也做了这一步,然后发现问题并没有被解决,只是被转移了。
Rerank 模型比 Embedding 模型更重、更慢。引入它之后,整个检索链路的延迟大幅上升,对本地应用来说尤其明显。更关键的是,Rerank 模型同样是在通用语料上训练的,同样存在专业词汇不敏感的问题——它只是在你已经召回的候选里重新排序,而不能召回那些一开始就没被捞到的文档。
最终结果:链路变慢了,架构变复杂了,根本问题还在。引入 Rerank 后,排序质量的提升非常有限,反而让 BM25 的作用几乎被掩盖了。
问题四:碎片化的上下文
分块( Chunking )是 RAG 最无法绕开的问题。
文档被切成固定大小的片段之后,每个片段都与它的前后文脱节了。AI 拿到的是一段从报告中间截取的内容,不知道这段话在哪个章节,不知道前一段在讲什么,也不知道后续有没有结论。
最糟糕的情况是:一个关键段落恰好横跨两个 Chunk 的边界,两个 Chunk 都能匹配到,但又各自不完整。AI 拿到的两份碎片都沾了边,却都缺少关键信息,最终给出一个似是而非的回答。
这个问题业内有很多补丁办法,比如:加大 Chunk 重叠,加入父 Chunk 检索,引入 Small-to-Big 策略……每个补丁都能在某个维度上改善问题,但也都会带来新的代价——更多 Token 、更复杂的管线、更难调试的行为、更加无法通用。
我们把这些补丁叠在一起,得到了一个复杂、易出错,但仍然不够好的系统。
问题五:不同文档类型需要特殊处理
通用分块策略对不同文档类型的效果差异极大,这是我们当初没有充分预判到的。
论文有 Abstract + 正文 + References 的结构;书籍有章节层级和页眉页脚;合同有条款编号和交叉引用;代码文档有 API 列表和示例代码;表格类文档的”内容”是列名和数据类型,而不是单元格里的文字……
固定窗口切块的策略不理解这些结构,分块点往往切在语义中间,把标题和它的正文分开,把条款编号和条款内容切断,把表头和数据分离。
每种文档类型其实需要完全不同的处理逻辑。但针对每种类型都写特化的解析器和分块策略,工作量巨大,维护成本也高——而且即使都做完了,效果也只是”比通用策略好一些”,仍然是碎片化的。
问题六:Agent 使用体验极差
以上五个问题单独看,每个都还在可接受的范围内,但当 RAG 被实际接入 AI Agent 使用的时候,所有问题叠加在一起,效果非常糟糕。
一个真实的场景:AI 在帮用户分析一份合同,调用
search()检索相关条款,拿到了 10 个 Chunk 。有几个 Chunk 沾了边,但信息不完整。AI 无法判断该怎么继续,只好调整关键词重新搜索。再拿到 10 个 Chunk ,还是不够。再换关键词,再搜一次。每次搜索都是黑盒:AI 不知道换哪个关键词才能找到它需要的内容,不知道文档里到底有没有这个信息,不知道自己距离答案有多远。这种低效不是 Agent 能力不够,而是工具本身的设计不支持它做出合理的决策。
RAG 在设计上是为”用户直接提问”场景优化的,不是为”Agent 自主探索”场景设计的。
行业也在转移
这些问题不是我们独有的,业内已经有明显的应对趋势:
微软的 GraphRAG 引入知识图谱来缓解上下文碎片化问题,把相关实体和关系显式地存储下来,而不是靠碎片拼凑。
PageIndex 不按固定大小切 Chunk ,而是以页面为单位建立索引,保留文档的自然边界。
Agentic RAG 尝试让 AI 自主决定检索策略,而不是走固定管线——方向是对的,但在 RAG 架构上叠加 Agent 逻辑,复杂度随之翻倍。
最彻底的转向来自 Claude Code 和 Manus 。它们干脆放弃了 RAG ,回到最原始的方式:Glob + Grep + Read 。找文件、搜关键词、读内容。没有向量数据库,没有 Embedding 模型,没有 Chunk 管线。效果反而更好。
这让我们想明白了一件事:RAG 的设计假设是”LLM 不够聪明,需要我们帮它把信息预处理好”。这在 GPT-3.5 时代是合理的。但现在的 LLM 已经有能力自主使用工具完成多步检索任务——它们不需要预切碎片,它们需要的是线索 :文件在哪,结构是什么,然后它自己能决定读什么、读多少。
我们的解法:Outline Index
Glob + Grep + Read 对代码库很有效,但对用户文档行不通。代码库里
src/services/auth.ts这个路径本身就在告诉你这是认证服务;但2024 年度总结(修改版)(最终版).docx,路径告诉你的信息约等于零。更别提 PDF 和 Word 是二进制格式,grep 根本读不了。所以我们的问题变成了:能不能给文档也建立一套等价的”目录索引”,让 AI 用 search → outline → read 的方式渐进式地翻阅你的文件?
我们把这套方案叫做 Outline Index 。
核心思想一句话:不替 AI 预切信息,而是给它一张地图。
为每个文档建立一份结构化”名片”,包含文档的元数据(标题、作者、关键词、摘要)和结构大纲(章节标题、层级关系、行号范围)。AI 按三层路径访问文档:
- search :搜索相关文档,返回文件列表和 Metadata ,约 50 tokens/文件
- outline :查看文档的结构地图,约 200-500 tokens/文件
- read :精准读取指定章节的原文,按需加载
这与人类阅读的方式完全一致:先找书,看目录,翻到对应章节精读。AI 在这个过程中有完整的上下文,知道自己在文档的什么位置,可以决定”再多看一点”,也可以跨文档对比。
对比传统 RAG:同样的场景下,Outline Index 方式的 Token 消耗约 800-3400 ,AI 拿到有完整上下文的精确信息。传统 RAG 返回 10 个预切碎片,消耗 4000-6000 tokens ,AI 对文档结构一无所知。
另一个副产品:Embedding 的对象从原文 Chunk 变成了 Outline Index 本身。一个文档只需要一个向量。10000 个文档 ≈ 10000 个向量 ≈ 30MB 存储,检索速度也快得多。
关于领域词汇不敏感的问题,BM25 全文检索补上了这块短板。双路检索( BM25 精确匹配 + 向量语义理解),通过 RRF 融合,不再需要 Rerank 模型。
最后,是广告时间:
- Outline Index 是 Linkly AI 的核心技术。如果你对具体的实现细节感兴趣,可以阅读这篇技术文章:Outlines Index:一种渐进式披露大量文档给 AI Agent 的方法。
- 如果你想体验实际效果,请下载 Linkly AI,以及 linkly-ai-cli,接入到某个 AI 客户端中体验,实测效果远好于 RAG 。
作者: blueeon | 发布时间: 2026-03-13 06:17
4. 有新闻抓取的 skills 吗?
在 clawhub 上找了几个(find-skills 以及手动找),都不太符合需求,我的需求是:
1. 抓国内新闻热点
2. 抓到的内容可以缓存,下次抓到重复内容不处理
3. 内容是:标题/链接/总结/日期等不需要支持很多平台,因为热点新闻会在大部分平台出现。
自己部署 rsshub + 让🦞自己实现比较麻烦,因为总要调试,会浪费很多 tokens 。
所以做一回伸手党,有没有已经实现好的新闻 skills ?
作者: ethusdt | 发布时间: 2026-03-13 14:27
5. 请问 V 友们工作上一些项目中敏感信息存哪
比如项目的服务器连接信息,vpn 连接信息
我可能按项目建 md 这种没加密文档,我也看到同事很多放 txt 中
感觉不太安全,一般放密码管理器中吗
作者: zonas | 发布时间: 2026-03-13 13:18
6. 大家怎么看待国内各大厂商出来的各种云部署 OpenClaw 的活动?
如题,为什么这么推 OpenClaw 呢?是想收集个人信息吗?还是想卖云服务器呢?京东最新推出 云部署 OpenClaw 送真小龙虾虾
作者: fuxintong | 发布时间: 2026-03-13 01:53
7. 极客湾恢复更新:小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!
