阅读提示:TL;DR。文章包含大量源码,阅读时长较长,认真阅读可能超过20分钟。
回想一下,Spring最最核心的功能,终究是一个容器,用于提供所谓的”Bean“,并负责Bean之间的联结。而我们又知道,Bean有不同的Scope,即作用范围,单例的、原型的、Session的,或自定义的。Bean还能够懒加载。因此,创建Bean的时机可能是运行时的任何时候。Spring使用BeanDefinition描述一个Bean的name、类、scope等元数据,并在需要时候创建。创建过程自然也包括了自动注入的过程。
本文我们重点关注Spring中对Bean的管理。
如何描述Bean
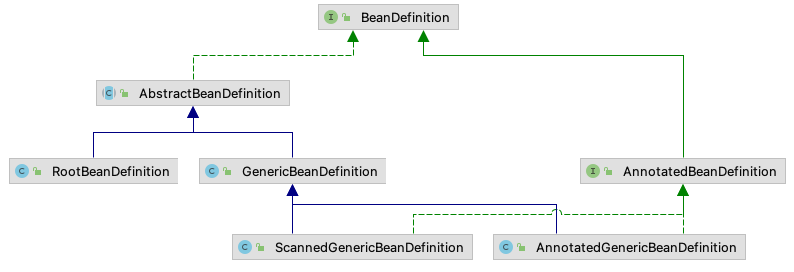
Spring使用BeanDefinition来描述Bean,其继承拓扑图如上,我们只选取了几个具有代表性的来看。根绝BeanDefinition接口的定义,能够知道,Spring中的Bean具有如下特性:
- 基本信息
- 名字
- 描述
- 用于创建该Bean的Class对象
- 具有作用范围Scope
- singleton:全局唯一实例
- prototype:每次获取都创建新的实例
- 可以有父子关系
- 可以有依赖关系,即一个Bean的创建依赖于另一个Bean的存在
- 可延迟加载
- 可自动装配
- 设置是否参与自动装配(基于类型)
- 如果有多个类型符合要求,可设置主要的
- 可自定义Bean实例创建方式
- 设置工厂Bean,用另一个Bean来创建该Bean
- 设置工厂方法,用该方法创建实例
- 生命周期管理
- 可指定初始化方法
initMethod - 可指定销毁方法
destroyMethod
- 可指定初始化方法
- 具有角色,目前定义了三种角色,但暂未看到如何使用
ROLE_APPLICATION:该Bean是应用的主体,默认值ROLE_SUPPORT:标识该Bean是其它更大部分的支持部分ROLE_INFRASTRUCTURE:该Bean作为纯基础设施的支持,用户接触不到它
- 获取构造方法的参数的值
- 获取
MutablePropertyValues,这对应的是Bean的属性键值对,自动注入时会使用。 BeanDefinition可包装另一个BeanDefinition,通过BeanDefinition getOriginatingBeanDefinition()获取被包装的定义。
至于继承树中其它类,各自有所区别,我们依次看
AbstractBeanDefinition
BeanDefinition的直接实现,从中也可以看到一些特性的默认值
scope默认为单例- 延迟加载默认关闭
- 自动注入默认关闭
- 角色默认为
ROLE_APPLICATION
RootBeanDefinition
说实话直接看这个类时,有点懵,原注释这么说。
A root bean definition represents the merged bean definition that backs a specific bean in a Spring BeanFactory at runtime. It might have been created from multiple original bean definitions that inherit from each other, typically registered as GenericBeanDefinitions. A root bean definition is essentially the ‘unified’ bean definition view at runtime.
Root bean definitions may also be used for registering individual bean definitions in the configuration phase. However, since Spring 2.5, the preferred way to register bean definitions programmatically is the GenericBeanDefinition class. GenericBeanDefinition has the advantage that it allows to dynamically define parent dependencies, not ‘hard-coding’ the role as a root bean definition.