视频链接:
[小米笔记本 Pro 上手体验:性能表现优秀的超轻薄本!] https://www.bilibili.com/video/BV1hrcUzkELd/?share_source=copy_web&vd_source=835fa75e6a281bbf9bb9df438719f586
作者: Chicagoake | 发布时间: 2026-03-13 07:15
8. 有没有觉得,其实国内的程序员们最近几年,付费习惯培养起来了
刚入行的时候,我就从来没有遇到过身边的程序员 会付费购买效率工具的,所以我一直认为不要面向程序员做付费软件,但是这个观点,最近几年我彻底改变了。发现越来越多的国内程序员,愿意为有价值的,能提高效率的工具买单,所以,专注把产品做好就行。
作者: mcfever | 发布时间: 2026-03-13 00:29
9. Anthropic 家的模型训练与其他家差别大吗?
大家都知道 Anthropic 家的模型,尤其是 Opus 的实力,在编码的实际体验中是最强的,没有之一。即使拿 gemini3.1pro 和 gpt5.3codex 比,这俩也是比不上它一点。
除了编码,大家跑龙虾也能感觉出来差别很大,尤其是多步骤工具链的复杂任务只有 opus 能完美胜任,opus 画的 svg 动效流程图也是比新的 gemini 强很多。
我的问题是,公开互联网训练数据大家都是一样的,各家的 RL 也差不离(这点应该没什么技术壁垒),经济实力上 OpenAI/Google 应该更有优势,那为什么训练出来的大模型只有 opus 家最强?
是 Anthropic 家训练更强调代码能力,侧重点不同导致的吗?
作者: Kinnikuman | 发布时间: 2026-03-13 03:27
10. 大厂离职 gap 半年面试备受打击求外企推荐
背景:某头部大厂(B)后端开发 5 年+,B 端业务,裸辞 gap 半年,年后陆续开始面试,互联网大中厂面了个遍( 5 家),都是一面二面挂,甚至连续多次投递过不了简历关,非常焦虑。
问题:
- 想获得面试机会非常需要垂直业务经历匹配,很多岗位直接简历筛选不过。
- 基本每场面试都会具体质疑我的裸辞原因,并对我给出的理由(休息了一段时间、部门业务前景不好想换业务获得成长、gap 过程中也在学习 AI 等)均不认可(例如:怎样才能叫获得成长?为什么一定要裸辞呢? gap 这么久都干啥了?)。仿佛 gap 就该判刑。
- 复盘了下面试挂的原因,项目经历确实没有太大的亮点。
如果后续大厂的机会都没把握住,心理可能会很失衡,但是心里预期只能这样慢慢降低。 现在也想找些上海深圳的外企(能给得起薪资(快到 P6 的顶),平薪也行)投递,大家有推荐吗?谢谢。
作者: vamostu | 发布时间: 2026-03-13 14:22
11. 自从用了 Claude Code, Intellij 家族的 ide 很少打开了
自从用了 Claude Code ,Intellij 家族的 ide 很少打开了
你们用什么工具配合 ai 工具呀?
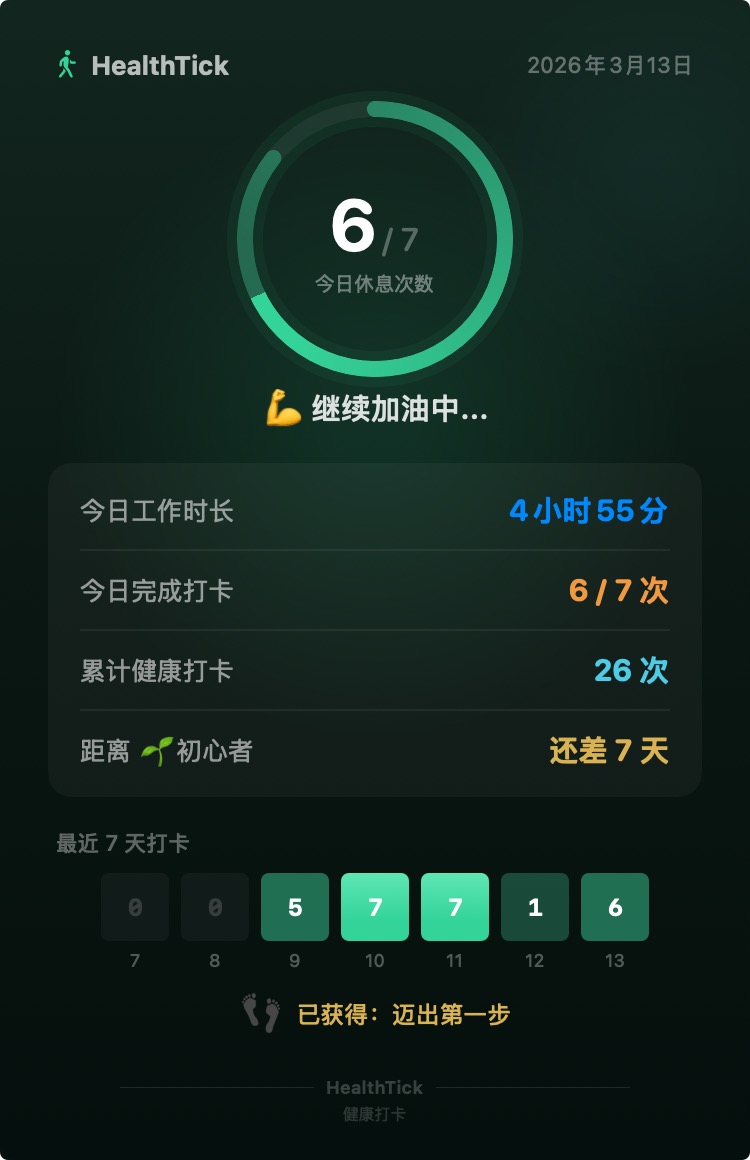
作者: gefangshuai | 发布时间: 2026-03-13 09:48
12. antigravity 5h 刷新改回来了
刚刚刷新了一下 antigravity 发现改成 5 小时刷新了,看来谷歌被骂还是听劝的
作者: LaughingCat | 发布时间: 2026-03-13 09:52
13. 这几天网速忒慢,搞的心里慌慌的
国内,没试不知道,但是翻墙,那是真的心累
大部分节点都爆红,只有那么几个节点选择
现在有工作还好,如果没有工作了,到哪里上网翻墙
作者: Rust2015 | 发布时间: 2026-03-13 09:59
14. 安卓假如放弃 root 的话,建议买哪家?
首先说一下,不买苹果。苹果没法用 mihon 、iceraven 、ublock origin 等软件,而且就算有上架的 app 相比安卓版本也会屏蔽 r18 ,比如 TG 。此外我没有 mac 也会导致很多麻烦。
安卓现在 root 是真的太难太难了,一解锁就导致特别特别多问题。我目前解锁 root 的需求其实主要就两个:
- 国产特色系统的大量广告、各种云控、安全中心、“贴心”的拦截 apk 安装、杀后台( VPN 容易挂)。这个解决办法其实除了 root ,还可以选择本身就更纯净的系统。
- 备份 app 数据(/data/data )。这个是最难以完全替代的需求,安卓这边好像国产是没有对标苹果的 e2ee 备份的吧,我对那些云很不放心。那另一个选择就是放弃手机数据,尽可能不往手机上放重要数据,都往 NAS 之类的地方塞。
注 :没有关国产流氓的需求,国产直接物理隔离。
我网上搜了下资料,好像满足 1 的国行手机,就只能在三星(可以不解锁刷港版)、摩托罗拉、努比亚/红魔里选了?有没有用过的朋友说下体验呢?三星和摩托罗拉国内的评测非常少,而且大部分面向大众的评测,基本都没有提到云控、安全中心、杀后台、GMS 完整性之类的东西,国内可能很多普通用户根本不在意广告快应用啥的。比如这个帖子 https://v2ex.com/t/1196721 ,V 友 tyzrj766 的回复:
你朋友没用酷安,酷安信息流里的广告,在 ColorOS 上调用快应用,能实现不碰不晃,刷到就一键打开,如果是小游戏直接读取你的 OPPO 账号给你实名过验证,瞬间完成。我用 X9 那会都惊了,以前用小米和 vivo ,系统里的快应用广告都没这么丧心病狂。
加上这个 B 系统,字体不统一,界面不统一,屏幕也差,月月更新只会水 AI ,目前是被我拉黑了,一加和 OPPO 手机再好,系统再德芙,这些问题不改我是不会用了。前后买了三四个黑厂手机,没一个能坚持用的下去。
这个对我是绝对无法接受的,但是 B 站大众向评测里都觉得 ColorOS 很好用,所以只能来 V2EX 这种更偏极客的论坛来请教一下了,国行安卓里哪个系统对于极客来说体验更好?三星刷港版、摩托罗拉、努比亚/红魔的体验怎么样?
作者: LaTero | 发布时间: 2026-03-13 08:36
15. 想直接购买 CC 的 api key,不想通过中转,没有大美丽信用卡做不到?
如何合法途径通过国内支付,有经验的进来聊聊啊
作者: mrsbryant | 发布时间: 2026-03-12 00:55
16. 订阅 GPT Plus 后能在 Claude Code 中使用 Codex 吗?
如题,另外请问下,使用国内招行的信用卡在网页端支付的话,会不会被 ban 呀?谢谢大家!
作者: z1s23 | 发布时间: 2026-03-13 11:49
17. 为什么 iPhone 上看抖音, macbook dock 上会弹出来 chrome 图标,点开是抖音?
这是什么黑科技啊?


作者: 14night | 发布时间: 2026-03-13 10:12
18. [流氓微信] 婚礼纪、婚贝这种电子请柬会留下记录,并且授权之后无法取消
今天才知道在微信打开婚礼纪、婚贝这种电子请柬会留下访客痕迹。发布者开会员就能看到你的昵称、头像及浏览记录。
微信访问链接的时候是会给对方一个唯一标识吗?查了一下会携带一个微信账号+开发者平台组合的 OpenID 。印象中很早之前是没有(是否隐身)这个选项的,但是发布者却能看到记录,所以这个是默认获取的?只要授权一次,那么以后对方数据库里,微信昵称头像就和这个 OpenID 绑定了。并且个人在对应平台的 OpenID 无法重置!除非你更换微信账号。
当前点进去的话,确实会有一个授权提示,如果选择隐身访问,对方就看不到,只会看到用户 xx (随机 id)访问了我的请柬。
可是这个授权没有调用微信的授权,只在小程序/h5 侧就能做到,所以理论上对方不经过你的同意拿到你的头像 id 你也不知道;并且这个授权也在微信的授权历史里看不到,所以这个是不用经过微信允许的假授权。
如果在婚礼纪、婚贝他们的网站上上注销呢?我尝试了发现,先注册再注销账户,再点进去链接,依然没有提示授权。说明,只要授权一次,这个 openid 和用户名头像的映射一直存在他们数据库了。
那么微信这个流氓为啥会给一个网站送上 OpenID 呢?而且是终身不变的 ID ,跟可重置的广告 ID 还不一样。
目前看没啥好办法,能做的就是,少用微信,屏蔽朋友圈,少打开这种链接。
作者: LaurelHarmon | 发布时间: 2026-03-13 06:00
19. 关于知识库搭建
大家好,想请教一下大家都是怎么搭建个人知识库的。我这边有不少本地文件(主要是论文)。虽然现在像 Perplexity 这样的 AI 工具有很强的搜索能力,但我还是希望能搭建一个既能自定义联网资源,又能利用本地数据的知识库。目前在用 Notion ,不过每次都要手动粘贴内容挺麻烦的。像 NotebookLM 这种工具对上传文件数量有限制,所以暂时不考虑。我刚买了一台 512G 的 mini ,更倾向于搭建本地知识库。
作者: elliszkn | 发布时间: 2026-03-13 04:30
20. Antigravity 有 GeminiPro 的账号也变成 5 天冷却了?
之前 opus4.6 一直都是 5 小时的冷却时间啊,今天打开看突然变成 5D+了
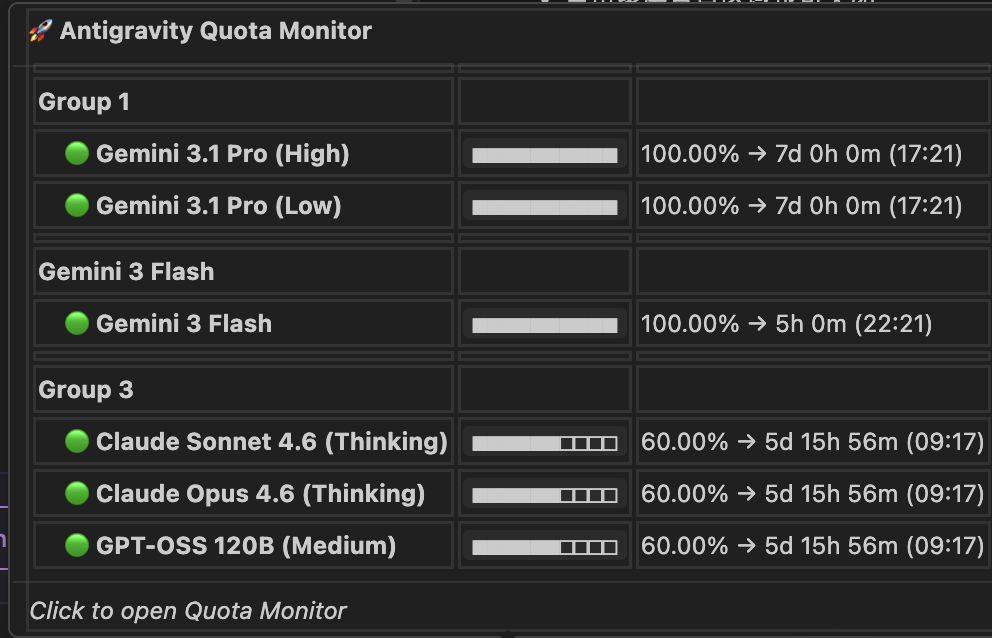
作者: lp4298707 | 发布时间: 2026-03-12 09:27
21. OpenCode 出了个 Go 套餐就是 10 刀 Coding Plan,值得买吗?
OpenCode 出的 Go 套餐,首月 5 刀续费 10 刀,也是按照 5 小时、每周、每月的限额,不过它是按照不同模型的成本计算,5 小时 12 刀额度,不同模型 1M token 的输入输出和缓存价格都不同。
不知道这个价格比起国内的 Coding Plan 有没有什么优势,因为我现在有字节的和智谱的 Coding Plan ,这一周都用得太难受了。字节的用 auto 模型勉强能用,指定模型非常的慢。智谱这周用 4.7 模型都直接弹限流了。
想想要不要直接换一个海外的服务商,毕竟 10 刀现在约等于 70 一个月,也贵不了多少
作者: samnya | 发布时间: 2026-03-13 07:36
22. Linux 服务器上有多个 ip,程序本身不能指定接口,有第三方程序可以强制让程序使用指定接口吗?
像 libbind 、proxychains 、部分 tsocks 这类基于 LD_PRELOAD 劫持 libc 的办法,不适合 golang 编写的程序
有比较便捷的解决方案吗?
作者: pc10201 | 发布时间: 2026-03-13 02:30
23. Chroniq - 给 AI Agent 工作流设计的 CLI 日志工具,轻量开源
最近把自己平时记录碎片上下文的小工具整理成了一个开源 CLI ,叫 Chroniq ,现在已经发到 npm 了。
它不做知识库、不做同步、不做 GUI ,只做一件事:
把零散上下文快速收进一个稳定、可导出、对 Agent 友好的输入层。
几个特点:
- 本地优先
- CLI 优先
- 追加式 JSONL 存储
- 输出既适合人读,也适合脚本和 AI 消费
适合这类场景:
- 在终端里随手记一条想法
- 记录项目决策、命令输出、临时观察
- 把当天上下文直接导给 AI 工作流
痛点
我的日常工作流重度依赖 AI Agent ( Claude Code 、Codex 等)。每天需要快速记录碎片想法,然后导出给 AI 做分析和总结。
现有笔记工具的问题:
- 输入太重 — 需要打开 GUI 、选分类、填字段
- 导出太封闭 — 数据锁在 app 里,喂给 AI 很麻烦
- 不 CLI-first — 和终端工作流格格不入
解法
Chroniq 只做两件事:快速记录 + JSON 导出。
# 3 秒记完 cq add "讨论了 CLI 输入设计 #idea" # 直接喂给 AI cq today --json | your-ai-tool # 批量输入(打开编辑器) cq add # 导出所有 cq export --format json 数据格式是本地 JSONL ,每天一个文件,追加写入,不修改不删除。欢迎贡献
已经自用一段时间,核心流程稳定。开源出来想和大家一起验证:Agent 时代的个人工具最小必要形态是什么?