我看懂了字面意思,却没看懂这串英文背后的含义。什么是MergedBean,关于这点,可以参考这篇文章,所谓合并,就是将具有父子关系的BeanDefinition合并为一个BeanDefinition。”合并“的具体过程,下文”如何创建Bean“将会分析。
GenericBeanDefinition
BeanDefinition的标准实现,相较于AbstractBeanDefinition,它多了对父子关系的实现。我们是可以直接用该类创建自己的BeanDefinition的。如果我们要凭空创建一个BeanDefinition注入容器,可以用它。
AnnotatedBeanDefinition
BeanDefinition的直接扩展接口,向调用者暴露了AnnotationMetadata。那么问题来了,什么是AnnotationMetadata呢?它是Spring为指定类的注解所定义的抽象,通过它可以不加载目标类即可获取到注解信息。类似的还有ClassMetadata。看来,Spring是将Bean定义的方方面面都进行了抽象。
AnnotatedGenericBeanDefinition
同时实现了GenericBeanDefinition和AnnotatedBeanDefinition,表明它既具有一个完整BeanDefinition的能力,又持有Bean原类上的注解信息。持有注解信息有什么用呢?当然有用,运行时可以直接获取Bean定义的注解而不加载原类呀,提升性能。
ScannedGenericBeanDefinition
和AnnotatedGenericBeanDefinition一样,可以说是一模一样。
小结
Spring关于Bean的描述,其实不止这几个类,但我认为其它都是干扰,因此去掉了。我们的重点,是要通过这些定义看到Spring是如何进行抽象的,以及各级抽象的作用。写代码时不会用到,但它可保看源码时不会懵逼。
Bean定义从何而来
还是上一篇文章那个例子,一个最最简单的应用方式。
1 | fun main() { |
我们以org.springframework.context.annotation.AnnotationConfigApplicationContext构造方法为入口,分析Bean定义加载的过程。
1 | public AnnotationConfigApplicationContext(String... basePackages) { |
这里引入两个新的类:AnnotatedBeanDefinitionReader和ClassPathBeanDefinitionScanner,我们先看它们的能力,再看这个扫描的过程
AnnotatedBeanDefinitionReader
1 | public class AnnotatedBeanDefinitionReader { |
要点总结
AnnotatedBeanDefinitionReader,封装了BeanDefinition构建并注入BeanDefinitionRegistry的流程,这里BeanDefinitionRegistry就是我们的容器BeanDefinitionRegistry,在前面介绍ApplicationContext就已经介绍过,用于接收并持有Bean定义- bean名称生成器:
AnnotationBeanNameGenerator,按照@Component及其子注解、@ManagedBean、@Named生成,详细分析见下 Scope元信息,包含了Scope的作用范围、代理模式,通过@Scope注解标识,AnnotationScopeMetadataResolver就是解析@Scope注解的。如果未指定@Scope注解,得到的结果是:单例+不代理。ConditionEvaluator,条件解析器。针对@Conditional进行解析。详细分析见下文。
bean名称生成逻辑
AnnotationBeanNameGenerator这个类值得看一看,它有一些隐藏的功能
1 | public class AnnotationBeanNameGenerator implements BeanNameGenerator { |
要点
- 支持生成Bean名称的注解有:
@Component及其子注解、@MangedBean、@Named - 如果这些注解没有显式指明名称,则回退成默认规则:类名首字母小写
判定BeanDefinition是否需要被加载
ConditionEvaluator这个类也值得一看,它解释了@Conditional注解的工作原理。整个类就暴露一个方法:shouldSkip()
1 | public boolean shouldSkip( AnnotatedTypeMetadata metadata, ConfigurationPhase phase) { |
分析一下ConfigurationClassUtils.isConfigurationCandidate()
1 | private static final Set<String> candidateIndicators = new HashSet<>(8); |
理解关键