特别欢迎:
- 使用场景和痛点反馈( Issue )
- 核心流程优化( PR )
- 和你自己的 Agent 工作流对接的经验
GitHub: https://github.com/Hazel-Lin/chroniq
想听听大家对“agent-native context capture”这个方向的反馈。
作者: hazellin549 | 发布时间: 2026-03-13 10:14
24. 从智谱 agent 发现了个 skills 文件夹,不知道是不是内部的 skills,大家来看看
扒下来的整个流程很简单:智谱的 Agent 模式本身运行在云主机上,我们可以让它输出当前的文件结构。通过查看结构,你会发现一个名为 skills 的文件夹。只需让 Agent 将该文件夹打包,然后下载即可。贴一段 skills 描述
┌─────────────────────────────────────────────┐
│ 硬件配置详情 │
├─────────────────────────────────────────────┤
│ CPU: Intel Xeon Processor (4 核) │
│ 内存: 8 GB │
│ 磁盘: ~10 GB │
│ 系统: Linux (Alibaba Cloud Linux) │
│ 运行时: Bun │
│ 端口: 3000 │
└─────────────────────────────────────────────┘


作者: qaq13037 | 发布时间: 2026-03-13 02:59
25. 我的 chrome 更新后无法通过代理访问网页
之前在 V2EX 上看到有人说 chrome 的新功能,我就想着我的 chrome 挺久没更新了,结果一更新后我就无法访问外网的网站了,我以为是我的代理出现了问题(经常内外网切换)结果我打开本地的开发环境发现没办法访问本地的地址,我开始怀疑是否是项目有问题,重启项目后,排查相关链路发现是通的,打开 Firefox ,edge 后又一切正常了,外网页面也能访问,我突然意识到我的代理没有问题,是 chrome 出现了问题,我跟随网上教程及 ai 的指导也没有修复这个问题,只能暂时使用 Firefox 顶替了,有同样问题的大佬吗
作者: elishuhu | 发布时间: 2026-03-13 02:33
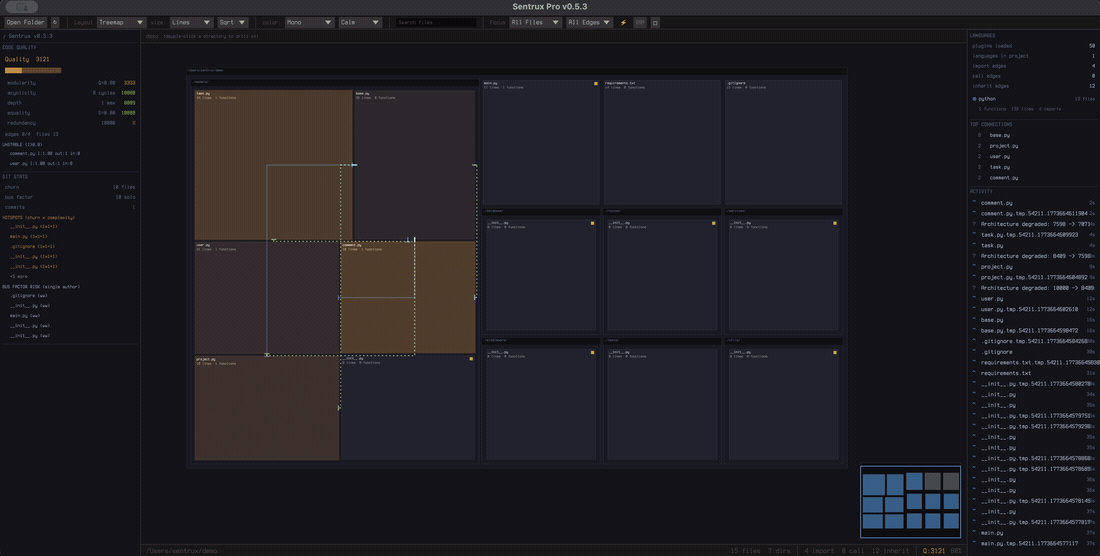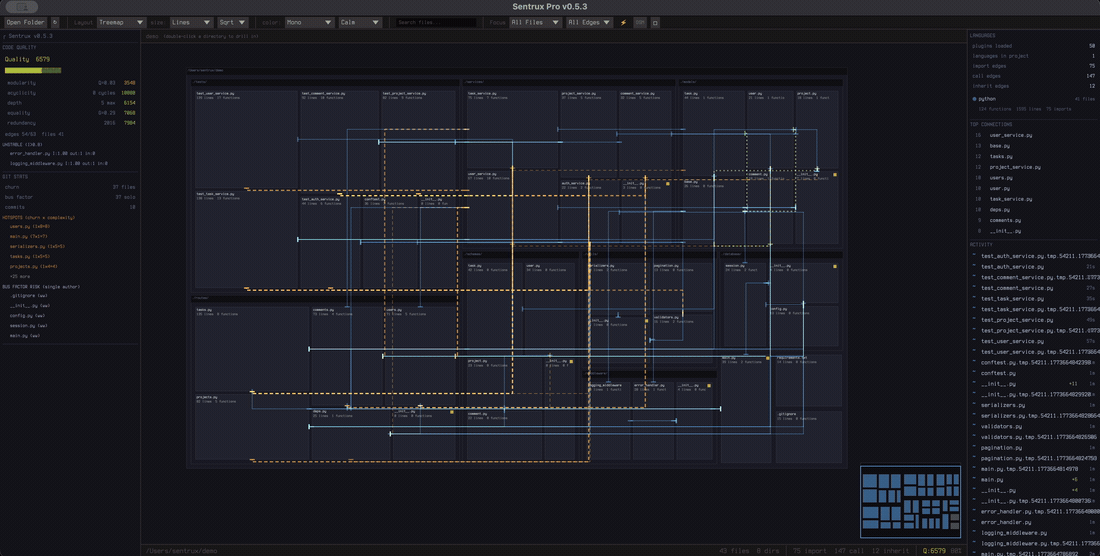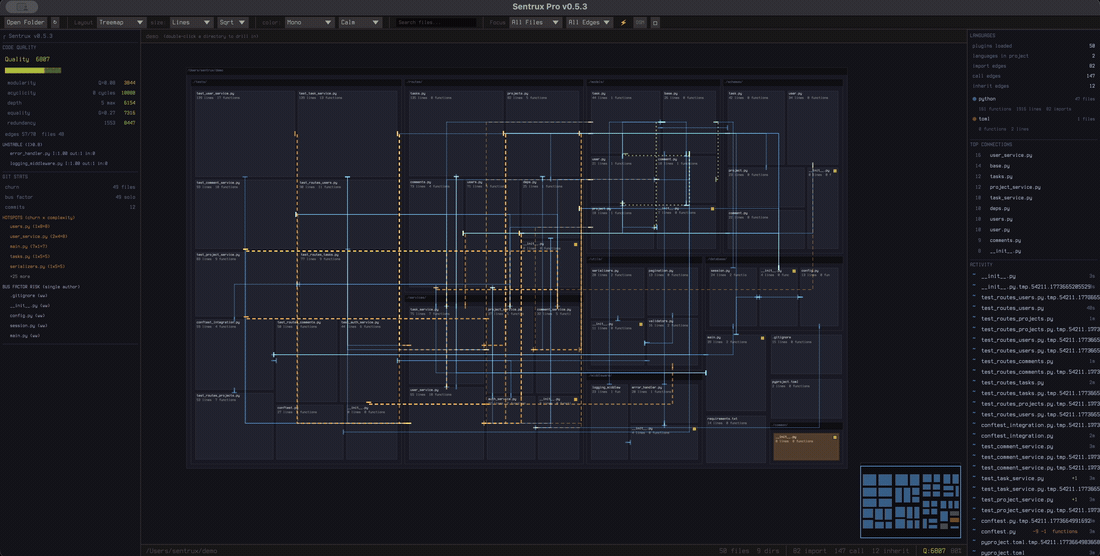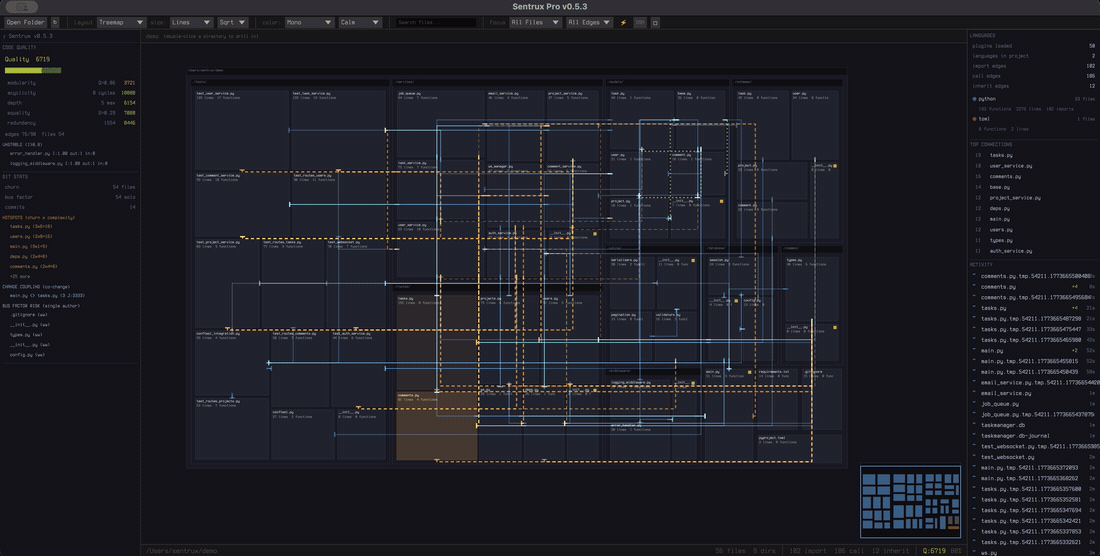
26. 随着 AI 写代码的复杂度越来越高,项目越来越难以推动和理解,这个反 speckit 工具可以解决这个问题
最近用 claude code 或者别的 ai agent 写代码,写了几个月,发现了里面一些问题,
https://raw.githubusercontent.com/sentrux/sentrux/main/assets/demo.gif
总是有种感觉就是和 ai 一起推进一个项目,和 ai 一起讨论,各种方案研究,一起推进,推着推着就退不动了,要么就是觉得 ai 莫名的越来越笨,
- 要么就是 ai 调用工具比如检索查看一些文件或者信息的时候似乎越来越不准,效率越来越低
- 要么就是 ai 写一些测试的时候,测试的越来越不准,
- 或者说要 ai 修 bug ,他说修好了,可是问题还在,这样的现象随着我们的项目越来越大以后就越来越明显
所以导致大到一定程度,积累了很多的技术债,导致很难继续,或者改变。
在 AI 之前的时代,我们打开 IDE ,每一行代码、每一个文件、每一个引用、每一个函数都是我们自己写的。当出现 bug 的时候,我们非常清楚问题在哪,可以快速地去调试,很有掌控感。
但在 AI 时代,我们在终端或 AI Agent 上,只能看到它以机器的速度快速修改各种文件。我们只能看到具体改了哪些文件的名字,以及非常局部的改动内容,这使我们失去了对整个代码的大局观。
很多人在整个用 AI Web Coding 的生命周期里,甚至从始至终都没有看过文件夹下面的内容:
- 它到底创造了什么?
- 它们之间的关系是什么?
- 整体结构是什么?
我们对此一无所知,只能盲目地相信 AI 做的事情。那么当出现 bug 的时候,我们更加无能为力,只能继续依赖 AI 去找 bug 、查 bug 、改 bug 。这也是目前的痛点之一。
在信息学的理论里面有熵增定律。由于我们目前的 AI 属于生成式 AI ,AI 写的代码是生成式代码,这就不可避免地会从原理上让我们——如果只依赖于 AI 的话——会让我们的代码结构变得更加冗余和复杂。
目前整个行业很有可能是在以一个错误的方式去解决这个问题。
在一些很火的开源项目(比如 GitHub 出品的 SpecKit )中,这类工具非常依赖于开发者在项目开始前,就彻彻底底想好整个代码结构、要实现的功能以及具体内容。
但真正在 AI Coding 的时候,我们的做法其实恰恰相反。在自然的情况下,我们使用 AI 写代码更倾向于一种“交谈启发式”的流程:
- 我们并不会提前规划好所有细节,而是从零开始,让 AI 快速生成原型。
- 像甲方和乙方一样,在交互中不断修改方案。
- 同时进行一些深刻的探讨,启发我们想到更好的产品方案或技术路线。
在这样的循环推进方式下,AI 不可避免地会生成一些架构很乱的“脏代码”。最终在一轮又一轮的 Prompt 之后,它确实可能给出一个外在功能完美的运行结果,但内部架构可能是极其混乱的。