AnnotatedTypeMetadata要理解,前面AnnotatedBeanDefinition看到过,Spring将Bean上的注解信息和类信息进行了抽象,使得不需要加载具体的类就能获取其上的注解,使用方便。Condition条件,它只有一个匹配方法boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata),用于匹配指定Bean在容器中是否满足条件,我们常用的@ConditionalOnClassMissingBean之类的注解,就是@Conditional派生注解+Condition派生类组合完成的。
要点总结
ConditionEvaluator是用来判断某个Bean定义是否符合加载条件,是加载还是有应该被忽略。判断逻辑- 如果不存在
@Conditional注解,则需要加载 - 如果存在
@Conditional注解,则需要看该注解的作用阶段和其内部Condition的行为- 如果
Condition所指定的阶段与@Conditional实际作用的阶段不一致,则需要加载 - 否则,根据
Condition.matches()的结果来判定是否需要加载
- 如果
- 如果不存在
- 当一个Bean定义被
@Component、@ComponentScan、@Import、@ImportResource注解,或其内含有@Bean注解方法时,说明它是一个配置Bean。即作用阶段是ConfigurationPhase.PARSE_CONFIGURATION,否则,作用阶段是ConfigurationPhase.REGISTER_BEAN,作用阶段,也可以用来判断是否需要加载该Bean定义:当声明的作用阶段和Condition类的作用阶段不一致时,将忽略匹配过程,直接加载
ClassPathBeanDefinitionScanner
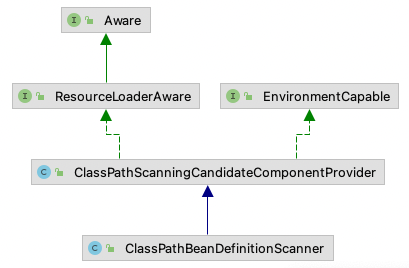
继承树如上
ClassPathScanningCandidateComponentProvider用于在指定包下扫描并提供Bean定义(所谓的CandidateComponent),核心逻辑在public Set<BeanDefinition> findCandidateComponents(String basePackage)方法。ClassPathBeanDefinitionScanner用于批量扫描包下的Bean定义,核心逻辑在protected Set<BeanDefinitionHolder> doScan(String... basePackages)方法。
我们按照调用关系来看,从scan方法看起
1 | public int scan(String... basePackages) { |
上面有调用到ClassPathScanningCandidateComponentProvider的findCandidateComponents方法,我们再看
1 | public Set<BeanDefinition> findCandidateComponents(String basePackage) { |
上面只贴出了直接从类中扫描的代码,但另一个addCandidateComponentsFromIndex没说。我们需要先知道一下Spring中的Index是什么。可以参考这篇文章:
在项目中使用了
@Indexed之后,编译打包的时候会在项目中自动生成META-INT/spring.components文件。 当Spring应用上下文执行ComponentScan扫描时,META-INT/spring.components将会被CandidateComponentsIndexLoader读取并加载,转换为CandidateComponentsIndex对象,这样的话@ComponentScan不在扫描指定的package,而是读取CandidateComponentsIndex对象,从而达到提升性能的目的。
此时我们再去跟踪addCandidateComponentsFromIndex()方法,会发现和上面说的可以说是一模一样了。
要点总结
可以看到,
ClassPathBeanDefinitionScanner做的事和AnnotatedBeanDefinitionReader差不多,都是构建BeanDefinition并向容器中注册;唯一的差别是,前者的Bean定义是自己扫描得来的,而后者的Bean定义是外界调用方法注册来的通过
ClassPathScanningCandidateComponentProvider.findCandidateComponents()我们知道,它只提供最原始的扫描并生成BeanDefinition的逻辑,而BeanDefinition各种属性的解析和设置放在其子类ClassPathBeanDefinitionScanner中了。
小结
这一个Reader,一个Scanner,都只是一个工具,最终完成了容器中的BeanDefinition创建。
如何创建Bean
Bean的创建逻辑
Bean的创建有几个时机
- 对于非延迟加载的单例Bean,在容器refresh时就会被创建,在
ApplicationContext源码分析时我们看到过 - 对于延迟加载的单例Bean,在第一次被获取时会被创建
- 对于原型Bean,每次被获取时都会被创建
我们先看第一种情况,直接进org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons,我删掉了不重要的代码。
1 | public void preInstantiateSingletons() throws BeansException { |
上面虽然只是预加载单例Bean的代码,但方法doGetBean()却是获取Bean的通用方法,对此,可以有所总结:
- 单例Bean的创建, 先从缓存中获取;如果没有,再从父容器中获取,如果再没有,则执行创建逻辑
- 如果一个Bean有依赖的Bean,则该依赖Bean将会首先被创建;如果被依赖的Bean又依赖了原Bean,则构成循环依赖,Spring将会抛出异常
- scope的实现只有三种情况
- 单例:当
BeanDefinition的scope没有值(即默认单例)或为singleton时,为单例,整个容器只维护一份实例 - 原型:当
BeanDefinition的scope为prototye时,为原型,每次都会执行一遍新建Bean的逻辑 - 其它:当
BeanDefinition的scope非上述任何一种时,为其它,实现方式是容器维护一个名为scopes的Map,每个entry的值为Scope对象,它就是一个容器,新建的Bean会放入该容器。构成对同一个Scope只存在一份Bean。
- 单例:当
- 创建完成的Bean实例,并不能直接使用:如果有指定预期的类型,还要调用容器内维护的类型转换器进行一次类型转换,得到最终值
对于正常情况下的Bean获取方法如org.springframework.context.support.AbstractApplicationContext#getBean(java.lang.String),有如下
1 | public Object getBean(String name) throws BeansException { |
可以看到它又是调用了doGetBean(),还是那个通用方法,这里略过不记。
MergedBeanDefinition
先说明,没有这个类或接口定义,但是前文”如何描述Bean“提到了合并Bean定义的概念,”Bean的创建逻辑“又再次看到了这个概念,它到底什么意思?我们从org.springframework.beans.factory.support.AbstractBeanFactory#getMergedLocalBeanDefinition方法来看
1 | protected RootBeanDefinition getMergedLocalBeanDefinition(String beanName) throws BeansException { |
关键是父Bean定义被子Bean定义覆盖,看org.springframework.beans.factory.support.AbstractBeanDefinition#overrideFrom
1 | // 不过你看,貌似也没什么不同,就正常的Bean定义的属性呀 |
要点总结:所谓合并,就是有父子关系的BeanDefinition的合并,将他们合并为一个BeanDefinition,合并逻辑是:用子BeanDefinition覆盖父BeanDefinition,最终结果用RootBeanDefinition表示。
自动注入
自动注入这块的代码实在太多,这里分成几个部分分别来说
到现在为止,我们还没看到自动注入,BeanPostProcessor等的执行逻辑,它们都在org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object[])中,前文创建Bean的源码有调用它
1 | protected Object createBean(String beanName, RootBeanDefinition mbd, Object[] args) throws BeanCreationException { |
- 这里唯一需要注意的点:可以通过
InstantiationAwareBeanPostProcessor提供一个代理实例,这为Spy之类的测试功能提供了方便,使得他们可以伪造bean,构建测试环境。
创建实例前的操作
对resolveBeforeInstantiation,有
1 | protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) { |
- 注意点同上
创建实例操作总览
对创建的实际操作,有
1 | protected Object doCreateBean(String beanName, RootBeanDefinition mbd, Object[] args) throws BeanCreationException { |
- 注意点1:创建Bean的步骤:创建、执行注入、执行初始化操作
- 注意点2:循环引用的解决方式
循环引用的解决方式
需要注意的是,这里有两种循环引用的方式
Scope为单例时,则如”创建实例操作总览“中的代码那样,确切来说,应该这么梳理首先,Spring维护三个有关单例缓存
singletonObjects:用于维护已经创建好的单例对象earlySingletonObjects:用于维护创建了但尚未执行自动注入和初始化的单例对象singletonFactories:用于维护单例对象产生的工厂实例
然后来看注入的具体方法,比如按照name注入,它还是调用了
getBean方法获取Bean,其中会调用getSingleton方法获取实例对象- 先从
singletonObjects中获取已经创建好的单例对象 - 再尝试从
earlySingletonObjects中获取创建到一般的单例对象 - 再尝试用对应的