正是因为架构的混乱,会导致开篇那样让人抓狂的东西,很多致命的情况: (a) 当 AI 调用工具指令搜索函数时,可能会找到好几个函数名相同但实现形式或算法不同的结果。 (b) 当 AI 修复 Bug 时,它以为修好了一处,但由于架构混乱,它实际修掉的可能是别的地方。
俗话说,好的体系让坏人也可以做好事,坏的体系可以让好人也变成坏人。这就意味着,在一个好的架构下,即便水平稍低一些的 AI 都可以写出高质量的代码。
所以,架构是非常重要的。
所以这个 repo 可以 同时帮助人做以上两个事情,可以理解为可视化文件系统,以及给 AI 一个传感器,就是架构传感器,帮助 ai 自我循环加速写好的代码。
这样可以理解为这个 project 是反向的 speckit ,
无论你用什么自然的方式开始 vibe coding , 都可以在 sentrux 的帮助下,最后弄出来很好,很高水准的代码,
纯 rust 高性能
https://github.com/sentrux/sentrux
作者: yisen123 | 发布时间: 2026-03-13 04:45
27. Claude Code 抽风了,疯狂压缩,各位遇到过这种问题没有?
大概是 12 号晚上 10 点以后开始出现问题。
我是重度用户,两个 Max 200$ 的账号基本够用,大概从昨天晚上开始 CC 应该是升级了一次。
我用的是 Cursor + Claude Code 插件,其实就跟 VSCode 差不多。
以前触发 Compacting, 会生成一大段文本,然后继续,这次升级以后行为变了,会变成输出一行
Compacted chat auto 168k tokens freed
之类 的,给一个提示,然后继续。问题是很快,大概运行几个 Bash Grep ,Read lines 之类的工具之后就会再次触发
Compacted chat auto 177k tokens freed
就从这个历史来看,很难相信几个不到 20 行的读取就能占用 100 多 k 的 token ,接下来 CC 大概没几步就要 Compacted 一次。而同样粒度的任务,以前可以顺畅的跑完,不触发 compact ,或者仅仅触发一次。
很明显就能看出来是有问题的,使用 /context 查看可以确定确实是 Messages 占用了 80%以上的 Token ,但是不知道里面是什么,开 debug 模式也得不到任何信息。
尝试回滚 stable 版本,CC Cli, VSCode, 甚至 Web 版本都有同样的问题。也尝试了重新安装,卸载所有 SKILLS, MCP 之类的也没有帮助。
昨天看 X 有人说 CC 把默认的 Effort 调成 Medium 了也是够鸡贼的,但是尝试 effort high 或者 effort max 也仍然不解决问题。
不知道大家有没有遇到?现在非常不爽,只能又暂时用回 Cursor 了。
作者: chengchengst | 发布时间: 2026-03-13 08:17
28. HarmonyOS.skills
链接: https://github.com/linhay/harmony-next.skills
HarmonyOS NEXT 开发者专家技能包 (Reference Skill)
harmony-next.skills是为 AI 编程助手(如 Gemini CLI, Claude Code, Codex )设计的参考技能库。 它为 HarmonyOS NEXT (API 12+) 提供本地化的离线知识源,包含超过 3,403 份涵盖 ArkTS 、ArkUI 和 NDK 的 Markdown 格式参考文档。核心特性 (v1.0.4+)
除了详尽的 API 参考外,本项目现已包含以下专家级实战指南 :
- 🛠 IDE 实操 :应用签名、断点调试、模拟器与真机配置全流程。
- 📈 性能调优 :深入使用 DevEco Profiler 进行 CPU 、内存、帧率及启动耗时分析。
- 🏗 架构设计 :HAP/HAR/HSP 包结构深度解析、Stage 模型并发机制与 Actor 模型。
- 🧪 自动化测试 :基于 Hypium 的单元测试与 UI 测试,以及 CI/CD 命令行集成。
- 🤖 命令行工具 :
hdc、ohpm、hvigorw及emulator完整命令手册。快速开始
用户集成指南
Gemini CLI
gemini skills install https://github.com/linhay/harmony-next.skills --path harmony-next --scope userClaude Code
- 从本仓库下载技能文件夹。
- 根据需要进行压缩。
- 在 Claude.ai 的
Settings > Capabilities > Skills中上传。- 或者直接将其放置在你的 Claude Code 技能目录中。
如果你只想将其作为项目上下文添加:
git clone https://github.com/linhay/harmony-next.skills.git claude --add-dir /path/to/harmony-next.skills/harmony-next包含内容
harmony-next/references/: 3,403 份 Markdown 文档 (约 50 MB)。harmony-next/[SKILL.md](http://SKILL): 助手的检索规则与回答策略。harmony-next.skill: 由 GitHub Actions 自动生成的打包发布产物。为什么需要它?
- 消除幻觉 :提供 HarmonyOS 5.0+ 真实 API 实现指导。
- 确定性回复 :为 Agent 工作流提供可寻址的文件参考。
- 离线支持 :在无网或受限环境下依然可以使用完整的 API 手册。
作者: linhey | 发布时间: 2026-03-13 09:01
29. 开源项目: clawOS 解决 openclaw 文件系统,一键安装
linux 或者 mac 系统( windows 可以安装,部分功能用不了)
一键安装
pip install clawos clawos start clawos status (查看运行密码和端口) 然后打开: http://127.0.0.1:6002/(或者你自己的 IP 域名)仓库(详细介绍见仓库,有截图)
功能列表
- 支持 openclaw,nanobot,picoclaw 安装配置
- 文件系统管理
- git 仓库管理(自动识别 git 仓库)
- systemd 管理
- 支持网页中打开终端
- 一个好用的数据库管理器(支持自然语言生成 SQL )
- 磁盘,显卡,进程,CRON 管理
基本相当于操作系统,功能持续增强中
作者: mrytsr | 发布时间: 2026-03-13 08:55
30. 超级天才程序员回归! Antigravity 的 claude 模型变成 5h 刷新了!
gemini 3 pro 没恢复 但是没想到 claude4.6 给变成了 5h 刷新
Google 到底怎么回事?

作者: xiaowoli | 发布时间: 2026-03-13 05:53
31. [开源] OpenLegs:给那些觉得小龙虾“两只钳子”不够用的朋友们准备了 88 条腿
最近看全网都在给各种 AI Agent 疯狂打 Call ,尤其是那只小龙虾( OpenClaw )。
于是,我写了个 OpenLegs (小蜈蚣),没什么生产力,主打一个好玩。
这个小东西是怎么运作的:
- 真·随机大脑 :它没有集成什么大模型,里面跑的就是纯随机数。既然很多人分不清 AI 幻觉和真实逻辑,那我觉得随机数反而更诚实——它至少不骗你它懂。
- 只跑路,不接管 :小龙虾想要你的控制权,小蜈蚣只想带你跑路。它没有任何系统权限需求,因为我的 88 条腿觉得把钥匙交给一个刚出生的脚本,真的不稳。
- 专门治愈“Agent 焦虑” :很多人觉得 Agent 动起来世界就美好了,但说实话,自动化地产生废话,只会让信息垃圾堆得更快。
这项目没什么大志向,就是想给这股 AI 狂热火上浇油。与其说它是个工具,不如说它是个智商提醒插件 。
作者: kaliawngV2 | 发布时间: 2026-03-13 03:49
32. 寻找有谷歌商店在架的社交类 app 以及开发者账号,重酬!
如题,寻找有谷歌商店在架的社交类 app 以及开发者账号,重酬!,有需要出售的可以联系我!
作者: gdouhhq | 发布时间: 2026-03-13 08:18
33. 独立开发者们,很想问个问题,你们是专注做一款产品,还是批量生产?
作者: mcfever | 发布时间: 2026-03-12 02:48
34. 做了一个 discord-cli :把 discord 变成可本地检索、可供 AI Agent 使用的数据层
[分享] discord-cli — 把 Discord 聊天记录同步到本地 SQLite ,终端搜索 + AI 总结
项目背景
平时泡不少 Discord 社区( crypto 、开源项目、AI 讨论组),消息量大、翻找困难。Discord 自带搜索不支持正则,也没法离线查看。于是写了 discord-cli ——一个 local-first 的 Discord 命令行工具:
- 把频道消息增量同步到本地 SQLite
- 终端里全文检索、统计、导出
- 可选接 Claude 做频道摘要 / 分析
GitHub: https://github.com/jackwener/discord-cli
PyPI: https://pypi.org/project/kabi-discord-cli/
核心功能
1. 一键同步聊天记录
# 提取并保存本地 Discord token discord auth --save # 发现所有可见文字频道并同步 discord dc sync-all -n 500 # 增量同步(只拉新消息) discord dc sync-all
- 自动处理 Discord rate limit (读
retry_after/X-RateLimit-Remainingheader ,不会触发封号)- 消息存入
~/Library/Application Support/discord-cli/messages.db2. 本地搜索 & 统计
# 全文搜索 discord search "rust" -c general # 今天的消息 discord today # 按小时统计活跃度 discord timeline --by hour # 谁发言最多 discord top --hours 24 # 各频道消息量 discord stats3. 结构化输出,方便脚本 / AI Agent
# JSON / YAML 输出 discord search "release" --json discord today -c general --yaml # 导出为文件 discord export general -f json -o out.json
- 非 TTY 环境自动输出 YAML
- 所有输出遵循统一的 envelope schema
4. AI 总结 & 分析(可选)
# 安装 AI 依赖 uv tool install 'kabi-discord-cli[ai]' export ANTHROPIC_API_KEY=... # 频道 AI 分析 discord analyze general --hours 24 # 全局摘要 discord summary --hours 12安装
# 推荐 uv tool install kabi-discord-cli # 或 pipx pipx install kabi-discord-cliPython 3.10+ 即可,依赖很少( httpx + click + rich + PyYAML )。
典型使用场景
- 信息归档 :把重要 Discord 社区的讨论同步到本地,不怕频道被删或服务器跑路
- 快速检索 :在终端快速搜索历史消息,比 Discord 自带搜索灵活
- 每日摘要 :用
discord summary生成 AI 摘要,快速了解今天社区讨论了什么- 数据分析 :
timeline/top/stats了解社区活跃度- AI Agent 集成 :附带 SKILL.md ,可以被 Claude Code / Antigravity 等 AI agent 直接调用
同系列工具
这是我做的社交平台 CLI 系列的一部分,同样的 local-first 思路:
工具 平台 GitHub twitter-cli Twitter/X https://github.com/jackwener/twitter-cli bilibili-cli 哔哩哔哩 https://github.com/jackwener/bilibili-cli xiaohongshu-cli 小红书 https://github.com/jackwener/xiaohongshu-cli tg-cli Telegram https://github.com/jackwener/tg-cli
Apache-2.0 开源,欢迎 Star ⭐ 和反馈 🙏
有什么想法或者需要支持的功能,欢迎在 Issues 里提。
作者: jakevin | 发布时间: 2026-03-13 07:40
35. Trellis v0.4.0-beta 测试 ing
beta 版本主要是对之前的 py 脚本进行大幅重构(重构代码质量,对使用侧来说无影响,只是更方便大家魔改),并且原生支持 monorepo
下载
npm install -g @mindfoldhq/trellis@beta --registry=https://registry.npmjs.org
作者: fmfsaisai | 发布时间: 2026-03-13 01:33
36. 安装 Claude Code 后无法配置第三方 API
使用
irm <https://claude.ai/install.ps1> | iex安装后,在~/.bashrc配置 APIexport ANTHROPIC_BASE_URL="https://api.poe.com" export ANTHROPIC_AUTH_TOKEN="$POE_API_KEY" export ANTHROPIC_API_KEY="" # Important: Must be explicitly empty但是启动 Claude Code 后只能 3 个选项
Claude Code can be used with your Claude subscription or billed based on API usage through your Console account. Select login method: 1. Claude account with subscription · Pro, Max, Team, or Enterprise 2. Anthropic Console account · API usage billing > 3. 3rd-party platform · Amazon Bedrock, Microsoft Foundry, or Vertex AI选 1 ,2 需要登录 Anthropic
选 3 后
Using 3rd-party platforms Claude Code supports Amazon Bedrock, Microsoft Foundry, and Vertex AI. Set the required environment variables, then restart Claude Code. If you are part of an enterprise organization, contact your administrator for setup instructions. Documentation: · Amazon Bedrock: https://code.claude.com/docs/en/amazon-bedrock · Microsoft Foundry: https://code.claude.com/docs/en/microsoft-foundry · Vertex AI: https://code.claude.com/docs/en/google-vertex-ai Press Enter to go back to login options.Claude Code v2.1.74
作者: commoccoom | 发布时间: 2026-03-13 02:11
37. 各位友友有没有遇到 JetBrains Codex 不能代理的情况
目前走的自建代理,暂不考虑使用 Clash 等,目前使用的 Gost 与服务器连接。Windows 上安装 ProxyBridge 。 规则:
Codex.exe; codex.exe; codex-x86_64-pc-windows-msvc.exe; codex-acp-x64-windows.exe; codex-command-runner.exe; codex-windows-sandbox-setup.exeTCP+UDP ,任意目标/端口走代理。打开 JetBrains CLion ,使用 JetBrains AI 插件,连接 Codex ,无法登录(随后 Windows 网络设置里开启代理可以登录),发送消息一直重连。ProxyBridge 中可以看到
codex-x86_64-pc-windows-msvc.exe有走代理连接。
作者: LeviMarvin | 发布时间: 2026-03-13 04:58
38. 咨询 skill 使用中文英文区别大吗
受前两天 v 友启发,在常用开发流程中写一些自用 skill ,虽然英文能读懂,但是过几天忘了重新读,拿眼扫起来慢啊。
作者: JYii | 发布时间: 2026-03-13 01:21
39. 新手机到手就把 AI 所有的功能都关了
倒不是说不好用,只是国内厂商什么德行懂得都懂,你用了 AI 功能就给出了所有的隐私,太膈应
作者: seers | 发布时间: 2026-03-12 15:07
40. 前端去学习 golang 跨度成本大吗?