singletonFactories创建出一个单例对象,注意该对象会加入earlySingletonObjects,所以其实为了理解方便,singletonFactories您可以暂时忽略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 已经简化成这样
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
return singletonObject;
}然后再看创建Bean时干了什么(截取前文的代码):增加了一个
singletonFactory,结合前面的分析,其实就是把刚创建但还没有注入属性和初始化的bean放在了earlySingletonObjects中,使得如果有循环依赖时能够直接获取到该bean。避免死循环。1
2
3
4if (earlySingletonExposure) {
// getEarlyBeanReference方法,其实就是直接将传入的bean传回来了
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}总结来说,这里的重点是将bean的创建和初始化(包括注入)分开进行,保有一个半初始化的状态,使得能够注入半初始化状态的Bean。
但是,这是setter注入时才可以这么做,构造器注入又当如何呢?事实上,因为构造器注入时,当前对象尚未创建完成,没法有一个半初始化状态,因此构造器注入不允许循环依赖。
Scope为原型时,参考AbstractBeanFactory.doCreate.273行,这里有检查当前线程下同名的原型Bean是否正在创建。Spring是一个同步框架,在创建原型Bean时,同一个线程不可能同时创建两个原型Bean,那么很明显了,就如注释所说,这里是不允许原型Bean循环引用。1
2
3
4
5// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}为什么原型时不支持循环依赖?因为Spring不会缓存任何有关原型的状态,虽然它也能有中间状态,但Spring并不缓存它,这是一个技术上可以实现,但Spring的设计思想上不允许存在的场景:所谓原型,每次获取Bean都要创建一个新的,那么当循环依赖时,应该获得的是一个与”我“完全不同的Bean。
BeanWrapper是什么
该类不是给我们直接使用的,而是在容器内部流通。用于提供实际Bean实例的分析和操作,如针对属性的操作、查询等。它常用的只有一个实现类BeanWrapperImpl。了解它有助于源码的查看,这里我们简要看一下接口定义
1 | public interface BeanWrapper extends ConfigurablePropertyAccessor { |
创建实例的确切操作
1 | protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) { |
- 创建备选方式的顺序
- 提前设置的
Supplier - 指定的工厂方法
- 使用
BeanDefinition提前解析好的构造器创建 - 使用
SmartInstantiationAwareBeanPostProcessor提供的构造器创建 - 使用类自带的有参构造器创建,参数来自容器,自动注入
- 使用类自带的无参构造器创建
- 提前设置的
按有参构造器注入并创建
1 | public BeanWrapper autowireConstructor(String beanName, RootBeanDefinition mbd, Constructor<?>[] chosenCtors, Object[] explicitArgs) { |
- Spring会先从容器中找出满足类型要求的参数组合,然后找出与这些参数类型最为匹配的构造器,用以创建实例
- 可以想见,只要有精确类型的bean被创建,就一定能够实例化成功,因为不可能有完全一样参数类型的构造器嘛
使用无参构造器创建
1 | protected BeanWrapper instantiateBean(String beanName, RootBeanDefinition mbd) { |
自动注入逻辑的执行
对自动注入的逻辑,即populateBean(),有
1 | // 执行Bean注入 |
实例初始化的操作
对初始化的逻辑有
1 | // 初始化Bean |
- 实例化包含内容
BeanxxxAware接口的调用BeanPostProcessor.postProcessBeforeInitialization的调用InitializingBean.afterPropertiesSet的调用- 自定义初始化方法的调用
BeanPostProcessor.postProcessAfterInitialization的调用
根据依赖类型得到依赖实例的操作
在执行自动注入逻辑时,有用到如下方法,我们一起来看看它干了什么:org.springframework.beans.factory.config.AutowireCapableBeanFactory#resolveDependency(org.springframework.beans.factory.config.DependencyDescriptor, java.lang.String, java.util.Set<java.lang.String>, org.springframework.beans.TypeConverter)