多年 web 前端,熟练使用 Ai 工具等。现在因一些工作上的可选择因素想尝试学习 go ,之前没有什么服务端开发经验,会点 nodejs ,就是这样。 如果要学 go ,在 ai 工具(codeX+antigravity)的协助下,学习成本大吗?大概多久能上手啊?有没有大佬有一个 go 学习的方向和思路传授一下。
作者: mumuwen | 发布时间: 2026-03-12 09:15
41. 文本加密工具“与熊论道”算法已被成功逆向破解
文本加密工具“熊曰加密”(与熊论道)已被通过已知明文攻击( KPA ) 完全破解。
与熊论道加密网站因故于 2025 年上旬下线,由于其加密算法不开源,导致大量既有密文无法解密。
经过逆向分析,其并未采用任何高级加密算法,主要基于 Base91 编码算法,字符替换,外加压缩和混淆处理,具体请见 PoC 。
此次逆向工作解除了该工具在加密时对中心化服务端的依赖,为早期使用该加密算法生成的历史数据提供了一种长期可用的解密与归档途径。
萌研社 2020 年更新以来加密出的所有熊曰密文现已允许被解密 。
此为魔曰项目的原创逆向研究,原创发布。
Poc 代码 / 详细解释 / 快速解密 参见
https://github.com/SheepChef/Abracadabra/issues/123
作者: SheepChef | 发布时间: 2026-03-12 14:27
42. 微信 4.x 之后 macOS 上第一个实现 hook 收发消息的开源项目(据我所知)
https://github.com/yincongcyincong/weixin-macos
因为自己对微信 hook 一直有需求,需要拦截所有订阅的银行消费提醒实现自动记账,以及各类群消息汇总、Omnifocus 之类的任务管理,所以对微信 4.x 之后在 mac 上的 hook 比较关注,之前问过 mac 上面微信的 hook 情况 https://www.v2ex.com/t/1180863
帖子里有人提到这个项目,试了一下确实实现了 hook 收发,我在 4.1.7.31 上面测试成功。、
征得作者的同意把项目在这里发一下,有需要的可以关注一波,也可以添加电报群 https://t.me/+yBnP4fxkoCIzZjRl 不过作者也说了,会只专注微信基本的收发功能,主要用于接入 agent 使用,其它各类群控之类的功能一概不碰。
作者: f1ynnv2 | 发布时间: 2026-03-13 03:01
43. 天塌了, 连豆包都不能匿名问问题了
以前国内 ai 我只用豆包, 只有一个原因, 就是因为不需要登录
今天一试, 居然也要登录了
算了以后还是用 gpt 或 gemini 把
作者: iorilu | 发布时间: 2026-03-13 01:54
44. 有没有复杂问题和抽象问题强推理能力的模型
目前 coding 已经高强度使用 codex 了,但是发现做规划、方案、复杂问题尤其是抽象问题的推理上,gpt 太保守了,循规蹈矩的。 claude 目前看是推理能力比较强,但是额度太少了,4.6 动不动就干空了,20x 又开不起。 这个场景下,有没有接近 claude 的平替? glm5 浅浅试了下,没经过大量验证不好说。 v 友们有比较适合这种场景的平替模型厂家么? 出于隐私安全,不考虑中转。
作者: zzNaLOGIC | 发布时间: 2026-03-13 01:23
45. 小米这个域名是用来检测代理的吗 device-proxy.sec.xiaomi.com
观察到有时候会解析到 127.0.0.1,有时候会解析到正常 IP ,这种有时候正常,有时候不正常的解析目的是什么
最近几次的解析记录
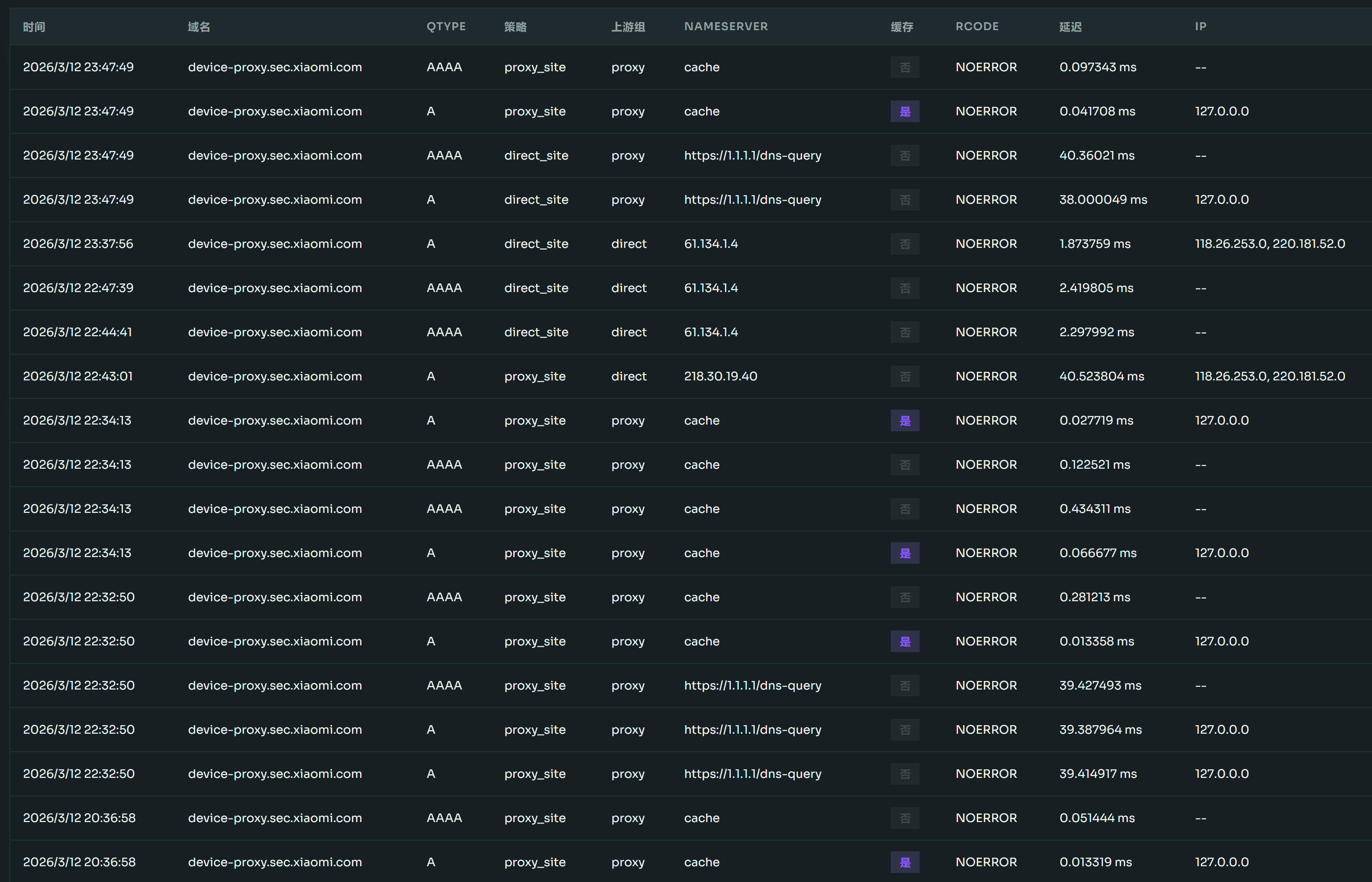
我不用小米手机,应该是 IOT 设备发出的

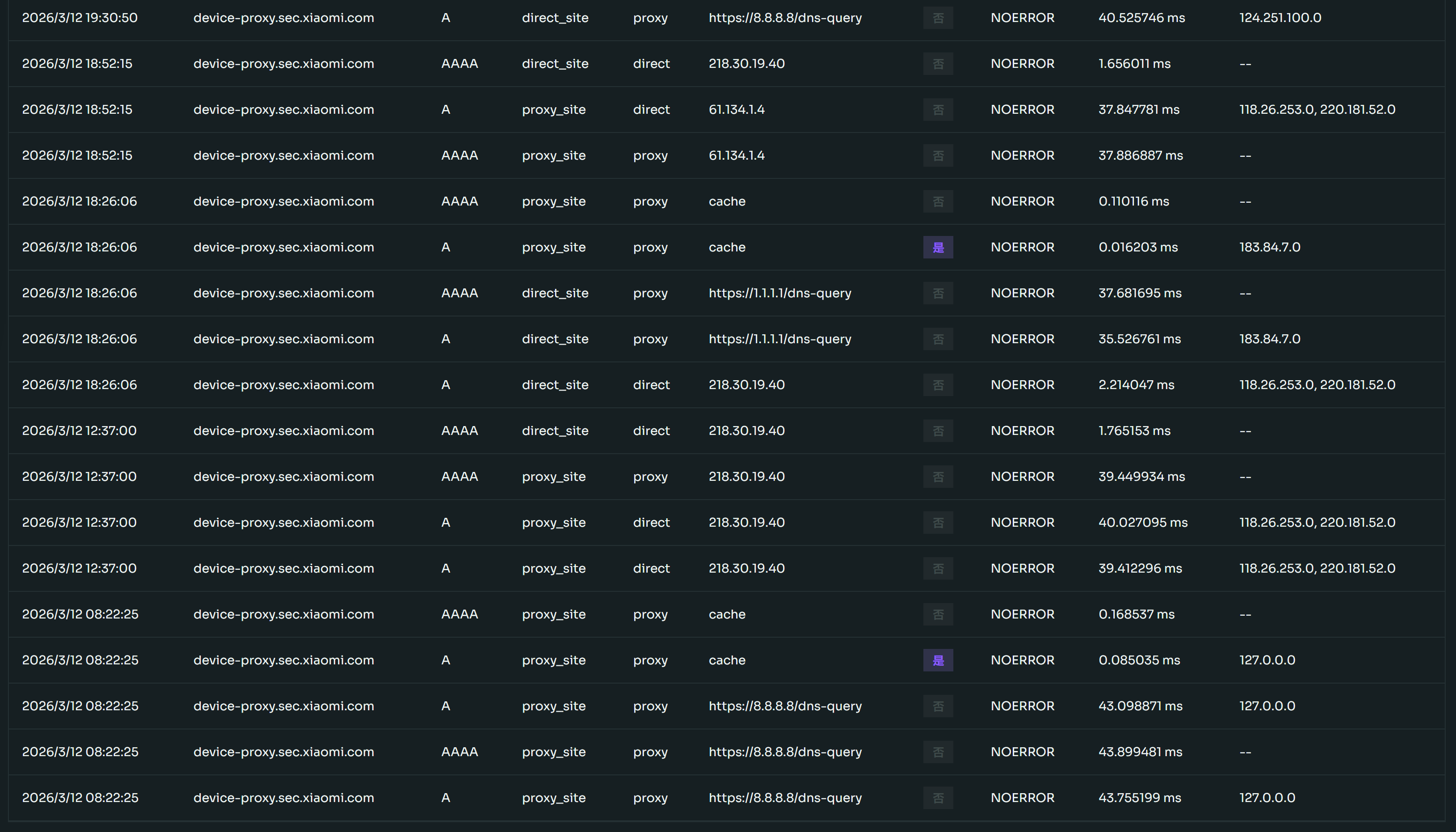
作者: lnbiuc | 发布时间: 2026-03-12 16:35
46. 规模 30 人左右的开发团队,计划采购 Coding Team 套餐,且限定仅采购国内的相关套餐。不知各位是否有相关经验?
以前大家都是各自为战,自行承担 AI 费用。现在领导打算统一采购。有没有大佬有相关经验,推荐一下采购套餐,以及分享如何实施的经验呢?
作者: Newbee24 | 发布时间: 2026-03-12 01:48
47. opencode 下, deepseek 有时候比较蠢
使用工具是 opencode ,使用模型是官方的 deepseek-chat
我的问题是,这个 windows 上 go 语言环境设置成了 linux arm64 。然后 opencode 写项目时编译报错,让 deepseek 顺手改掉,结果 deepseek 表现很拉跨,半天搞不定这个任务

换成 opencode 自带的 Big Pickle ,很快就解决了问题

可能术业有专攻吧
作者: nativeBoy | 发布时间: 2026-03-12 02:39
48. 看看这个 AI 设计稿导出代码(React/Vue/ Swift …)的还原度咋样?