1 | javaxInjectProviderClass = ClassUtils.forName("javax.inject.Provider", DefaultListableBeanFactory.class.getClassLoader()); |
小结
Bean的创建,可说是重中之重,因为它关系到Spring的生命周期,这是面试中超高频率被问到的问题。有了上面的分析,我们可以自己总结一波创建过程会经过哪些关键过程,这其实有两种case
case1
- 首先执行
InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()提供一个创建代理的机会,如果代理创建成功 - 执行所有的
BeanPostProcessor.postProcessAfterInitialization()方法 - 对于预加载的单例Bean,还会调用
SmartInitializingSingleton.afterSingletonsInstantiated() - 结束
case2
- 实例化Bean
- 尝试使用指定的工厂方法创建
- 尝试使用构造方法创建,如果使用有参构造方法,构造方法的参数会被自动注入
- 应用
InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation() - 对需要的属性进行自动注入,按名称或类型从容器中寻找符合要求的Bean,注入
- 调用
BeanNameAware、BeanClassLoaderAware、BeanFactoryAware - 应用
BeanPostProcessor.postProcessBeforeInitialization() - 应用
InitializingBean.afterPropertiesSet() - 应用自定义init方法
- 应用
BeanPostProcessor.postProcessAfterInitialization - 对于预加载的单例Bean,还会调用
SmartInitializingSingleton.afterSingletonsInstantiated() - 结束
注意这里讨论的是Spring中Bean的生命周期,而不是Spring的生命周期,如果是后者,请翻看第一篇文章分析。
如何销毁Bean
JVM中的对象,通过可达性分析,垃圾回收机制,进行回收;Spring中的Bean对象,总是被容器持有,岂不是永远不可能被垃圾回收?这个想法是正确的,这种设计也是合理的。但要注意到有一个前提:Scope,正因为有它的存在,Bean的生命周期管理才变得方便。
- 对于
Scope为单例的Bean,容器全局唯一,被容器引用,当然不会也不能被销毁 - 对于
Scope为原型的Bean,创建完成后容器内部并没有引用,交给应用程序,这和普通new出来的对象一致,是能够被回收的 - 对于
Scope为其它的Bean,则看Scope而定,Scope销毁,Bean对象一并被回收,这种情况没见过;要不然就交给Scope自己处理了,这倒是见过,比如web里面的Request或Session范围的Scope,它是将Bean对象保存在HttpServletRequest或HttpSession中,即生命周期随请求或Session的销毁而结束。
我们关注两个点:随容器一起销毁的Bean如何销毁;生命周期不跟随容器的Bean如何销毁
被容器销毁
容器的销毁方法
1 | protected void doClose() { |
可以看到,容器关闭时,只销毁了单例Bean,调用了两个有关生命周期的方法
LifyCycle.close()DisposableBean.destroy()
但还有一种Bean的销毁回调没有被我们看到:自定义销毁方法的调用
被JVM销毁
正如注解方法org.springframework.context.annotation.Bean#destroyMethod上的注释而言,只有生命周期被容器完全控制的Bean才能正常被容器调用各种销毁方法,也就是单例,其它Scope都无法保证。因此类似原型、上面说的Session之类的生命周期方法,都是不能被正常调用的,因为容器管不了他们呀。
Note: Only invoked on beans whose lifecycle is under the full control of the factory, which is always the case for singletons but not guaranteed for any other scope.
总结
这文章写了三天你能信???
总结一下,本文从源码的角度,介绍了Spring如何描述Bean,如何在容器创建时扫描Bean,在不同的时机如何创建Bean,Bean的循环依赖的解决方式,自动注入的逻辑,不同Scope的Bean的销毁场景等问题。但已就算是走马观花,不过今后遇到问题时应该很快能够定位问题吧🤔。
命名规则
- xxxxProvider:Provider算是策略模式+抽象工厂模式的结合。所谓抽象工厂模式,意味着它封装了创建实例的过程;所谓策略模式,意味着它可以被当做策略传入其它以他为基础的类中。比如
ClassPathScanningCandidateComponentProvider之于AnnotationConfigApplicationContext。
下一篇写什么
Spring源码剖析 - 强大的BeanPostProcessor