用 OpenPencil 随便一句话生成了一个美食 APP 首页,设计感不错的!提示词高手应该能发挥得更好。

最近上了 AI Enhance to Code 之后,可以说打通了最后一百米。直出 8 种前端/客户端代码,运行无报错,还原度可以说相当高了。(我怎么觉得有些比设计稿对的还要齐呢[doge])。

最后要强调的是支持导出 Vue ,可以说太符合国情了,好的 Design to Code 工具支持 Vue 的几乎没有啊😭。
总之对设计师、前端、后端、全栈的小伙伴来说,都是个神器!

作者: finiking | 发布时间: 2026-03-12 14:01
49. sweep 要关了,难受。有和它一样好用的补全插件吗?不想用基于 vscode 的 cursor
To our Sweep community,
After careful consideration, we have made the difficult decision to shut down Sweep. We are incredibly grateful to each of you for your support and for being part of this journey — it has truly meant a lot to us.
Here’s what you need to know:
Servers go offline: April 9th
New subscriptions: Disabled as of today
We decided to shut down because autocomplete usage is declining industry-wide as agents have become significantly better. Competing in the agent space has also been an uphill battle against foundation model labs with far greater resources — such as heavily subsidized plans like Claude Code Max.
That said, we’re not walking away without leaving something behind for the community:
We’ll release a locally running version for both agent and autocomplete.
We’ll also open-source our latest production 7B autocomplete model and low-latency runtime.
As for us, we’ll be joining Datacurve AI, and we wanted to bring you along for what comes next.
An Opportunity for Talented Engineers
Datacurve AI is YC backed and works with top foundation model labs to produce high-quality training datasets.
They currently have many concurrent software engineering projects and are actively looking for talented engineers to start ASAP. Top contributors have earned $80–$200+ USD per hour.
They’re recruiting fast and applications close soon you can apply through the form below and they’ll be in touch:
https://hello.datacurve.ai/project-application
If you have any questions about any of the above, please don’t hesitate to reach out via our support channels. Thank you for everything — it’s been an honor building with this community.
With gratitude,
The Sweep Team
作者: odokei | 发布时间: 2026-03-12 12:31
50. 逆天,刚冲的 Google Pro 账户,用了反重力两天就不能用了
刚刚用两天,还没站起来蹬,就直接一周后重置,太无语了


{kind=link}
作者: TheBlind | 发布时间: 2026-03-11 06:36